 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalization via Invariant Feature Representation
Jan 10, 2013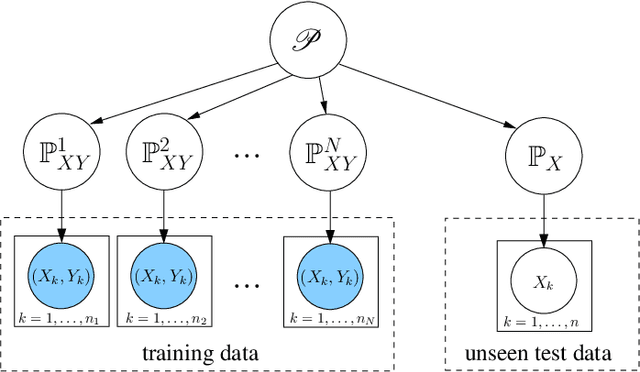
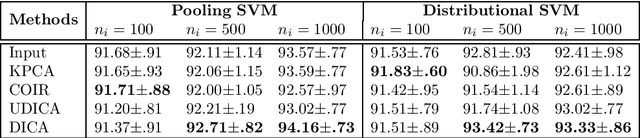
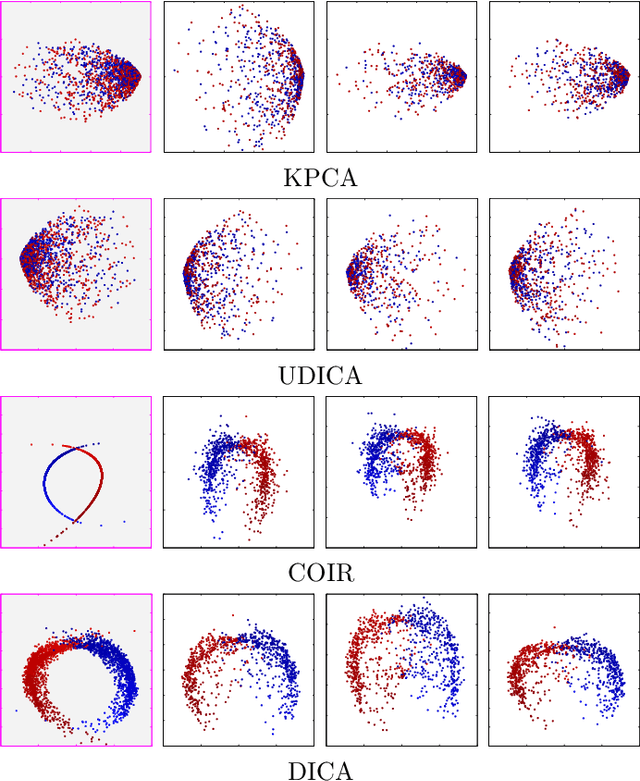
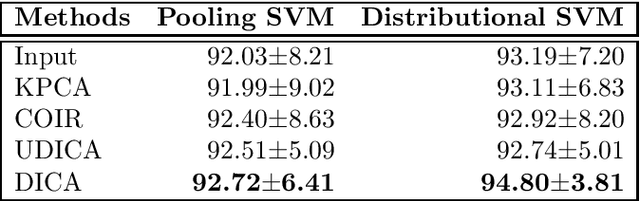
This paper investigates domain generalization: How to take knowledge acquired from an arbitrary number of related domains and apply it to previously unseen domains? We propose Domain-Invariant Component Analysis (DICA), a kernel-based optimization algorithm that learns an invariant transformation by minimizing the dissimilarity across domains, whilst preserving the functional relationship between input and output variables. A learning-theoretic analysis shows that reducing dissimilarity improves the expected generalization ability of classifiers on new domains, motivating the proposed algorithm. Experimental results on synthetic and real-world datasets demonstrate that DICA successfully learns invariant features and improves classifier performance in practice.
