 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounterfactual Inference for Consumer Choice Across Many Product Categories
Jun 06, 2019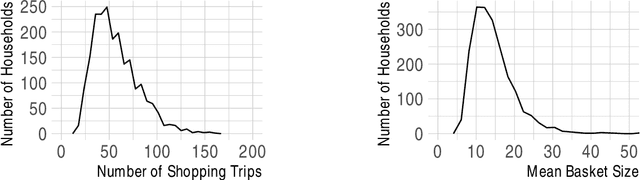
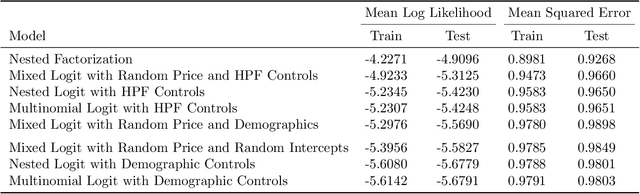
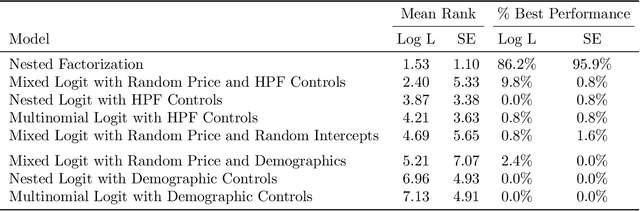
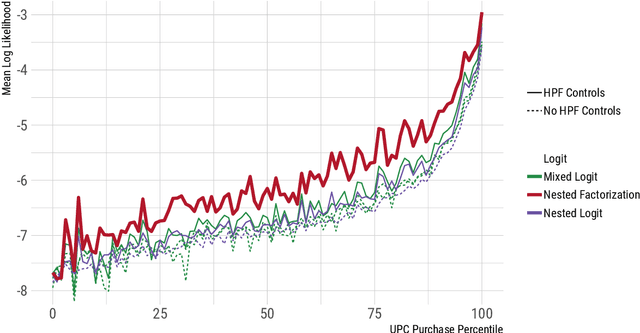
This paper proposes a method for estimating consumer preferences among discrete choices, where the consumer chooses at most one product in a category, but selects from multiple categories in parallel. The consumer's utility is additive in the different categories. Her preferences about product attributes as well as her price sensitivity vary across products and are in general correlated across products. We build on techniques from the machine learning literature on probabilistic models of matrix factorization, extending the methods to account for time-varying product attributes and products going out of stock. We evaluate the performance of the model using held-out data from weeks with price changes or out of stock products. We show that our model improves over traditional modeling approaches that consider each category in isolation. One source of the improvement is the ability of the model to accurately estimate heterogeneity in preferences (by pooling information across categories); another source of improvement is its ability to estimate the preferences of consumers who have rarely or never made a purchase in a given category in the training data. Using held-out data, we show that our model can accurately distinguish which consumers are most price sensitive to a given product. We consider counterfactuals such as personally targeted price discounts, showing that using a richer model such as the one we propose substantially increases the benefits of personalization in discounts.
Estimating Heterogeneous Consumer Preferences for Restaurants and Travel Time Using Mobile Location Data
Jan 22, 2018



This paper analyzes consumer choices over lunchtime restaurants using data from a sample of several thousand anonymous mobile phone users in the San Francisco Bay Area. The data is used to identify users' approximate typical morning location, as well as their choices of lunchtime restaurants. We build a model where restaurants have latent characteristics (whose distribution may depend on restaurant observables, such as star ratings, food category, and price range), each user has preferences for these latent characteristics, and these preferences are heterogeneous across users. Similarly, each item has latent characteristics that describe users' willingness to travel to the restaurant, and each user has individual-specific preferences for those latent characteristics. Thus, both users' willingness to travel and their base utility for each restaurant vary across user-restaurant pairs. We use a Bayesian approach to estimation. To make the estimation computationally feasible, we rely on variational inference to approximate the posterior distribution, as well as stochastic gradient descent as a computational approach. Our model performs better than more standard competing models such as multinomial logit and nested logit models, in part due to the personalization of the estimates. We analyze how consumers re-allocate their demand after a restaurant closes to nearby restaurants versus more distant restaurants with similar characteristics, and we compare our predictions to actual outcomes. Finally, we show how the model can be used to analyze counterfactual questions such as what type of restaurant would attract the most consumers in a given location.
Structured Embedding Models for Grouped Data
Sep 28, 2017

