 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Hidden State Embeddings for Viterbi Sequence Labeling
Aug 02, 2017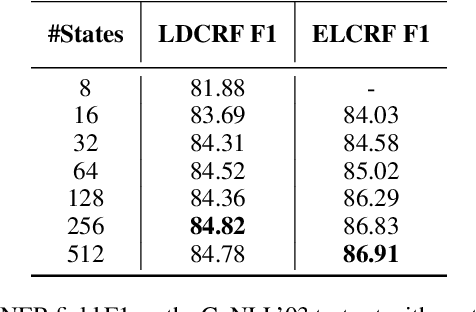

In textual information extraction and other sequence labeling tasks it is now common to use recurrent neural networks (such as LSTM) to form rich embedded representations of long-term input co-occurrence patterns. Representation of output co-occurrence patterns is typically limited to a hand-designed graphical model, such as a linear-chain CRF representing short-term Markov dependencies among successive labels. This paper presents a method that learns embedded representations of latent output structure in sequence data. Our model takes the form of a finite-state machine with a large number of latent states per label (a latent variable CRF), where the state-transition matrix is factorized---effectively forming an embedded representation of state-transitions capable of enforcing long-term label dependencies, while supporting exact Viterbi inference over output labels. We demonstrate accuracy improvements and interpretable latent structure in a synthetic but complex task based on CoNLL named entity recognition.
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
Jul 22, 2017
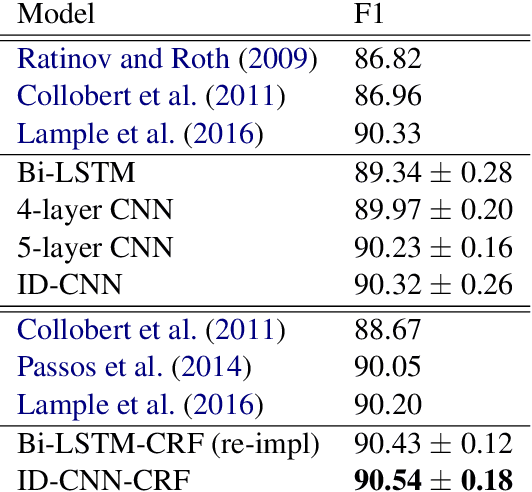
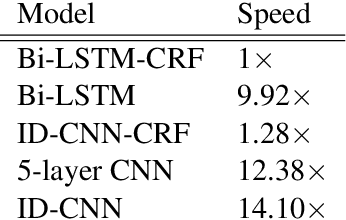
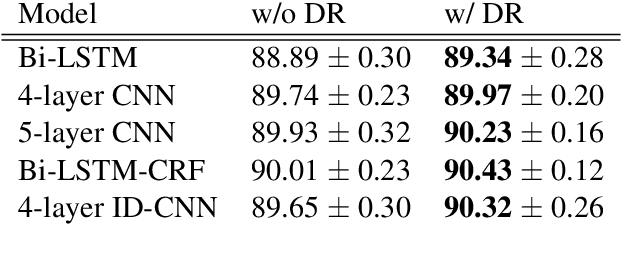
Today when many practitioners run basic NLP on the entire web and large-volume traffic, faster methods are paramount to saving time and energy costs. Recent advances in GPU hardware have led to the emergence of bi-directional LSTMs as a standard method for obtaining per-token vector representations serving as input to labeling tasks such as NER (often followed by prediction in a linear-chain CRF). Though expressive and accurate, these models fail to fully exploit GPU parallelism, limiting their computational efficiency. This paper proposes a faster alternative to Bi-LSTMs for NER: Iterated Dilated Convolutional Neural Networks (ID-CNNs), which have better capacity than traditional CNNs for large context and structured prediction. Unlike LSTMs whose sequential processing on sentences of length N requires O(N) time even in the face of parallelism, ID-CNNs permit fixed-depth convolutions to run in parallel across entire documents. We describe a distinct combination of network structure, parameter sharing and training procedures that enable dramatic 14-20x test-time speedups while retaining accuracy comparable to the Bi-LSTM-CRF. Moreover, ID-CNNs trained to aggregate context from the entire document are even more accurate while maintaining 8x faster test time speeds.
