 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavesplit: End-to-End Speech Separation by Speaker Clustering
Feb 20, 2020
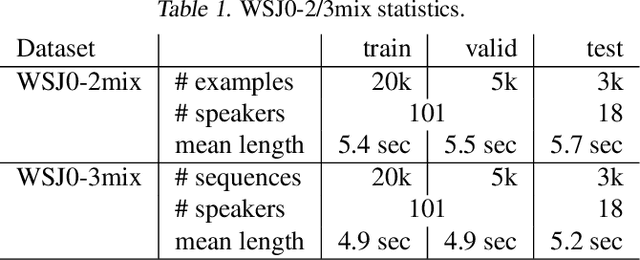
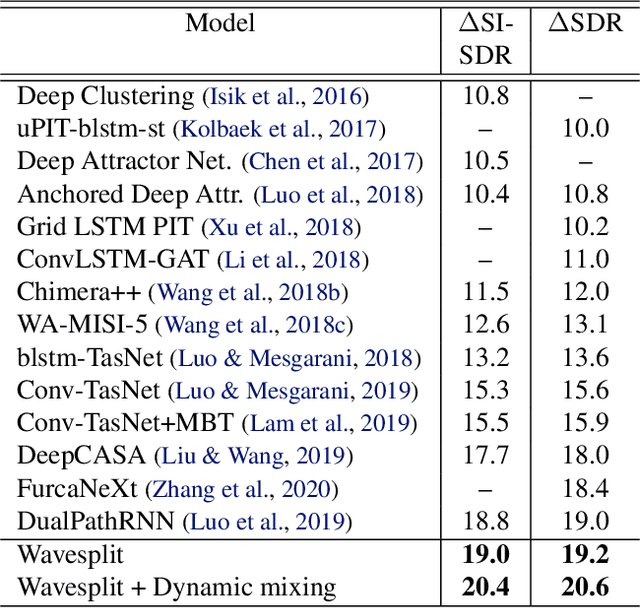
We introduce Wavesplit, an end-to-end speech separation system. From a single recording of mixed speech, the model infers and clusters representations of each speaker and then estimates each source signal conditioned on the inferred representations. The model is trained on the raw waveform to jointly perform the two tasks. Our model infers a set of speaker representations through clustering, which addresses the fundamental permutation problem of speech separation. Moreover, the sequence-wide speaker representations provide a more robust separation of long, challenging sequences, compared to previous approaches. We show that Wavesplit outperforms the previous state-of-the-art on clean mixtures of 2 or 3 speakers (WSJ0-2mix, WSJ0-3mix), as well as in noisy (WHAM!) and reverberated (WHAMR!) conditions. As an additional contribution, we further improve our model by introducing online data augmentation for separation.
Translationese as a Language in "Multilingual" NMT
Nov 10, 2019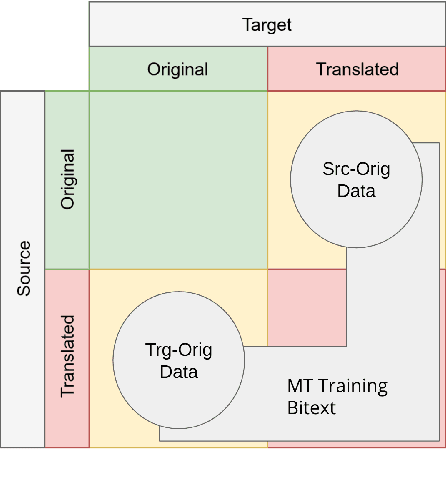
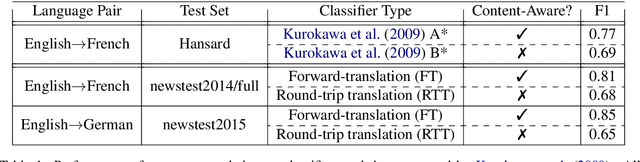
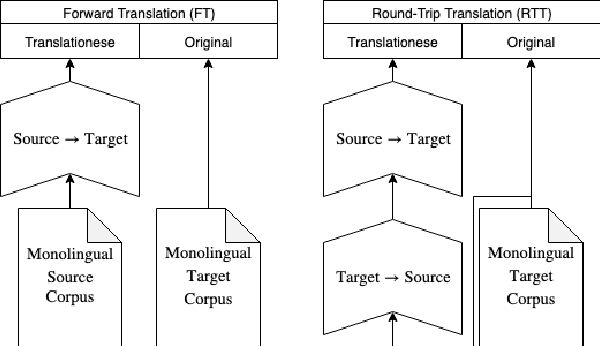
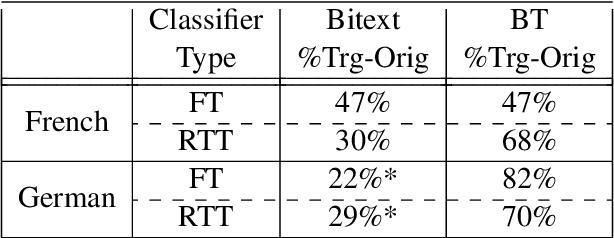
Machine translation has an undesirable propensity to produce "translationese" artifacts, which can lead to higher BLEU scores while being liked less by human raters. Motivated by this, we model translationese and original (i.e. natural) text as separate languages in a multilingual model, and pose the question: can we perform zero-shot translation between original source text and