 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level Residual Networks from Dynamical Systems View
Feb 01, 2018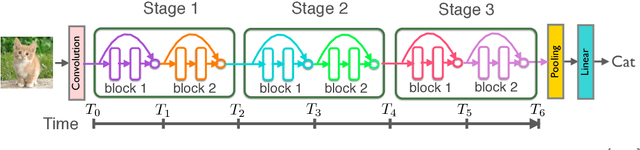


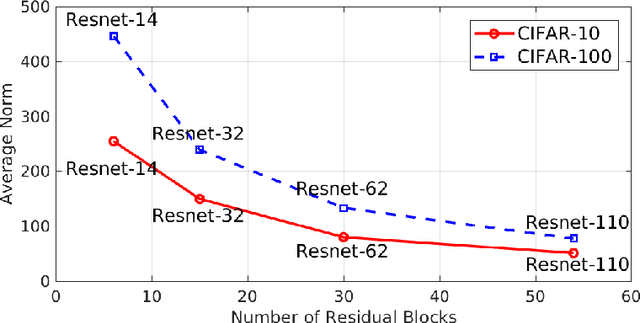
Deep residual networks (ResNets) and their variants are widely used in many computer vision applications and natural language processing tasks. However, the theoretical principles for designing and training ResNets are still not fully understood. Recently, several points of view have emerged to try to interpret ResNet theoretically, such as unraveled view, unrolled iterative estimation and dynamical systems view. In this paper, we adopt the dynamical systems point of view, and analyze the lesioning properties of ResNet both theoretically and experimentally. Based on these analyses, we additionally propose a novel method for accelerating ResNet training. We apply the proposed method to train ResNets and Wide ResNets for three image classification benchmarks, reducing training time by more than 40% with superior or on-par accuracy.
Reversible Architectures for Arbitrarily Deep Residual Neural Networks
Nov 18, 2017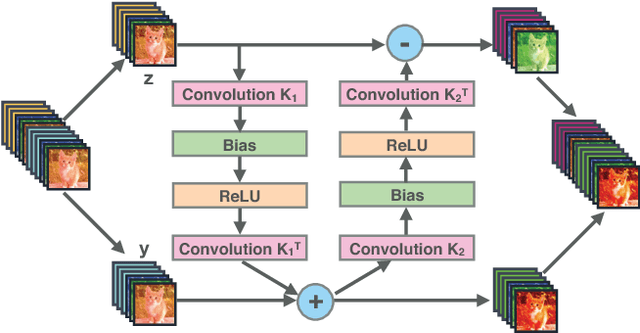
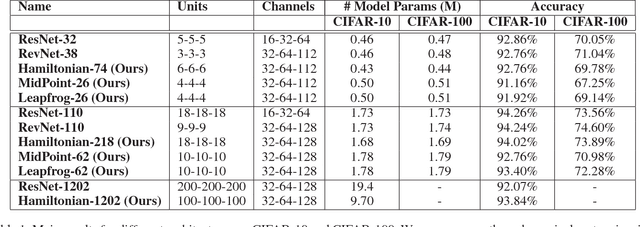


Recently, deep residual networks have been successfully applied in many computer vision and natural language processing tasks, pushing the state-of-the-art performance with deeper and wider architectures. In this work, we interpret deep residual networks as ordinary differential equations (ODEs), which have long been studied in mathematics and physics with rich theoretical and empirical success. From this interpretation, we develop a theoretical framework on stability and reversibility of deep neural networks, and derive three reversible neural network architectures that can go arbitrarily deep in theory. The reversibility property allows a memory-efficient implementation, which does not need to store the activations for most hidden layers. Together with the stability of our architectures, this enables training deeper networks using only modest computational resources. We provide both theoretical analyses and empirical results. Experimental results demonstrate the efficacy of our architectures against several strong baselines on CIFAR-10, CIFAR-100 and STL-10 with superior or on-par state-of-the-art performance. Furthermore, we show our architectures yield superior results when trained using fewer training data.