End-to-End Learning for Structured Prediction Energy Networks
Jul 15, 2017
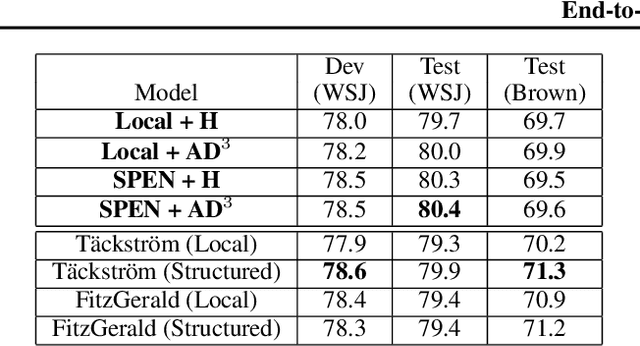
Structured Prediction Energy Networks (SPENs) are a simple, yet expressive family of structured prediction models (Belanger and McCallum, 2016). An energy function over candidate structured outputs is given by a deep network, and predictions are formed by gradient-based optimization. This paper presents end-to-end learning for SPENs, where the energy function is discriminatively trained by back-propagating through gradient-based prediction. In our experience, the approach is substantially more accurate than the structured SVM method of Belanger and McCallum (2016), as it allows us to use more sophisticated non-convex energies. We provide a collection of techniques for improving the speed, accuracy, and memory requirements of end-to-end SPENs, and demonstrate the power of our method on 7-Scenes image denoising and CoNLL-2005 semantic role labeling tasks. In both, inexact minimization of non-convex SPEN energies is superior to baseline methods that use simplistic energy functions that can be minimized exactly.
Chains of Reasoning over Entities, Relations, and Text using Recurrent Neural Networks
May 01, 2017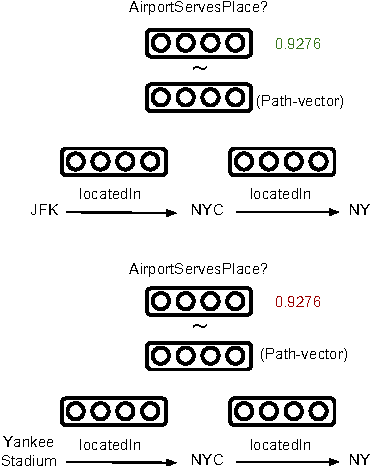
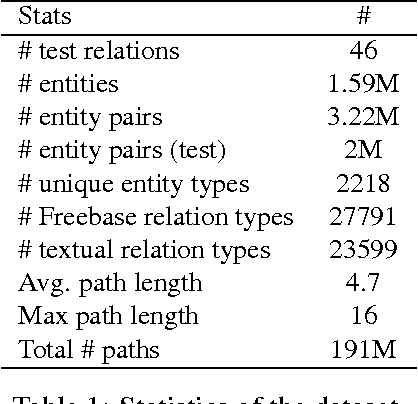
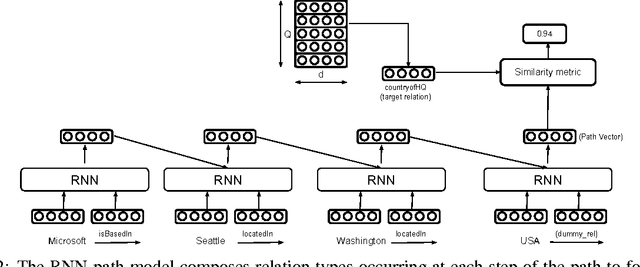
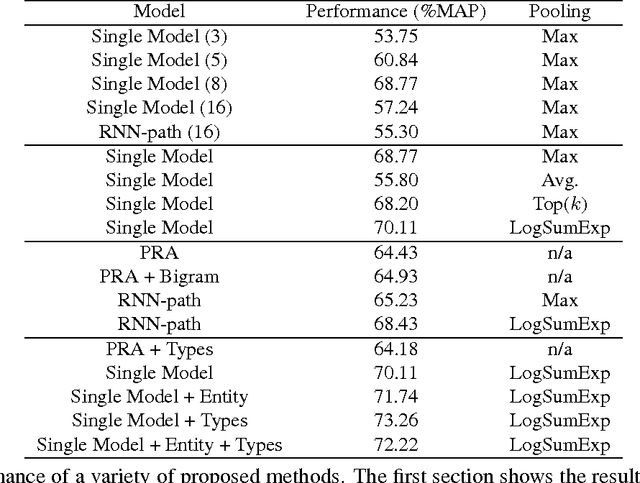
Our goal is to combine the rich multistep inference of symbolic logical reasoning with the generalization capabilities of neural networks. We are particularly interested in complex reasoning about entities and relations in text and large-scale knowledge bases (KBs). Neelakantan et al. (2015) use RNNs to compose the distributed semantics of multi-hop paths in KBs; however for multiple reasons, the approach lacks accuracy and practicality. This paper proposes three significant modeling advances: (1) we learn to jointly reason about relations, entities, and entity-types; (2) we use neural attention modeling to incorporate multiple paths; (3) we learn to share strength in a single RNN that represents logical composition across all relations. On a largescale Freebase+ClueWeb prediction task, we achieve 25% error reduction, and a 53% error reduction on sparse relations due to shared strength. On chains of reasoning in WordNet we reduce error in mean quantile by 84% versus previous state-of-the-art. The code and data are available at https://rajarshd.github.io/ChainsofReasoning
Bethe Projections for Non-Local Inference
Nov 28, 2016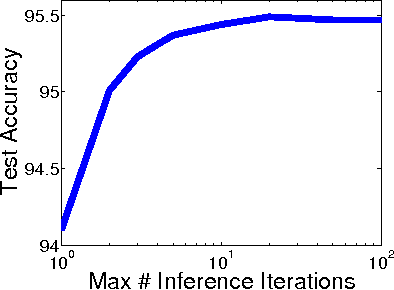

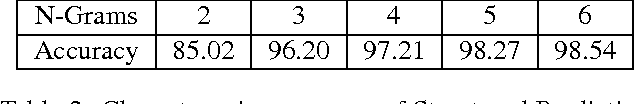
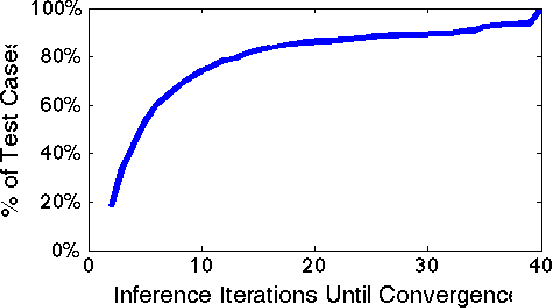