original target text? There is no data with original source and original target, so we train sentence-level classifiers to distinguish translationese from original target text, and use this classifier to tag the training data for an NMT model. Using this technique we bias the model to produce more natural outputs at test time, yielding gains in human evaluation scores on both accuracy and fluency. Additionally, we demonstrate that it is possible to bias the model to produce translationese and game the BLEU score, increasing it while decreasing human-rated quality. We analyze these models using metrics to measure the degree of translationese in the output, and present an analysis of the capriciousness of heuristically-based train-data tagging.
ELI5: Long Form Question Answering
Jul 22, 2019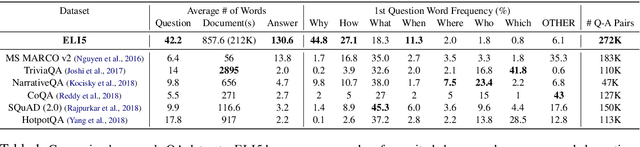


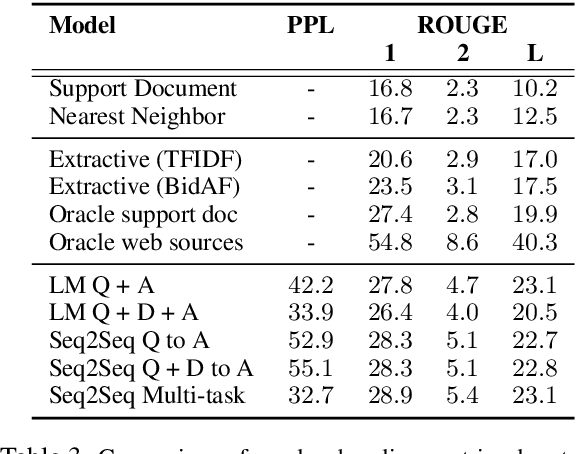
We introduce the first large-scale corpus for long-form question answering, a task requiring elaborate and in-depth answers to open-ended questions. The dataset comprises 270K threads from the Reddit forum ``Explain Like I'm Five'' (ELI5) where an online community provides answers to questions which are comprehensible by five year olds. Compared to existing datasets, ELI5 comprises diverse questions requiring multi-sentence answers. We provide a large set of web documents to help answer the question. Automatic and human evaluations show that an abstractive model trained with a multi-task objective outperforms conventional Seq2Seq, language modeling, as well as a strong extractive baseline. However, our best model is still far from human performance since raters prefer gold responses in over 86% of cases, leaving ample opportunity for future improvement.