A Nonparametric Conjugate Prior Distribution for the Maximizing Argument of a Noisy Function
Nov 10, 2012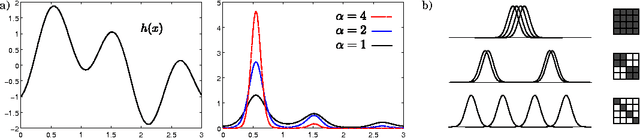
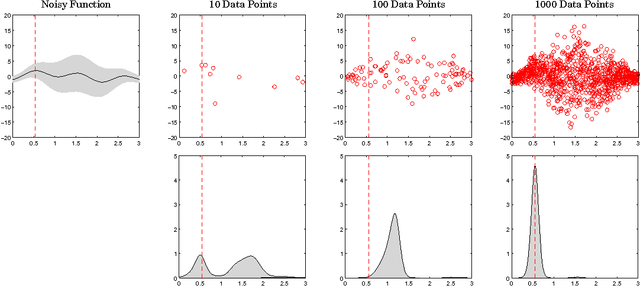
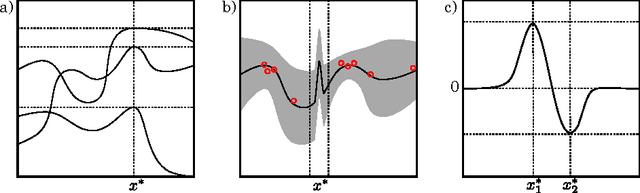

We propose a novel Bayesian approach to solve stochastic optimization problems that involve finding extrema of noisy, nonlinear functions. Previous work has focused on representing possible functions explicitly, which leads to a two-step procedure of first, doing inference over the function space and second, finding the extrema of these functions. Here we skip the representation step and directly model the distribution over extrema. To this end, we devise a non-parametric conjugate prior based on a kernel regressor. The resulting posterior distribution directly captures the uncertainty over the maximum of the unknown function. We illustrate the effectiveness of our model by optimizing a noisy, high-dimensional, non-convex objective function.
* 9 pages, 5 figures
Regulating the information in spikes: a useful bias
Oct 17, 2012The bias/variance tradeoff is fundamental to learning: increasing a model's complexity can improve its fit on training data, but potentially worsens performance on future samples. Remarkably, however, the human brain effortlessly handles a wide-range of complex pattern recognition tasks. On the basis of these conflicting observations, it has been argued that useful biases in the form of "generic mechanisms for representation" must be hardwired into cortex (Geman et al). This note describes a useful bias that encourages cooperative learning which is both biologically plausible and rigorously justified.
Towards a learning-theoretic analysis of spike-timing dependent plasticity
Sep 25, 2012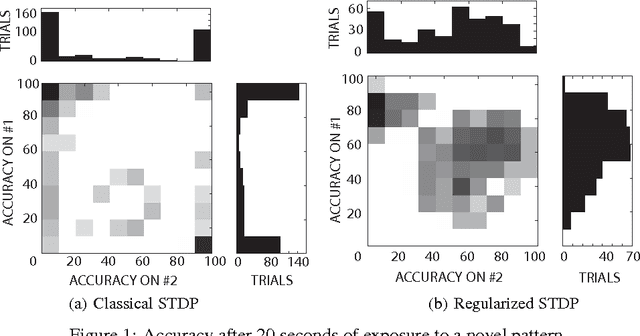
This paper suggests a learning-theoretic perspective on how synaptic plasticity benefits global brain functioning. We introduce a model, the selectron, that (i) arises as the fast time constant limit of leaky integrate-and-fire neurons equipped with spiking timing dependent plasticity (STDP) and (ii) is amenable to theoretical analysis. We show that the selectron encodes reward estimates into spikes and that an error bound on spikes is controlled by a spiking margin and the sum of synaptic weights. Moreover, the efficacy of spikes (their usefulness to other reward maximizing selectrons) also depends on total synaptic strength. Finally, based on our analysis, we propose a regularized version of STDP, and show the regularization improves the robustness of neuronal learning when faced with multiple stimuli.