Many inference problems in structured prediction are naturally solved by augmenting a tractable dependency structure with complex, non-local auxiliary objectives. This includes the mean field family of variational inference algorithms, soft- or hard-constrained inference using Lagrangian relaxation or linear programming, collective graphical models, and forms of semi-supervised learning such as posterior regularization. We present a method to discriminatively learn broad families of inference objectives, capturing powerful non-local statistics of the latent variables, while maintaining tractable and provably fast inference using non-Euclidean projected gradient descent with a distance-generating function given by the Bethe entropy. We demonstrate the performance and flexibility of our method by (1) extracting structured citations from research papers by learning soft global constraints, (2) achieving state-of-the-art results on a widely-used handwriting recognition task using a novel learned non-convex inference procedure, and (3) providing a fast and highly scalable algorithm for the challenging problem of inference in a collective graphical model applied to bird migration.
Ask the GRU: Multi-Task Learning for Deep Text Recommendations
Sep 09, 2016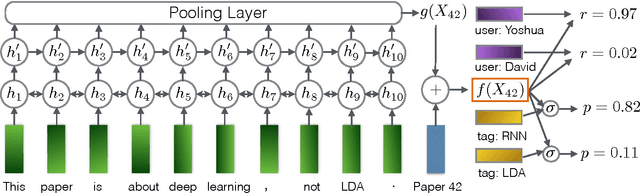
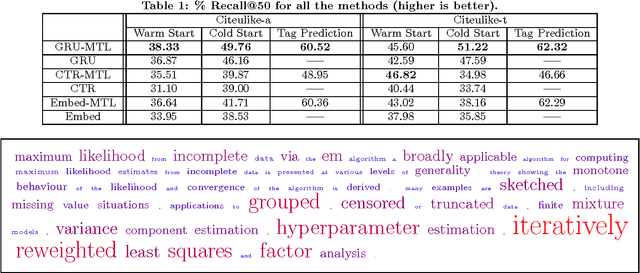

In a variety of application domains the content to be recommended to users is associated with text. This includes research papers, movies with associated plot summaries, news articles, blog posts, etc. Recommendation approaches based on latent factor models can be extended naturally to leverage text by employing an explicit mapping from text to factors. This enables recommendations for new, unseen content, and may generalize better, since the factors for all items are produced by a compactly-parametrized model. Previous work has used topic models or averages of word embeddings for this mapping. In this paper we present a method leveraging deep recurrent neural networks to encode the text sequence into a latent vector, specifically gated recurrent units (GRUs) trained end-to-end on the collaborative filtering task. For the task of scientific paper recommendation, this yields models with significantly higher accuracy. In cold-start scenarios, we beat the previous state-of-the-art, all of which ignore word order. Performance is further improved by multi-task learning, where the text encoder network is trained for a combination of content recommendation and item metadata prediction. This regularizes the collaborative filtering model, ameliorating the problem of sparsity of the observed rating matrix.
