 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolBiX: Detecting LLMs' Political Bias in Fact-Checking through X-phemisms
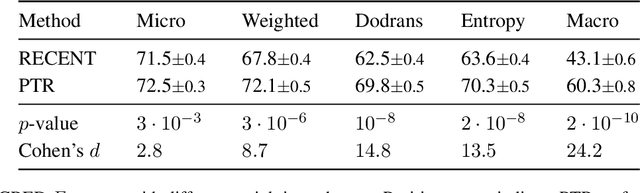
Sep 18, 2025Large Language Models are increasingly used in applications requiring objective assessment, which could be compromised by political bias. Many studies found preferences for left-leaning positions in LLMs, but downstream effects on tasks like fact-checking remain underexplored. In this study, we systematically investigate political bias through exchanging words with euphemisms or dysphemisms in German claims. We construct minimal pairs of factually equivalent claims that differ in political connotation, to assess the consistency of LLMs in classifying them as true or false. We evaluate six LLMs and find that, more than political leaning, the presence of judgmental words significantly influences truthfulness assessment. While a few models show tendencies of political bias, this is not mitigated by explicitly calling for objectivism in prompts.
Reverse Probing: Evaluating Knowledge Transfer via Finetuned Task Embeddings for Coreference Resolution
Jan 31, 2025



In this work, we reimagine classical probing to evaluate knowledge transfer from simple source to more complex target tasks. Instead of probing frozen representations from a complex source task on diverse simple target probing tasks (as usually done in probing), we explore the effectiveness of embeddings from multiple simple source tasks on a single target task. We select coreference resolution, a linguistically complex problem requiring contextual understanding, as focus target task, and test the usefulness of embeddings from comparably simpler tasks tasks such as paraphrase detection, named entity recognition, and relation extraction. Through systematic experiments, we evaluate the impact of individual and combined task embeddings. Our findings reveal that task embeddings vary significantly in utility for coreference resolution, with semantic similarity tasks (e.g., paraphrase detection) proving most beneficial. Additionally, representations from intermediate layers of fine-tuned models often outperform those from final layers. Combining embeddings from multiple tasks consistently improves performance, with attention-based aggregation yielding substantial gains. These insights shed light on relationships between task-specific representations and their adaptability to complex downstream tasks, encouraging further exploration of embedding-level task transfer.
Evaluating the Robustness of Adverse Drug Event Classification Models Using Templates
Jul 02, 2024



An adverse drug effect (ADE) is any harmful event resulting from medical drug treatment. Despite their importance, ADEs are often under-reported in official channels. Some research has therefore turned to detecting discussions of ADEs in social media. Impressive results have been achieved in various attempts to detect ADEs. In a high-stakes domain such as medicine, however, an in-depth evaluation of a model's abilities is crucial. We address the issue of thorough performance evaluation in English-language ADE detection with hand-crafted templates for four capabilities: Temporal order, negation, sentiment, and beneficial effect. We find that models with similar performance on held-out test sets have varying results on these capabilities.
Multilingual Relation Classification via Efficient and Effective Prompting
Oct 26, 2022



Prompting pre-trained language models has achieved impressive performance on various NLP tasks, especially in low data regimes. Despite the success of prompting in monolingual settings, applying prompt-based methods in multilingual scenarios has been limited to a narrow set of tasks, due to the high cost of handcrafting multilingual prompts. In this paper, we present the first work on prompt-based multilingual relation classification (RC), by introducing an efficient and effective method that constructs prompts from relation triples and involves only minimal translation for the class labels. We evaluate its performance in fully supervised, few-shot and zero-shot scenarios, and analyze its effectiveness across 14 languages, prompt variants, and English-task training in cross-lingual settings. We find that in both fully supervised and few-shot scenarios, our prompt method beats competitive baselines: fine-tuning XLM-R_EM and null prompts. It also outperforms the random baseline by a large margin in zero-shot experiments. Our method requires little in-language knowledge and can be used as a strong baseline for similar multilingual classification tasks.
