 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap: A Framework for Real-World Video Deepfake Detection via Social Network Compression Emulation
Aug 12, 2025The growing presence of AI-generated videos on social networks poses new challenges for deepfake detection, as detectors trained under controlled conditions often fail to generalize to real-world scenarios. A key factor behind this gap is the aggressive, proprietary compression applied by platforms like YouTube and Facebook, which launder low-level forensic cues. However, replicating these transformations at scale is difficult due to API limitations and data-sharing constraints. For these reasons, we propose a first framework that emulates the video sharing pipelines of social networks by estimating compression and resizing parameters from a small set of uploaded videos. These parameters enable a local emulator capable of reproducing platform-specific artifacts on large datasets without direct API access. Experiments on FaceForensics++ videos shared via social networks demonstrate that our emulated data closely matches the degradation patterns of real uploads. Furthermore, detectors fine-tuned on emulated videos achieve comparable performance to those trained on actual shared media. Our approach offers a scalable and practical solution for bridging the gap between lab-based training and real-world deployment of deepfake detectors, particularly in the underexplored domain of compressed video content.
DRAGON: A Large-Scale Dataset of Realistic Images Generated by Diffusion Models
May 16, 2025The remarkable ease of use of diffusion models for image generation has led to a proliferation of synthetic content online. While these models are often employed for legitimate purposes, they are also used to generate fake images that support misinformation and hate speech. Consequently, it is crucial to develop robust tools capable of detecting whether an image has been generated by such models. Many current detection methods, however, require large volumes of sample images for training. Unfortunately, due to the rapid evolution of the field, existing datasets often cover only a limited range of models and quickly become outdated. In this work, we introduce DRAGON, a comprehensive dataset comprising images from 25 diffusion models, spanning both recent advancements and older, well-established architectures. The dataset contains a broad variety of images representing diverse subjects. To enhance image realism, we