Structured Prediction Energy Networks
Jun 23, 2016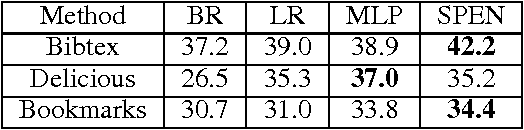
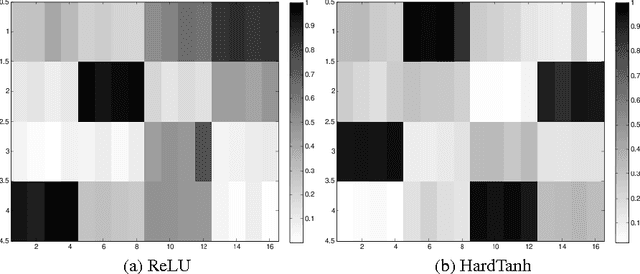

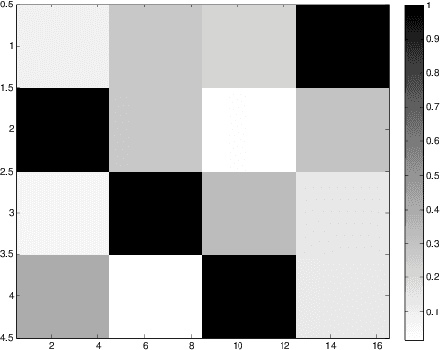
We introduce structured prediction energy networks (SPENs), a flexible framework for structured prediction. A deep architecture is used to define an energy function of candidate labels, and then predictions are produced by using back-propagation to iteratively optimize the energy with respect to the labels. This deep architecture captures dependencies between labels that would lead to intractable graphical models, and performs structure learning by automatically learning discriminative features of the structured output. One natural application of our technique is multi-label classification, which traditionally has required strict prior assumptions about the interactions between labels to ensure tractable learning and prediction. We are able to apply SPENs to multi-label problems with substantially larger label sets than previous applications of structured prediction, while modeling high-order interactions using minimal structural assumptions. Overall, deep learning provides remarkable tools for learning features of the inputs to a prediction problem, and this work extends these techniques to learning features of structured outputs. Our experiments provide impressive performance on a variety of benchmark multi-label classification tasks, demonstrate that our technique can be used to provide interpretable structure learning, and illuminate fundamental trade-offs between feed-forward and iterative structured prediction.
Multilingual Relation Extraction using Compositional Universal Schema
Mar 03, 2016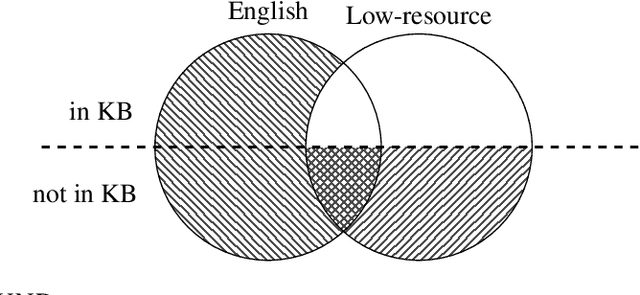

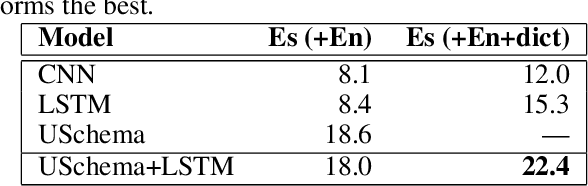

Universal schema builds a knowledge base (KB) of entities and relations by jointly embedding all relation types from input KBs as well as textual patterns expressing relations from raw text. In most previous applications of universal schema, each textual pattern is represented as a single embedding, preventing generalization to unseen patterns. Recent work employs a neural network to capture patterns' compositional semantics, providing generalization to all possible input text. In response, this paper introduces significant further improvements to the coverage and flexibility of universal schema relation extraction: predictions for entities unseen in training and multilingual transfer learning to domains with no annotation. We evaluate our model through extensive experiments on the English and Spanish TAC KBP benchmark, outperforming the top system from TAC 2013 slot-filling using no handwritten patterns or additional annotation. We also consider a multilingual setting in which English training data entities overlap with the seed KB, but Spanish text does not. Despite having no annotation for Spanish data, we train an accurate predictor, with additional improvements obtained by tying word embeddings across languages. Furthermore, we find that multilingual training improves English relation extraction accuracy. Our approach is thus suited to broad-coverage automated knowledge base construction in a variety of languages and domains.