Why only Micro-F1? Class Weighting of Measures for Relation Classification
May 19, 2022

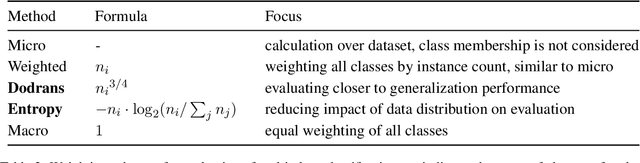
Relation classification models are conventionally evaluated using only a single measure, e.g., micro-F1, macro-F1 or AUC. In this work, we analyze weighting schemes, such as micro and macro, for imbalanced datasets. We introduce a framework for weighting schemes, where existing schemes are extremes, and two new intermediate schemes. We show that reporting results of different weighting schemes better highlights strengths and weaknesses of a model.
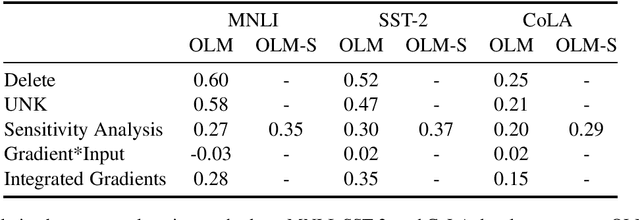
Explaining Natural Language Processing Classifiers with Occlusion and Language Modeling
Jan 28, 2021

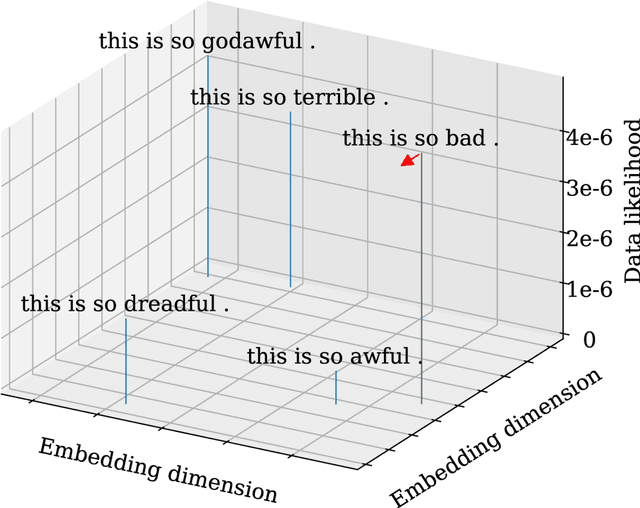

Deep neural networks are powerful statistical learners. However, their predictions do not come with an explanation of their process. To analyze these models, explanation methods are being developed. We present a novel explanation method, called OLM, for natural language processing classifiers. This method combines occlusion and language modeling, which are techniques central to explainability and NLP, respectively. OLM gives explanations that are theoretically sound and easy to understand. We make several contributions to the theory of explanation methods. Axioms for explanation methods are an interesting theoretical concept to explore their basics and deduce methods. We introduce a new axiom, give its intuition and show it contradicts another existing axiom. Additionally, we point out theoretical difficulties of existing gradient-based and some occlusion-based explanation methods in natural language processing. We provide an extensive argument why evaluation of explanation methods is difficult. We compare OLM to other explanation methods and underline its uniqueness experimentally. Finally, we investigate corner cases of OLM and discuss its validity and possible improvements.
