 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunked Lists versus Extensible Arrays for Text Inversion
Aug 29, 2023In our 2017 work on in-memory list-based text inversion [Hawking and Billerbeck. Efficient In-Memory, List-Based Text Inversion. ADCS 2017] we compared memory use and indexing speed of a considerable number of variants of chunked linked lists. In the present work we compare the best performing of those variants (FBB - dynamic Fibonacci chunking) with the extensible SQ array technique (SQA) presented in [Moffat and Mackenzie. Immediate-Access Indexing Using Space-Efficient Extensible Arrays. ADCS 2023].
Incorporating Query Term Independence Assumption for Efficient Retrieval and Ranking using Deep Neural Networks
Jul 08, 2019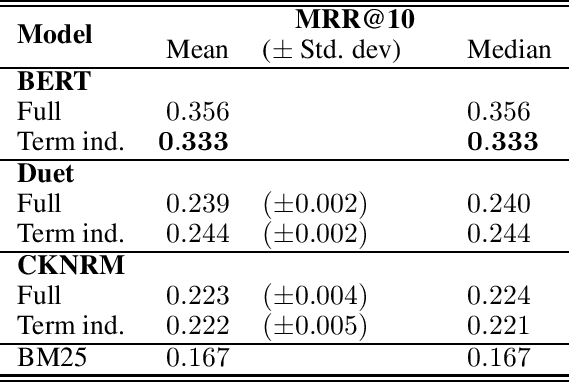

Classical information retrieval (IR) methods, such as query likelihood and BM25, score documents independently w.r.t. each query term, and then accumulate the scores. Assuming query term independence allows precomputing term-document scores using these models---which can be combined with specialized data structures, such as inverted index, for efficient retrieval. Deep neural IR models, in contrast, compare the whole query to the document and are, therefore, typically employed only for late stage re-ranking. We incorporate query term independence assumption into three state-of-the-art neural IR models: BERT, Duet, and CKNRM---and evaluate their performance on a passage ranking task. Surprisingly, we observe no significant loss in result quality for Duet and CKNRM---and a small degradation in the case of BERT. However, by operating on each query term independently, these otherwise computationally intensive models become amenable to offline precomputation---dramatically reducing the cost of query evaluations employing state-of-the-art neural ranking models. This strategy makes it practical to use deep models for retrieval from large collections---and not restrict their usage to late stage re-ranking.