propose a simple yet effective pipeline that leverages a large language model to expand input prompts, thereby generating more diverse and higher-quality outputs, as evidenced by improvements in standard quality metrics. The dataset is provided in multiple sizes (ranging from extra-small to extra-large) to accomodate different research scenarios. DRAGON is designed to support the forensic community in developing and evaluating detection and attribution techniques for synthetic content. Additionally, the dataset is accompanied by a dedicated test set, intended to serve as a benchmark for assessing the performance of newly developed methods.
Efficient video integrity analysis through container characterization
Jan 26, 2021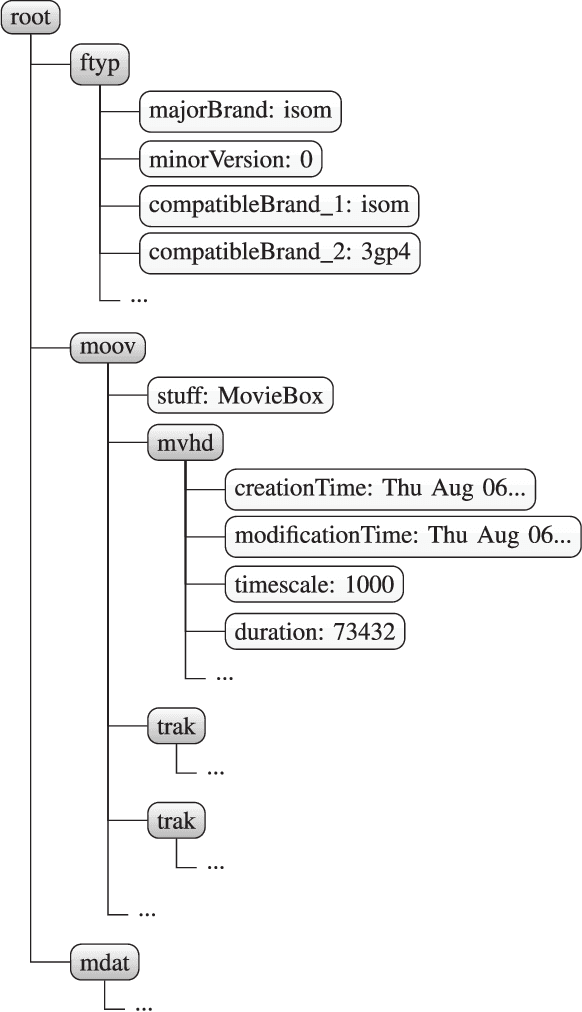
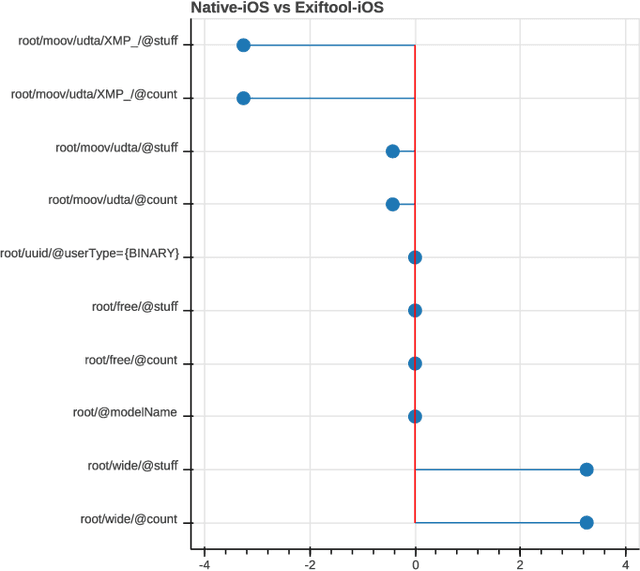
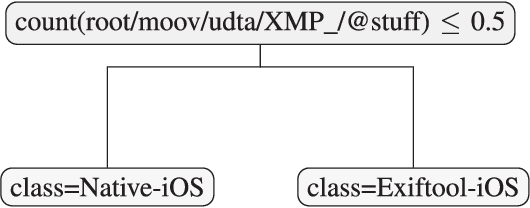
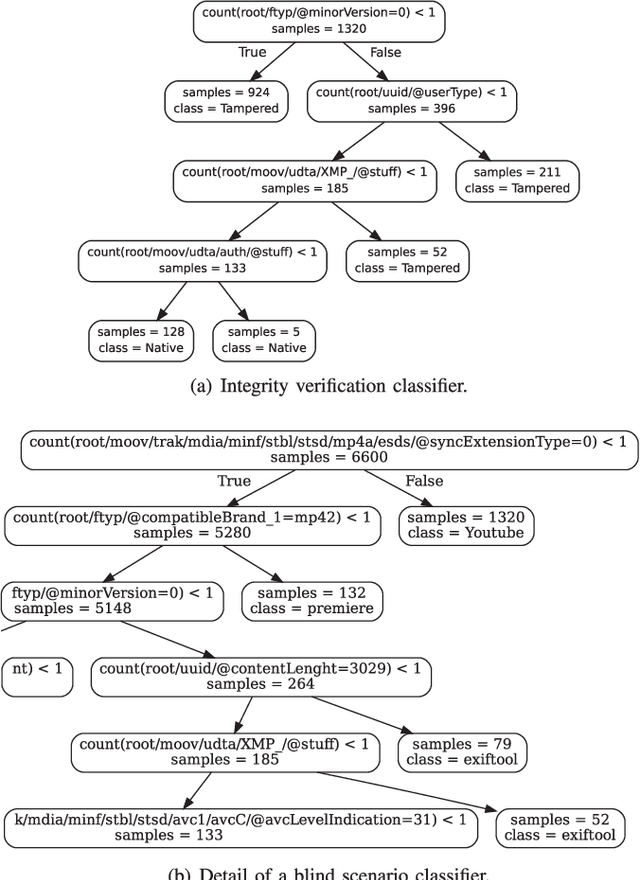
Most video forensic techniques look for traces within the data stream that are, however, mostly ineffective when dealing with strongly compressed or low resolution videos. Recent research highlighted that useful forensic traces are also left in the video container structure, thus offering the opportunity to understand the life-cycle of a video file without looking at the media stream itself. In this paper we introduce a container-based method to identify the software used to perform a video manipulation and, in most cases, the operating system of the source device. As opposed to the state of the art, the proposed method is both efficient and effective and can also provide a simple explanation for its decisions. This is achieved by using a decision-tree-based classifier applied to a vectorial representation of the video container structure. We conducted an extensive validation on a dataset of 7000 video files including both software manipulated contents (ffmpeg, Exiftool, Adobe Premiere, Avidemux, and Kdenlive), and videos exchanged through social media platforms (Facebook, TikTok, Weibo and YouTube). This dataset has been made available to the research community. The proposed method achieves an accuracy of 97.6% in distinguishing pristine from tampered videos and classifying the editing software, even when the video is cut without re-encoding or when it is downscaled to the size of a thumbnail. Furthermore, it is capable of correctly identifying the operating system of the source device for most of the tampered videos.
* Accepted by IEEE Journal of Selected Topics in Signal Processing