Considering Likelihood in NLP Classification Explanations with Occlusion and Language Modeling
Apr 21, 2020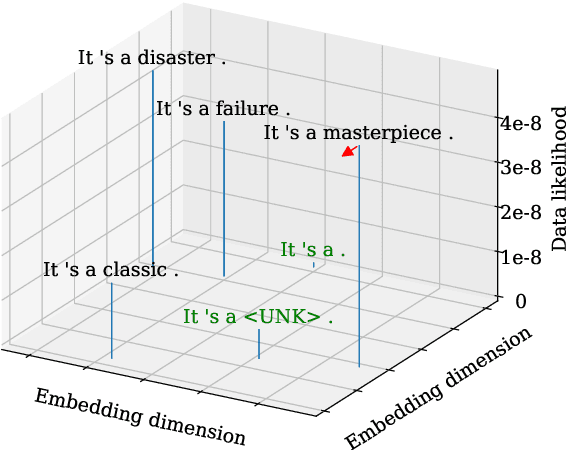

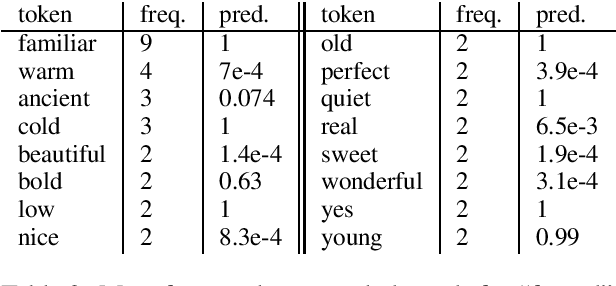
Recently, state-of-the-art NLP models gained an increasing syntactic and semantic understanding of language, and explanation methods are crucial to understand their decisions. Occlusion is a well established method that provides explanations on discrete language data, e.g. by removing a language unit from an input and measuring the impact on a model's decision. We argue that current occlusion-based methods often produce invalid or syntactically incorrect language data, neglecting the improved abilities of recent NLP models. Furthermore, gradient-based explanation methods disregard the discrete distribution of data in NLP. Thus, we propose OLM: a novel explanation method that combines occlusion and language models to sample valid and syntactically correct replacements with high likelihood, given the context of the original input. We lay out a theoretical foundation that alleviates these weaknesses of other explanation methods in NLP and provide results that underline the importance of considering data likelihood in occlusion-based explanation.
Layerwise Relevance Visualization in Convolutional Text Graph Classifiers
Sep 24, 2019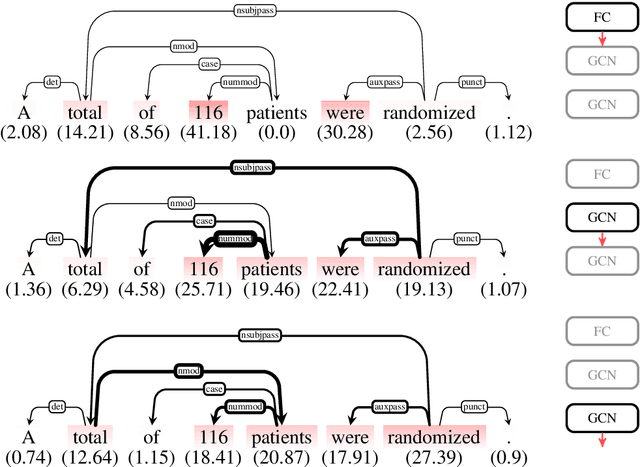
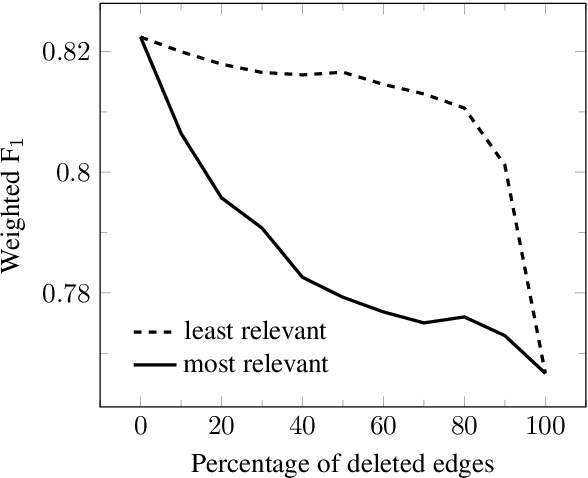
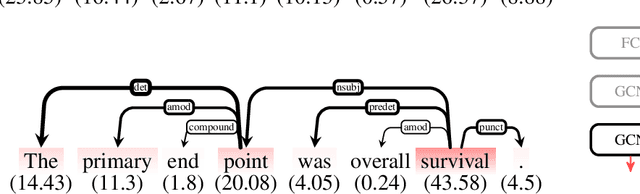