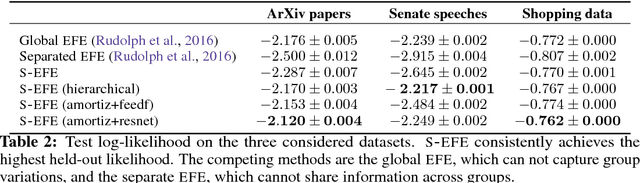

Word embeddings are a powerful approach for analyzing language, and exponential family embeddings (EFE) extend them to other types of data. Here we develop structured exponential family embeddings (S-EFE), a method for discovering embeddings that vary across related groups of data. We study how the word usage of U.S. Congressional speeches varies across states and party affiliation, how words are used differently across sections of the ArXiv, and how the co-purchase patterns of groceries can vary across seasons. Key to the success of our method is that the groups share statistical information. We develop two sharing strategies: hierarchical modeling and amortization. We demonstrate the benefits of this approach in empirical studies of speeches, abstracts, and shopping baskets. We show how S-EFE enables group-specific interpretation of word usage, and outperforms EFE in predicting held-out data.
Dynamic Bernoulli Embeddings for Language Evolution
Mar 23, 2017

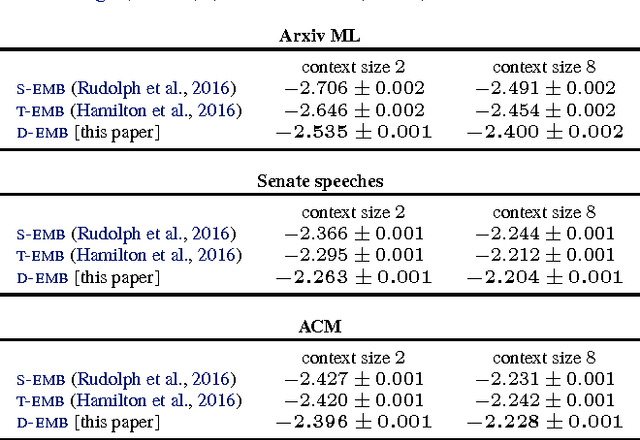
Word embeddings are a powerful approach for unsupervised analysis of language. Recently, Rudolph et al. (2016) developed exponential family embeddings, which cast word embeddings in a probabilistic framework. Here, we develop dynamic embeddings, building on exponential family embeddings to capture how the meanings of words change over time. We use dynamic embeddings to analyze three large collections of historical texts: the U.S. Senate speeches from 1858 to 2009, the history of computer science ACM abstracts from 1951 to 2014, and machine learning papers on the Arxiv from 2007 to 2015. We find dynamic embeddings provide better fits than classical embeddings and capture interesting patterns about how language changes.
Correlated Random Measures
Nov 09, 2016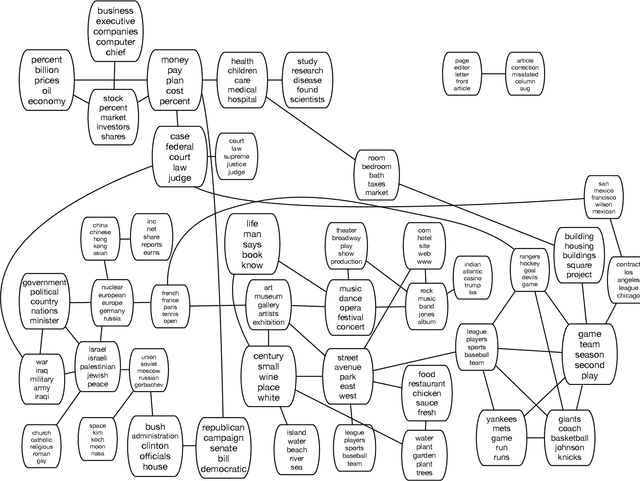

