 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecialized Language Models with Cheap Inference from Limited Domain Data
Feb 02, 2024



Large language models have emerged as a versatile tool but are challenging to apply to tasks lacking large inference budgets and large in-domain training sets. This work formalizes these constraints and distinguishes four important variables: the pretraining budget (for training before the target domain is known), the specialization budget (for training after the target domain is known), the inference budget, and the in-domain training set size. Across these settings, we compare different approaches from the machine learning literature. Limited by inference cost, we find better alternatives to the standard practice of training very large vanilla transformer models. In particular, we show that hyper-networks and mixture of experts have better perplexity for large pretraining budgets, while small models trained on importance sampled datasets are attractive for large specialization budgets.
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling
Jan 29, 2024



Large language models are trained on massive scrapes of the web, which are often unstructured, noisy, and poorly phrased. Current scaling laws show that learning from such data requires an abundance of both compute and data, which grows with the size of the model being trained. This is infeasible both because of the large compute costs and duration associated with pre-training, and the impending scarcity of high-quality data on the web. In this work, we propose Web Rephrase Augmented Pre-training ($\textbf{WRAP}$) that uses an off-the-shelf instruction-tuned model prompted to paraphrase documents on the web in specific styles such as "like Wikipedia" or in "question-answer format" to jointly pre-train LLMs on real and synthetic rephrases. First, we show that using WRAP on the C4 dataset, which is naturally noisy, speeds up pre-training by $\sim3x$. At the same pre-training compute budget, it improves perplexity by more than 10% on average across different subsets of the Pile, and improves zero-shot question answer accuracy across 13 tasks by more than 2%. Second, we investigate the impact of the re-phrasing style on the performance of the model, offering insights into how the composition of the training data can impact the performance of LLMs in OOD settings. Our gains are attributed to the fact that re-phrased synthetic data has higher utility than just real data because it (i) incorporates style diversity that closely reflects downstream evaluation style, and (ii) has higher 'quality' than web-scraped data.
Adaptive Training Distributions with Scalable Online Bilevel Optimization
Nov 20, 2023



Large neural networks pretrained on web-scale corpora are central to modern machine learning. In this paradigm, the distribution of the large, heterogeneous pretraining data rarely matches that of the application domain. This work considers modifying the pretraining distribution in the case where one has a small sample of data reflecting the targeted test conditions. We propose an algorithm motivated by a recent formulation of this setting as an online, bilevel optimization problem. With scalability in mind, our algorithm prioritizes computing gradients at training points which are likely to most improve the loss on the targeted distribution. Empirically, we show that in some cases this approach is beneficial over existing strategies from the domain adaptation literature but may not succeed in other cases. We propose a simple test to evaluate when our approach can be expected to work well and point towards further research to address current limitations.
Transfer Learning for Structured Pruning under Limited Task Data
Nov 10, 2023



Large, pre-trained models are problematic to use in resource constrained applications. Fortunately, task-aware structured pruning methods offer a solution. These approaches reduce model size by dropping structural units like layers and attention heads in a manner that takes into account the end-task. However, these pruning algorithms require more task-specific data than is typically available. We propose a framework which combines structured pruning with transfer learning to reduce the need for task-specific data. Our empirical results answer questions such as: How should the two tasks be coupled? What parameters should be transferred? And, when during training should transfer learning be introduced? Leveraging these insights, we demonstrate that our framework results in pruned models with improved generalization over strong baselines.
High-Resource Methodological Bias in Low-Resource Investigations
Nov 14, 2022The central bottleneck for low-resource NLP is typically regarded to be the quantity of accessible data, overlooking the contribution of data quality. This is particularly seen in the development and evaluation of low-resource systems via down sampling of high-resource language data. In this work we investigate the validity of this approach, and we specifically focus on two well-known NLP tasks for our empirical investigations: POS-tagging and machine translation. We show that down sampling from a high-resource language results in datasets with different properties than the low-resource datasets, impacting the model performance for both POS-tagging and machine translation. Based on these results we conclude that naive down sampling of datasets results in a biased view of how well these systems work in a low-resource scenario.