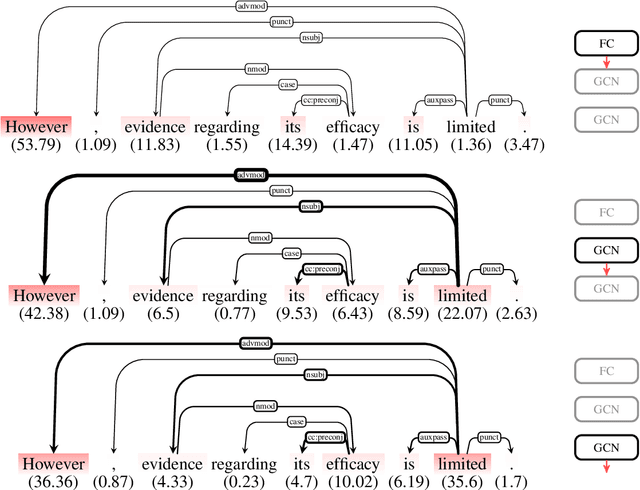
Representations in the hidden layers of Deep Neural Networks (DNN) are often hard to interpret since it is difficult to project them into an interpretable domain. Graph Convolutional Networks (GCN) allow this projection, but existing explainability methods do not exploit this fact, i.e. do not focus their explanations on intermediate states. In this work, we present a novel method that traces and visualizes features that contribute to a classification decision in the visible and hidden layers of a GCN. Our method exposes hidden cross-layer dynamics in the input graph structure. We experimentally demonstrate that it yields meaningful layerwise explanations for a GCN sentence classifier.
Neural Vector Conceptualization for Word Vector Space Interpretation
Apr 02, 2019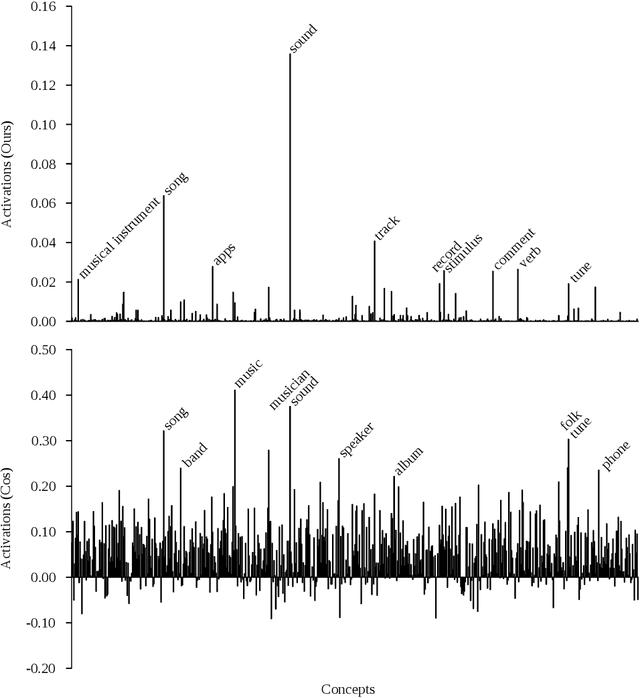
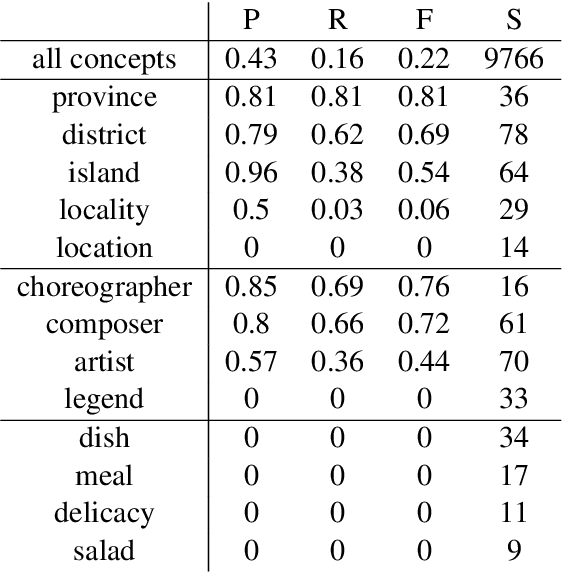
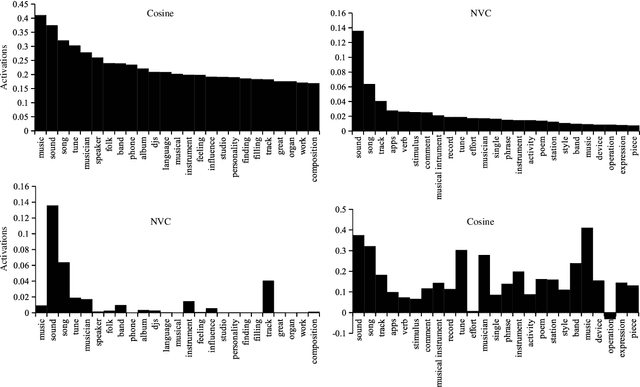
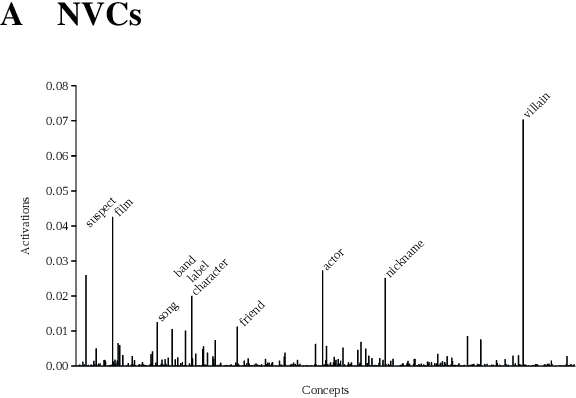
Distributed word vector spaces are considered hard to interpret which hinders the understanding of natural language processing (NLP) models. In this work, we introduce a new method to interpret arbitrary samples from a word vector space. To this end, we train a neural model to conceptualize word vectors, which means that it activates higher order concepts it recognizes in a given vector. Contrary to prior approaches, our model operates in the original