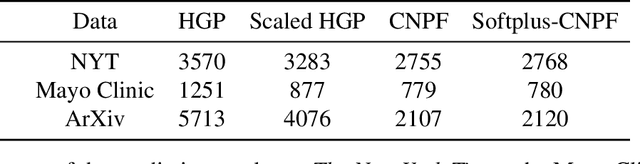
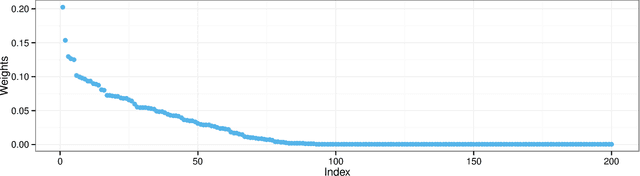
We develop correlated random measures, random measures where the atom weights can exhibit a flexible pattern of dependence, and use them to develop powerful hierarchical Bayesian nonparametric models. Hierarchical Bayesian nonparametric models are usually built from completely random measures, a Poisson-process based construction in which the atom weights are independent. Completely random measures imply strong independence assumptions in the corresponding hierarchical model, and these assumptions are often misplaced in real-world settings. Correlated random measures address this limitation. They model correlation within the measure by using a Gaussian process in concert with the Poisson process. With correlated random measures, for example, we can develop a latent feature model for which we can infer both the properties of the latent features and their dependency pattern. We develop several other examples as well. We study a correlated random measure model of pairwise count data. We derive an efficient variational inference algorithm and show improved predictive performance on large data sets of documents, web clicks, and electronic health records.
Deep Survival Analysis
Sep 18, 2016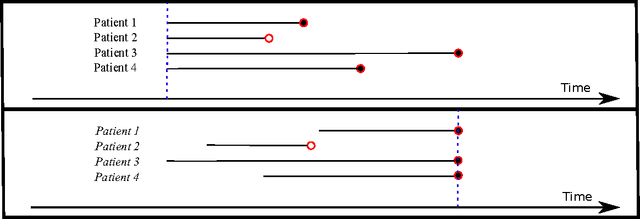
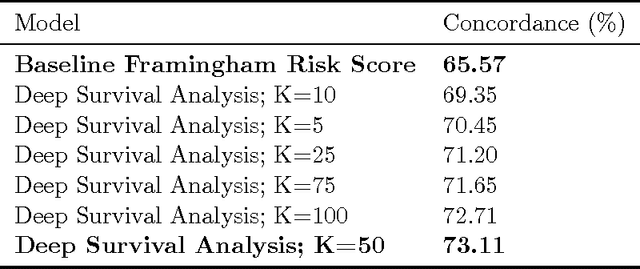

The electronic health record (EHR) provides an unprecedented opportunity to build actionable tools to support physicians at the point of care. In this paper, we investigate survival analysis in the context of EHR data. We introduce deep survival analysis, a hierarchical generative approach to survival analysis. It departs from previous approaches in two primary ways: (1) all observations, including covariates, are modeled jointly conditioned on a rich latent structure; and (2) the observations are aligned by their failure time, rather than by an arbitrary time zero as in traditional survival analysis. Further, it (3) scalably handles heterogeneous (continuous and discrete) data types that occur in the EHR. We validate deep survival analysis model by stratifying patients according to risk of developing coronary heart disease (CHD). Specifically, we study a dataset of 313,000 patients corresponding to 5.5 million months of observations. When compared to the clinically validated Framingham CHD risk score, deep survival analysis is significantly superior in stratifying patients according to their risk.
Variational Tempering
May 28, 2016
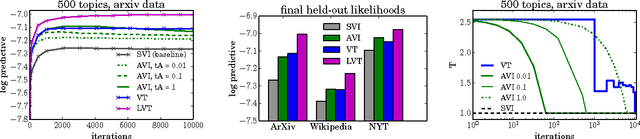
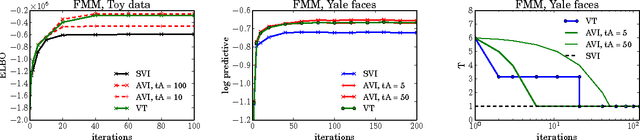
Variational inference (VI) combined with data subsampling enables approximate posterior inference over large data sets, but suffers from poor local optima. We first formulate a deterministic annealing approach for the generic class of conditionally conjugate exponential family models. This approach uses a decreasing temperature parameter which deterministically deforms the objective during the course of the optimization. A well-known drawback to this annealing approach is the choice of the cooling schedule. We therefore introduce variational tempering, a variational algorithm that introduces a temperature latent variable to the model. In contrast to related work in the Markov chain Monte Carlo literature, this algorithm results in adaptive annealing schedules. Lastly, we develop local variational tempering, which assigns a latent temperature to each data point; this allows for dynamic annealing that varies across data. Compared to the traditional VI, all proposed approaches find improved predictive likelihoods on held-out data.
* published version, 8 pages, 4 figures
Continuous Time Dynamic Topic Models
May 16, 2015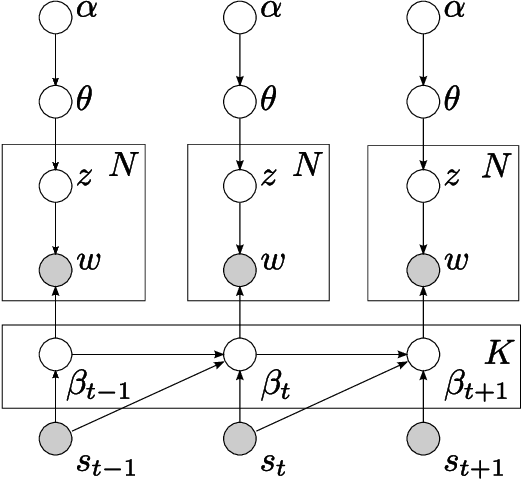