AudioLM: a Language Modeling Approach to Audio Generation
Sep 07, 2022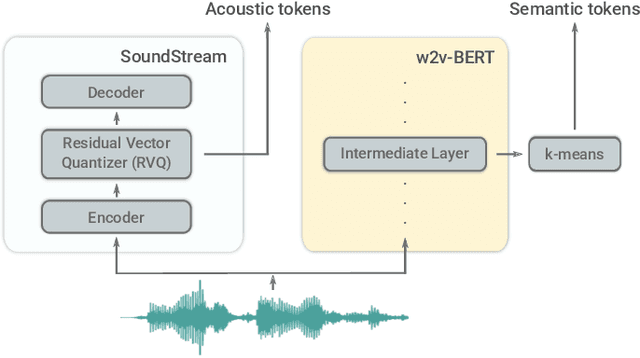

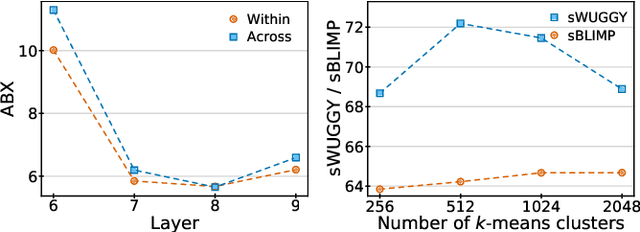

We introduce AudioLM, a framework for high-quality audio generation with long-term consistency. AudioLM maps the input audio to a sequence of discrete tokens and casts audio generation as a language modeling task in this representation space. We show how existing audio tokenizers provide different trade-offs between reconstruction quality and long-term structure, and we propose a hybrid tokenization scheme to achieve both objectives. Namely, we leverage the discretized activations of a masked language model pre-trained on audio to capture long-term structure and the discrete codes produced by a neural audio codec to achieve high-quality synthesis. By training on large corpora of raw audio waveforms, AudioLM learns to generate natural and coherent continuations given short prompts. When trained on speech, and without any transcript or annotation, AudioLM generates syntactically and semantically plausible speech continuations while also maintaining speaker identity and prosody for unseen speakers. Furthermore, we demonstrate how our approach extends beyond speech by generating coherent piano music continuations, despite being trained without any symbolic representation of music.
Learning strides in convolutional neural networks
Feb 03, 2022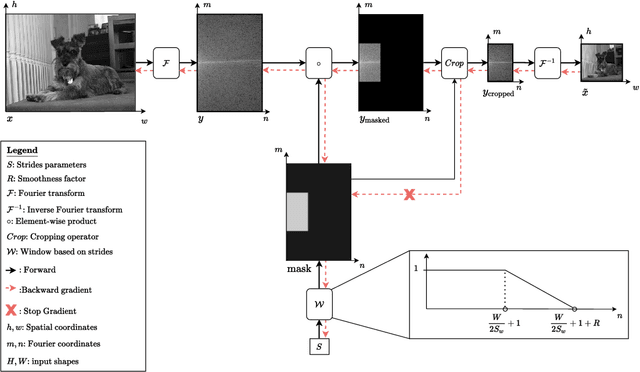
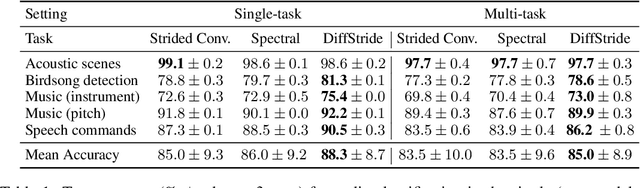
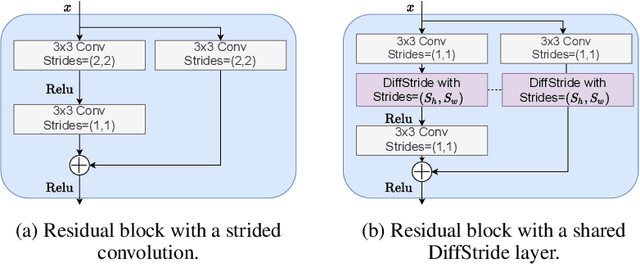
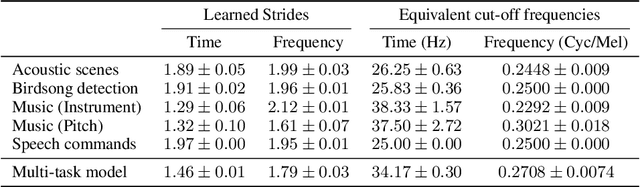
Convolutional neural networks typically contain several downsampling operators, such as strided convolutions or pooling layers, that progressively reduce the resolution of intermediate representations. This provides some shift-invariance while reducing the computational complexity of the whole architecture. A critical hyperparameter of such layers is their stride: the integer factor of downsampling. As strides are not differentiable, finding the best configuration either requires cross-validation or discrete optimization (e.g. architecture search), which rapidly become prohibitive as the search space grows exponentially with the number of downsampling layers. Hence, exploring this search space by gradient descent would allow finding better configurations at a lower computational cost. This work introduces DiffStride, the first downsampling layer with learnable strides. Our layer learns the size of a cropping mask in the Fourier domain, that effectively performs resizing in a differentiable way. Experiments on audio and image classification show the generality and effectiveness of our solution: we use DiffStride as a drop-in replacement to standard downsampling layers and outperform them. In particular, we show that introducing our layer into a ResNet-18 architecture allows keeping consistent high performance on CIFAR10, CIFAR100 and ImageNet even when training starts from poor random stride configurations. Moreover, formulating strides as learnable variables allows us to introduce a regularization term that controls the computational complexity of the architecture. We show how this regularization allows trading off accuracy for efficiency on ImageNet.
Minimum Bayes Risk Decoding with Neural Metrics of Translation Quality
Dec 02, 2021
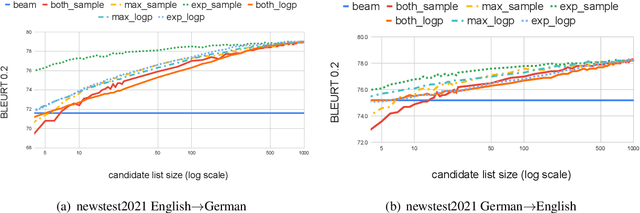
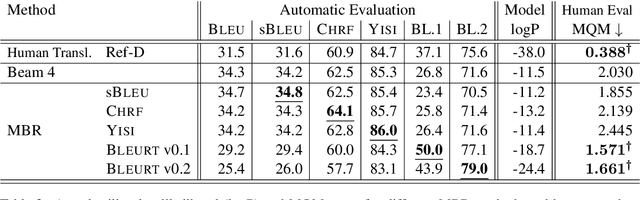
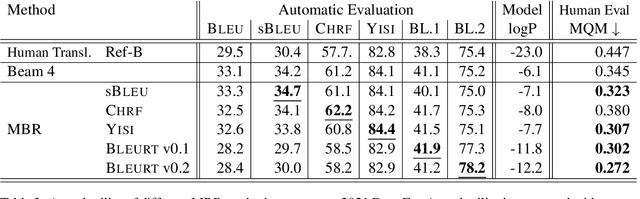
This work applies Minimum Bayes Risk (MBR) decoding to optimize diverse automated metrics of translation quality. Automatic metrics in machine translation have made tremendous progress recently. In particular, neural metrics, fine-tuned on human ratings (e.g. BLEURT, or COMET) are outperforming surface metrics in terms of correlations to human judgements. Our experiments show that the combination of a neural translation model with a neural reference-based metric, BLEURT, results in significant improvement in automatic and human evaluations. This improvement is obtained with translations different from classical beam-search output: these translations have much lower likelihood and are less favored by surface metrics like BLEU.