Tagged Back-Translation
Jun 15, 2019
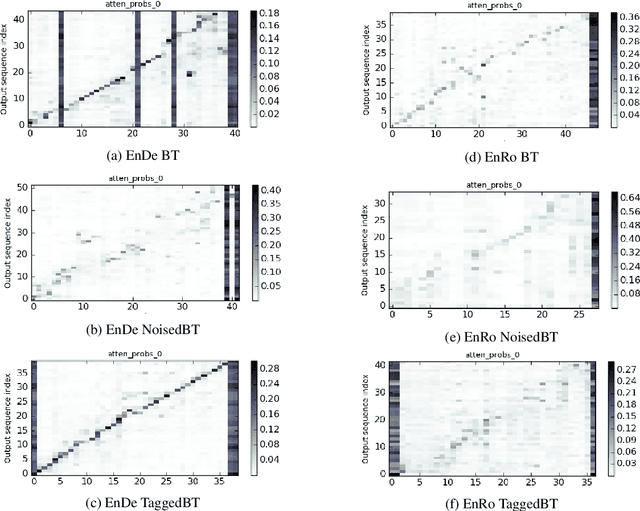
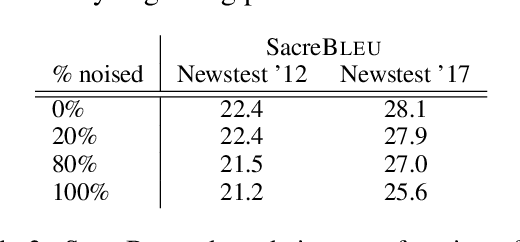
Recent work in Neural Machine Translation (NMT) has shown significant quality gains from noised-beam decoding during back-translation, a method to generate synthetic parallel data. We show that the main role of such synthetic noise is not to diversify the source side, as previously suggested, but simply to indicate to the model that the given source is synthetic. We propose a simpler alternative to noising techniques, consisting of tagging back-translated source sentences with an extra token. Our results on WMT outperform noised back-translation in English-Romanian and match performance on English-German, re-defining state-of-the-art in the former.
Unsupervised Paraphrasing without Translation
May 29, 2019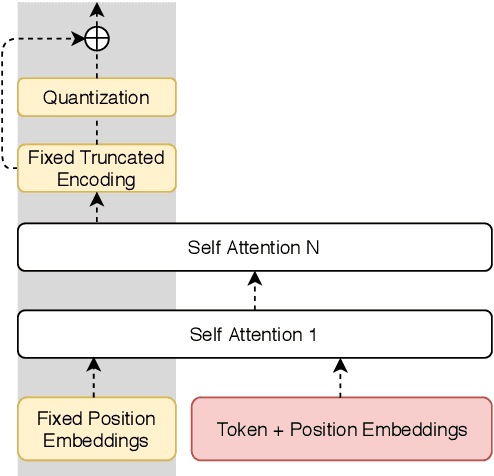
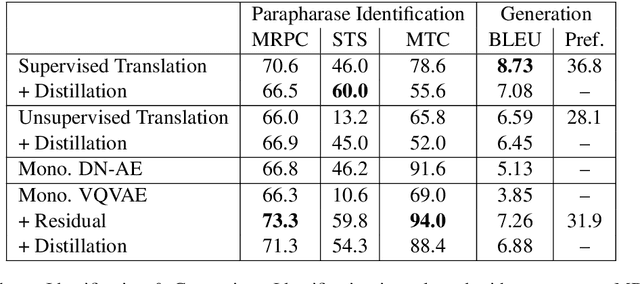
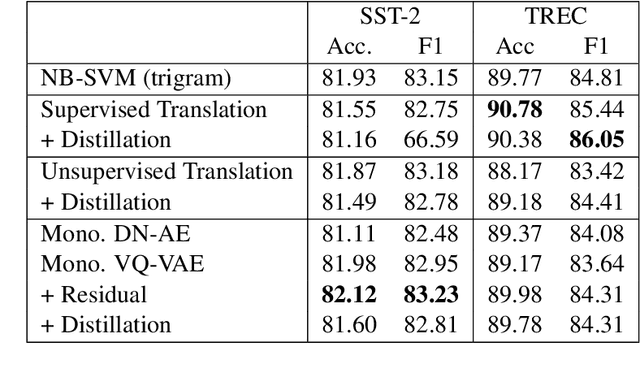
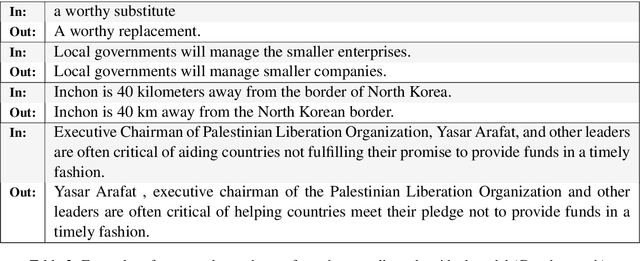
Paraphrasing exemplifies the ability to abstract semantic content from surface forms. Recent work on automatic paraphrasing is dominated by methods leveraging Machine Translation (MT) as an intermediate step. This contrasts with humans, who can paraphrase without being bilingual. This work proposes to learn paraphrasing models from an unlabeled monolingual corpus only. To that end, we propose a residual variant of vector-quantized variational auto-encoder. We compare with MT-based approaches on paraphrase identification, generation, and training augmentation. Monolingual paraphrasing outperforms unsupervised translation in all settings. Comparisons with supervised translation are more mixed: monolingual paraphrasing is interesting for identification and augmentation; supervised translation is superior for generation.