On the information-theoretic structure of distributed measurements
Jul 31, 2012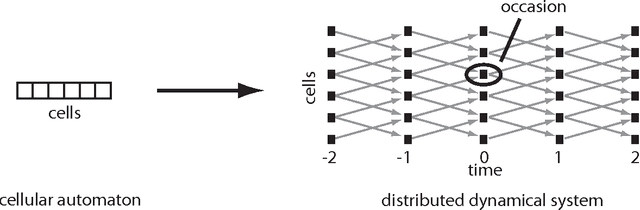
The internal structure of a measuring device, which depends on what its components are and how they are organized, determines how it categorizes its inputs. This paper presents a geometric approach to studying the internal structure of measurements performed by distributed systems such as probabilistic cellular automata. It constructs the quale, a family of sections of a suitably defined presheaf, whose elements correspond to the measurements performed by all subsystems of a distributed system. Using the quale we quantify (i) the information generated by a measurement; (ii) the extent to which a measurement is context-dependent; and (iii) whether a measurement is decomposable into independent submeasurements, which turns out to be equivalent to context-dependence. Finally, we show that only indecomposable measurements are more informative than the sum of their submeasurements.
* In Proceedings DCM 2011, arXiv:1207.6821
Information, learning and falsification
Nov 28, 2011There are (at least) three approaches to quantifying information. The first, algorithmic information or Kolmogorov complexity, takes events as strings and, given a universal Turing machine, quantifies the information content of a string as the length of the shortest program producing it. The second, Shannon information, takes events as belonging to ensembles and quantifies the information resulting from observing the given event in terms of the number of alternate events that have been ruled out. The third, statistical learning theory, has introduced measures of capacity that control (in part) the expected risk of classifiers. These capacities quantify the expectations regarding future data that learning algorithms embed into classifiers. This note describes a new method of quantifying information, effective information, that links algorithmic information to Shannon information, and also links both to capacities arising in statistical learning theory. After introducing the measure, we show that it provides a non-universal analog of Kolmogorov complexity. We then apply it to derive basic capacities in statistical learning theory: empirical VC-entropy and empirical Rademacher complexity. A nice byproduct of our approach is an interpretation of the explanatory power of a learning algorithm in terms of the number of hypotheses it falsifies, counted in two different ways for the two capacities. We also discuss how effective information relates to information gain, Shannon and mutual information.
Falsification and future performance
Nov 23, 2011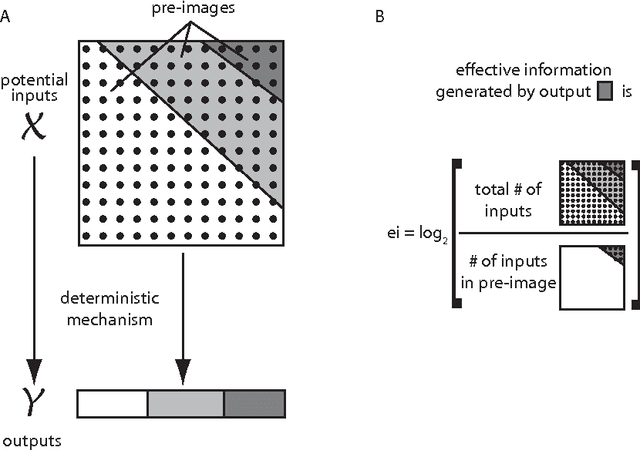
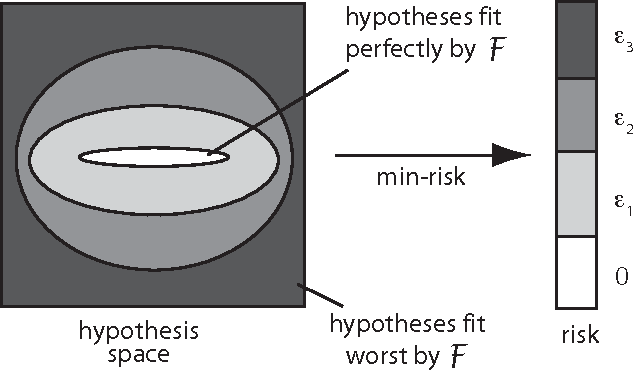
We information-theoretically reformulate two measures of capacity from statistical learning theory: empirical VC-entropy and empirical Rademacher complexity. We show these capacity measures count the number of hypotheses about a dataset that a learning algorithm falsifies when it finds the classifier in its repertoire minimizing empirical risk. It then follows from that the future performance of predictors on unseen data is controlled in part by how many hypotheses the learner falsifies. As a corollary we show that empirical VC-entropy quantifies the message length of the true hypothesis in the optimal code of a particular probability distribution, the so-called actual repertoire.