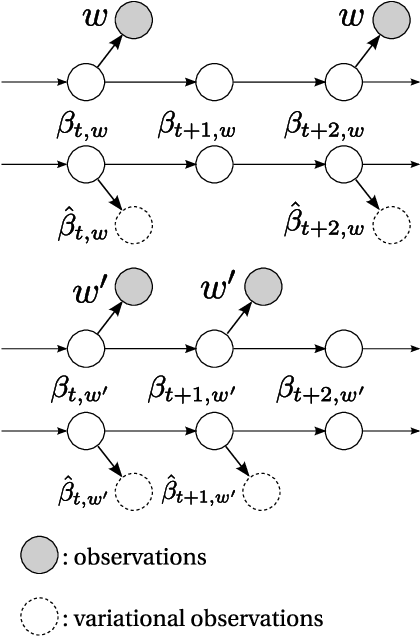
In this paper, we develop the continuous time dynamic topic model (cDTM). The cDTM is a dynamic topic model that uses Brownian motion to model the latent topics through a sequential collection of documents, where a "topic" is a pattern of word use that we expect to evolve over the course of the collection. We derive an efficient variational approximate inference algorithm that takes advantage of the sparsity of observations in text, a property that lets us easily handle many time points. In contrast to the cDTM, the original discrete-time dynamic topic model (dDTM) requires that time be discretized. Moreover, the complexity of variational inference for the dDTM grows quickly as time granularity increases, a drawback which limits fine-grained discretization. We demonstrate the cDTM on two news corpora, reporting both predictive perplexity and the novel task of time stamp prediction.
Smoothed Gradients for Stochastic Variational Inference
Nov 18, 2014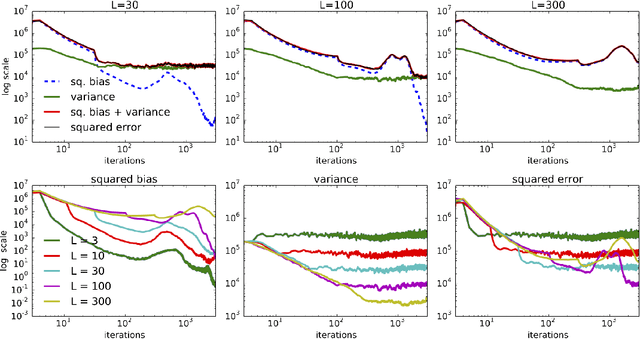
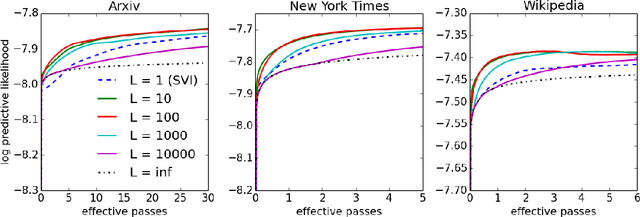
Stochastic variational inference (SVI) lets us scale up Bayesian computation to massive data. It uses stochastic optimization to fit a variational distribution, following easy-to-compute noisy natural gradients. As with most traditional stochastic optimization methods, SVI takes precautions to use unbiased stochastic gradients whose expectations are equal to the true gradients. In this paper, we explore the idea of following biased stochastic gradients in SVI. Our method replaces the natural gradient with a similarly constructed vector that uses a fixed-window moving average of some of its previous terms. We will demonstrate the many advantages of this technique. First, its computational cost is the same as for SVI and storage requirements only multiply by a constant factor. Second, it enjoys significant variance reduction over the unbiased estimates, smaller bias than averaged gradients, and leads to smaller mean-squared error against the full gradient. We test our method on latent Dirichlet allocation with three large corpora.
A Nested HDP for Hierarchical Topic Models
Jan 16, 2013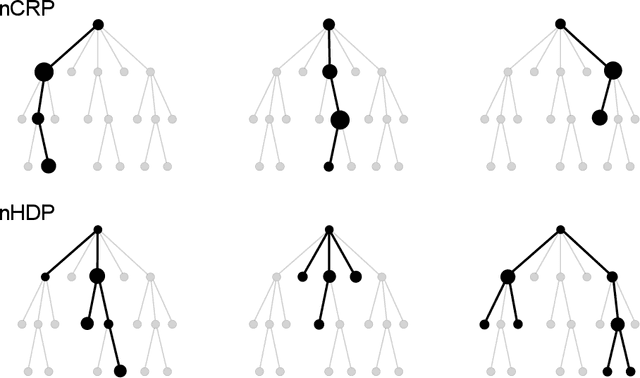

We develop a nested hierarchical Dirichlet process (nHDP) for hierarchical topic modeling. The nHDP is a generalization of the nested Chinese restaurant process (nCRP) that allows each word to follow its own path to a topic node according to a document-specific distribution on a shared tree. This alleviates the rigid, single-path formulation of the nCRP, allowing a document to more easily express thematic borrowings as a random effect. We demonstrate our algorithm on 1.8 million documents from The New York Times.