fairseq: A Fast, Extensible Toolkit for Sequence Modeling
Apr 01, 2019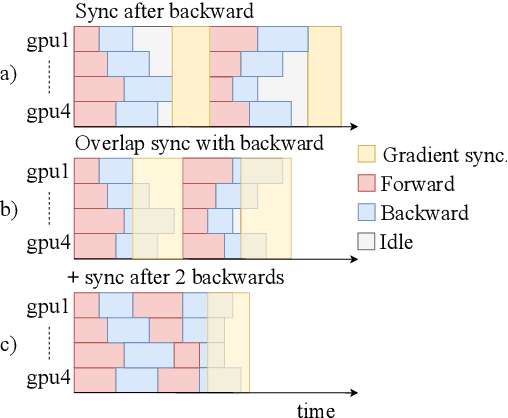

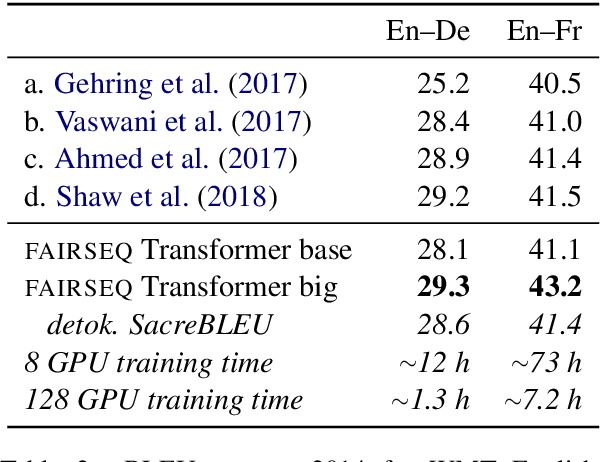
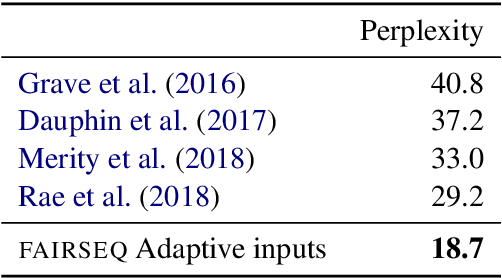
fairseq is an open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. The toolkit is based on PyTorch and supports distributed training across multiple GPUs and machines. We also support fast mixed-precision training and inference on modern GPUs. A demo video can be found at https://www.youtube.com/watch?v=OtgDdWtHvto
Modeling Human Motion with Quaternion-based Neural Networks
Jan 21, 2019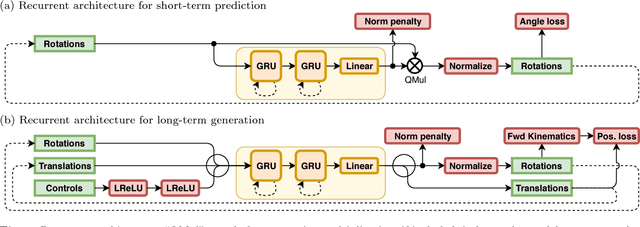
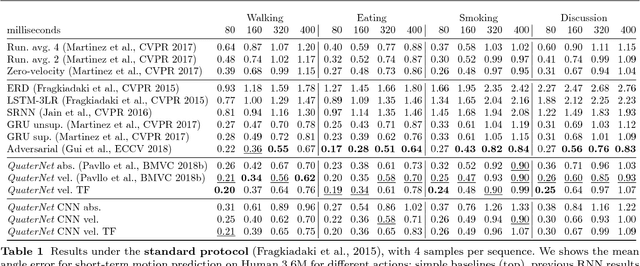
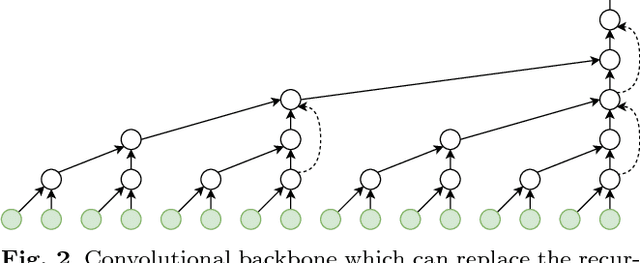
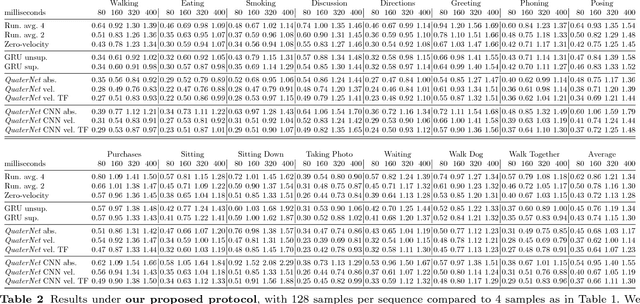
Previous work on predicting or generating 3D human pose sequences regresses either joint rotations or joint positions. The former strategy is prone to error accumulation along the kinematic chain, as well as discontinuities when using Euler angles or exponential maps as parameterizations. The latter requires re-projection onto skeleton constraints to