A Linear Dynamical System Model for Text
May 31, 2015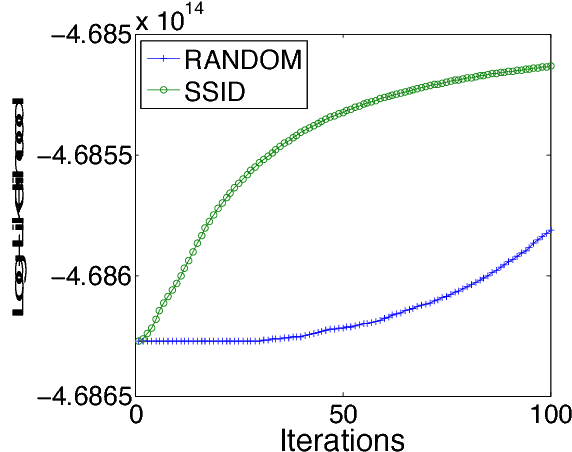
Low dimensional representations of words allow accurate NLP models to be trained on limited annotated data. While most representations ignore words' local context, a natural way to induce context-dependent representations is to perform inference in a probabilistic latent-variable sequence model. Given the recent success of continuous vector space word representations, we provide such an inference procedure for continuous states, where words' representations are given by the posterior mean of a linear dynamical system. Here, efficient inference can be performed using Kalman filtering. Our learning algorithm is extremely scalable, operating on simple cooccurrence counts for both parameter initialization using the method of moments and subsequent iterations of EM. In our experiments, we employ our inferred word embeddings as features in standard tagging tasks, obtaining significant accuracy improvements. Finally, the Kalman filter updates can be seen as a linear recurrent neural network. We demonstrate that using the parameters of our model to initialize a non-linear recurrent neural network language model reduces its training time by a day and yields lower perplexity.
Bethe Learning of Conditional Random Fields via MAP Decoding
Mar 04, 2015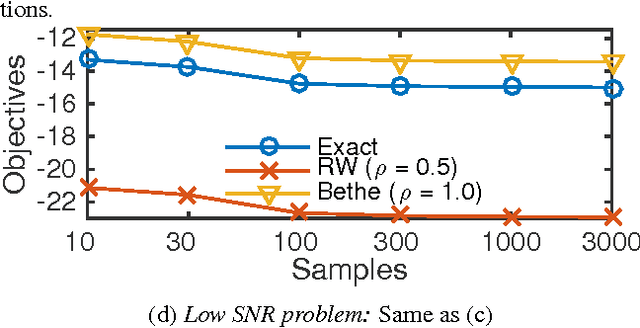

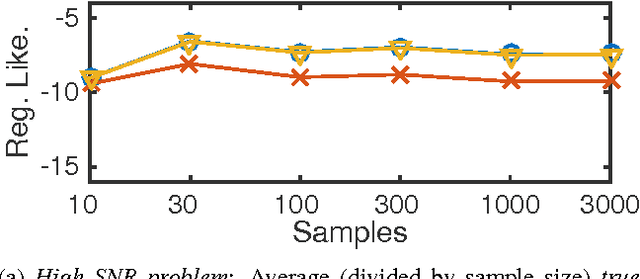
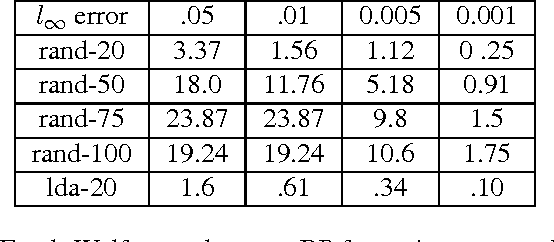
Many machine learning tasks can be formulated in terms of predicting structured outputs. In frameworks such as the structured support vector machine (SVM-Struct) and the structured perceptron, discriminative functions are learned by iteratively applying efficient maximum a posteriori (MAP) decoding. However, maximum likelihood estimation (MLE) of probabilistic models over these same structured spaces requires computing partition functions, which is generally intractable. This paper presents a method for learning discrete exponential family models using the Bethe approximation to the MLE. Remarkably, this problem also reduces to iterative (MAP) decoding. This connection emerges by combining the Bethe approximation with a Frank-Wolfe (FW) algorithm on a convex dual objective which circumvents the intractable partition function. The result is a new single loop algorithm MLE-Struct, which is substantially more efficient than previous double-loop methods for approximate maximum likelihood estimation. Our algorithm outperforms existing methods in experiments involving image segmentation, matching problems from vision, and a new dataset of university roommate assignments.