The Trade-offs of Domain Adaptation for Neural Language Models
Sep 21, 2021In this paper, we connect language model adaptation with concepts of machine learning theory. We consider a training setup with a large out-of-domain set and a small in-domain set. As a first contribution, we derive how the benefit of training a model on either set depends on the size of the sets and the distance between their underlying distribution. As a second contribution, we present how the most popular data selection techniques -- importance sampling, intelligent data selection and influence functions -- can be presented in a common framework which highlights their similarity and also their subtle differences.
On the Complementarity of Data Selection and Fine Tuning for Domain Adaptation
Sep 15, 2021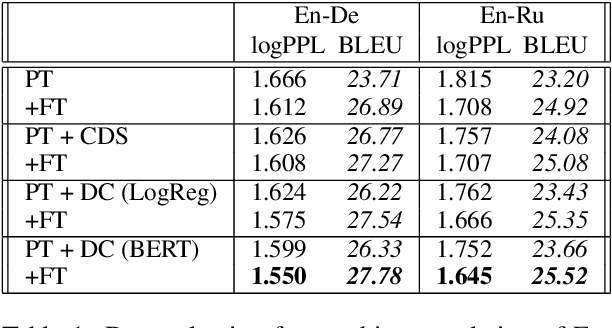
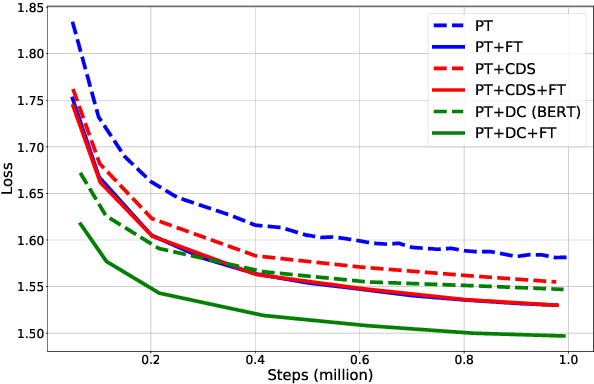
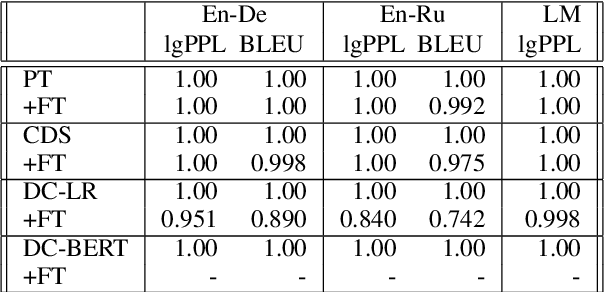
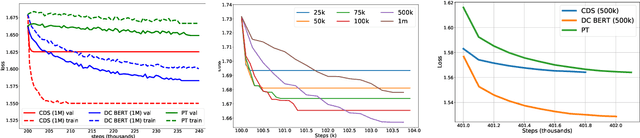
Domain adaptation of neural networks commonly relies on three training phases: pretraining, selected data training and then fine tuning. Data selection improves target domain generalization by training further on pretraining data identified by relying on a small sample of target domain data. This work examines the benefit of data selection for language modeling and machine translation. Our experiments assess the complementarity of selection with fine tuning and result in practical recommendations: (i) selected data must be similar to the fine-tuning domain but not so much as to erode the complementary effect of fine-tuning; (ii) there is a trade-off between selecting little data for fast but limited progress or much data for slow but long lasting progress; (iii) data selection can be applied early during pretraining, with performance gains comparable to long pretraining session; (iv) data selection from domain classifiers is often more effective than the popular contrastive data selection method.