avoid bone stretching and invalid configurations. This work addresses both limitations. QuaterNet represents rotations with quaternions and our loss function performs forward kinematics on a skeleton to penalize absolute position errors instead of angle errors. We investigate both recurrent and convolutional architectures and evaluate on short-term prediction and long-term generation. For the latter, our approach is qualitatively judged as realistic as recent neural strategies from the graphics literature. Our experiments compare quaternions to Euler angles as well as exponential maps and show that only a very short context is required to make reliable future predictions. Finally, we show that the standard evaluation protocol for Human3.6M produces high variance results and we propose a simple solution.
3D human pose estimation in video with temporal convolutions and semi-supervised training
Nov 28, 2018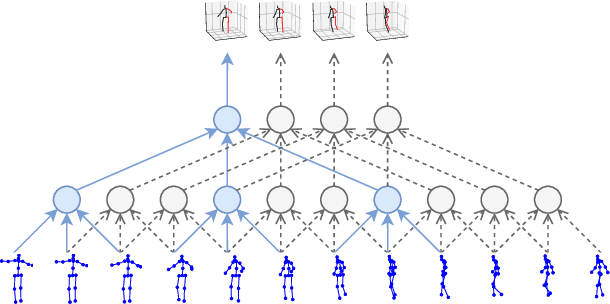
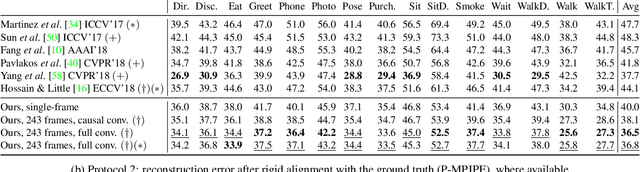

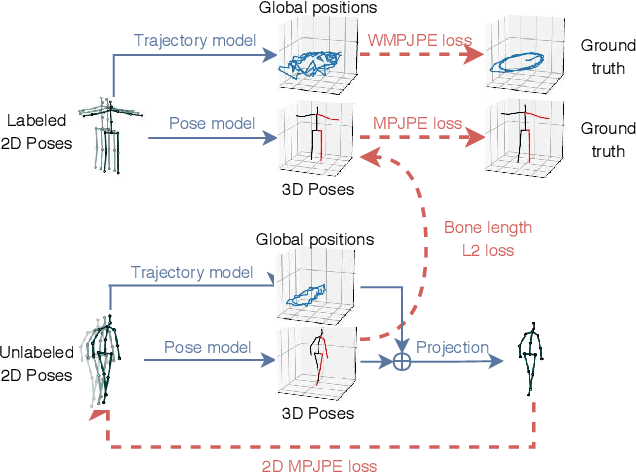