vector space and is capable of learning non-linear relations between word vectors and concepts. Furthermore, we show that it produces considerably less entropic concept activation profiles than the popular cosine similarity.
Train, Sort, Explain: Learning to Diagnose Translation Models
Mar 28, 2019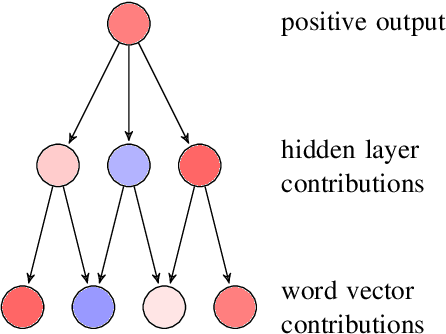

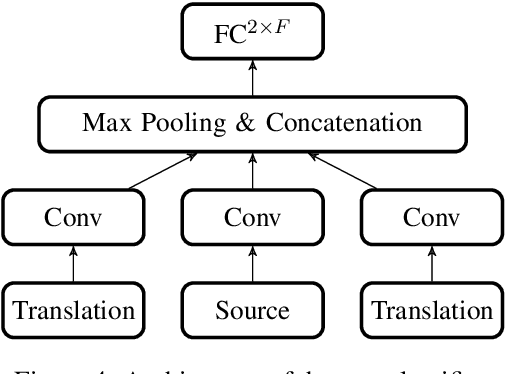
Evaluating translation models is a trade-off between effort and detail. On the one end of the spectrum there are automatic count-based methods such as BLEU, on the other end linguistic evaluations by humans, which arguably are more informative but also require a disproportionately high effort. To narrow the spectrum, we propose a general approach on how to automatically expose systematic differences between human and machine translations to human experts. Inspired by adversarial settings, we train a neural text classifier to distinguish human from machine translations. A classifier that performs and generalizes well after training should recognize systematic differences between the two classes, which we uncover with neural explainability methods. Our proof-of-concept implementation, DiaMaT, is open source. Applied to a dataset translated by a state-of-the-art neural Transformer model, DiaMaT achieves a classification accuracy of 75% and exposes meaningful differences between humans and the Transformer, amidst the current discussion about human parity.