In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce. Code and models are available at https://github.com/facebookresearch/VideoPose3D
Classical Structured Prediction Losses for Sequence to Sequence Learning
Oct 05, 2018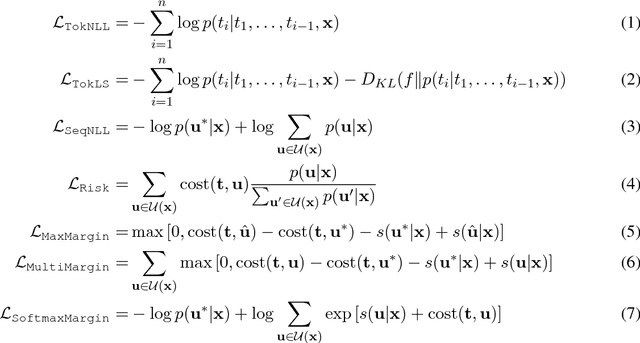
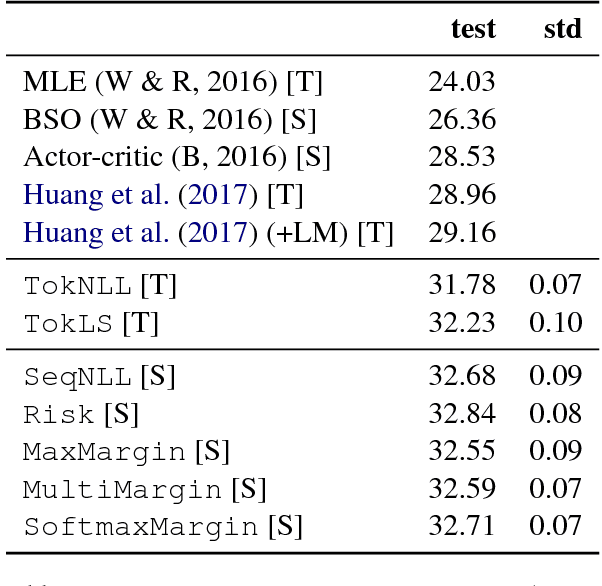
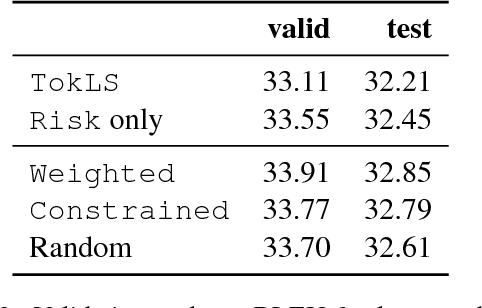
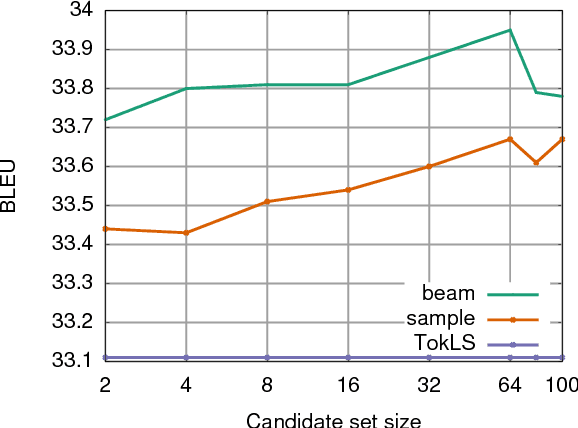
There has been much recent work on training neural attention models at the sequence-level using either reinforcement learning-style methods or by optimizing the beam. In this paper, we survey a range of classical objective functions that have been widely used to train linear models for structured prediction and apply them to neural sequence to sequence models. Our experiments show that these losses can perform surprisingly well by slightly outperforming beam search optimization in a like for like setup. We also report new state of the art results on both IWSLT'14 German-English translation as well as Gigaword abstractive summarization. On the larger WMT'14 English-French translation task, sequence-level training achieves 41.5 BLEU which is on par with the state of the art.
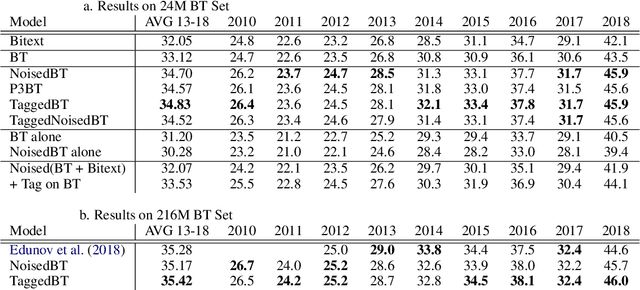
Understanding Back-Translation at Scale
Oct 03, 2018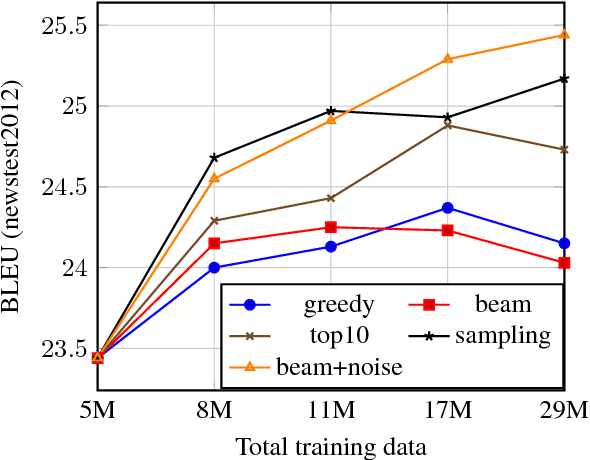
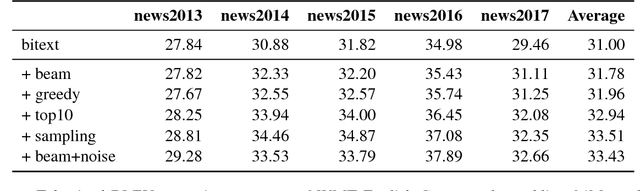
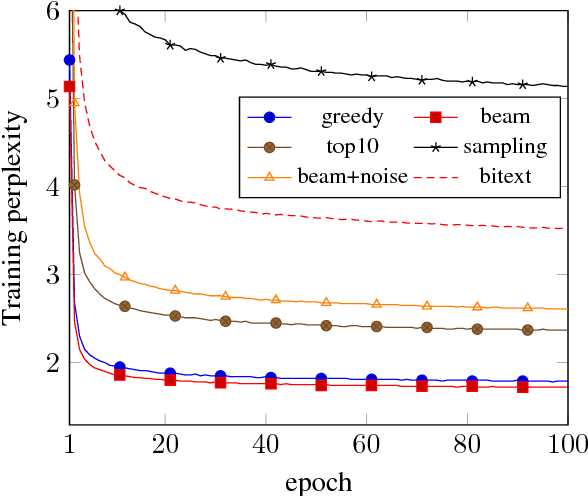
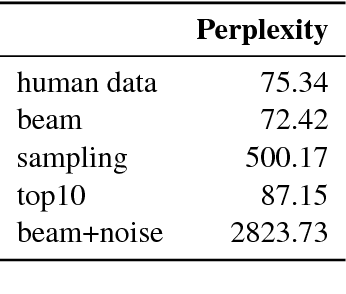
An effective method to improve neural machine translation with monolingual data is to augment the parallel training corpus with back-translations of target language sentences. This work broadens the understanding of back-translation and investigates a number of methods to generate synthetic source sentences. We find that in all but resource poor settings back-translations obtained via sampling or noised beam outputs are most effective. Our analysis shows that sampling or noisy synthetic data gives a much stronger training signal than data generated by beam or greedy search. We also compare how synthetic data compares to genuine bitext and study various domain effects. Finally, we scale to hundreds of millions of monolingual sentences and achieve a new state of the art of 35 BLEU on the WMT'14 English-German test set.