 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mean Field Theory of Quantized Deep Networks: The Quantization-Depth Trade-Off
Jun 03, 2019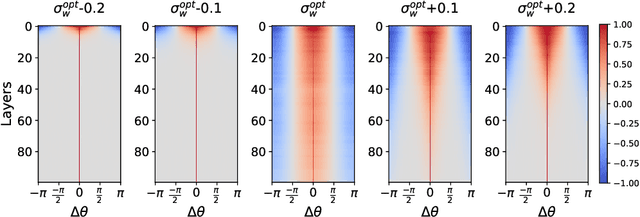
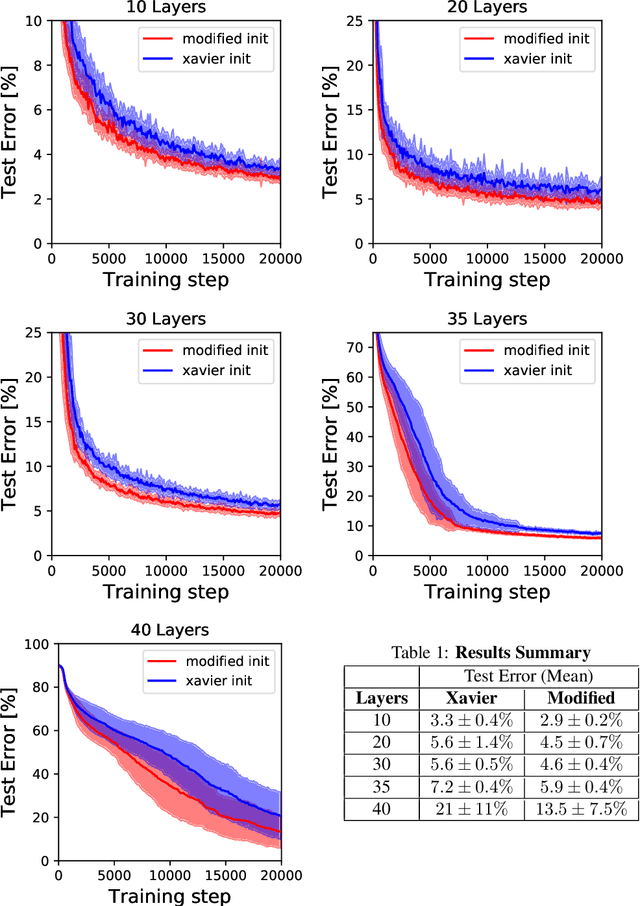
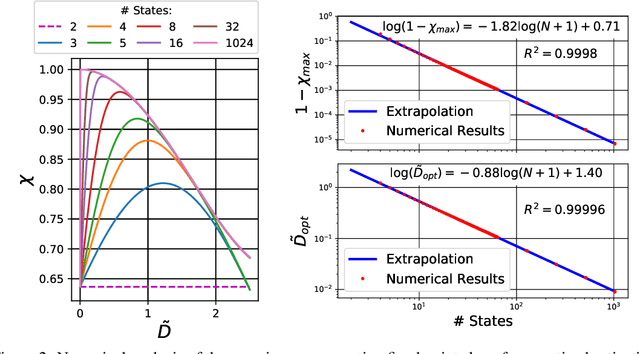
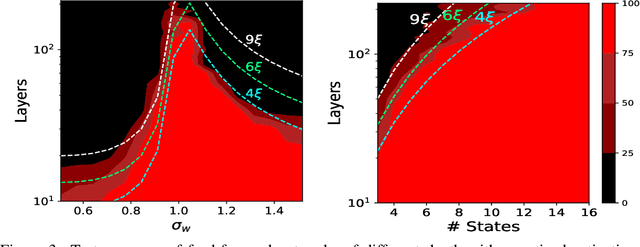
Reducing the precision of weights and activation functions in neural network training, with minimal impact on performance, is essential for the deployment of these models in resource-constrained environments. We apply mean-field techniques to networks with quantized activations in order to evaluate the degree to which quantization degrades signal propagation at initialization. We derive initialization schemes which maximize signal propagation in such networks and suggest why this is helpful for generalization. Building on these results, we obtain a closed form implicit equation for $L_{\max}$, the maximal trainable depth (and hence model capacity), given $N$, the number of quantization levels in the activation function. Solving this equation numerically, we obtain asymptotically: $L_{\max}\propto N^{1.82}$.
Dynamical Isometry and a Mean Field Theory of LSTMs and GRUs
Jan 25, 2019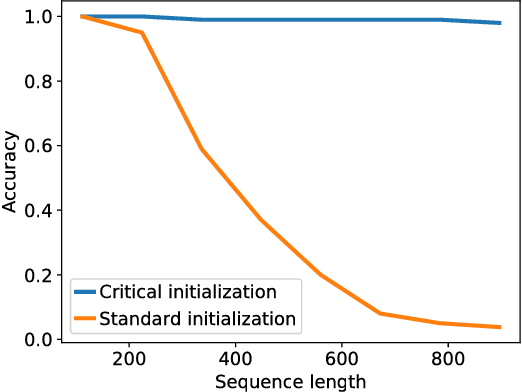

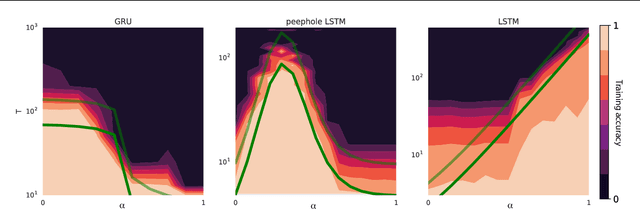

Training recurrent neural networks (RNNs) on long sequence tasks is plagued with difficulties arising from the exponential explosion or vanishing of signals as they propagate forward or backward through the network. Many techniques have been proposed to ameliorate these issues, including various algorithmic and architectural modifications. Two of the most successful RNN architectures, the LSTM and the GRU, do exhibit modest improvements over vanilla RNN cells, but they still suffer from instabilities when trained on very long sequences. In this work, we develop a mean field theory of signal propagation in LSTMs and GRUs that enables us to calculate the time scales for signal propagation as well as the spectral properties of the state-to-state Jacobians. By optimizing these quantities in terms of the initialization hyperparameters, we derive a novel initialization scheme that eliminates or reduces training instabilities. We demonstrate the efficacy of our initialization scheme on multiple sequence tasks, on which it enables successful training while a standard initialization either fails completely or is orders of magnitude slower. We also observe a beneficial effect on generalization performance using this new initialization.
Stochastic Bouncy Particle Sampler
Jun 14, 2017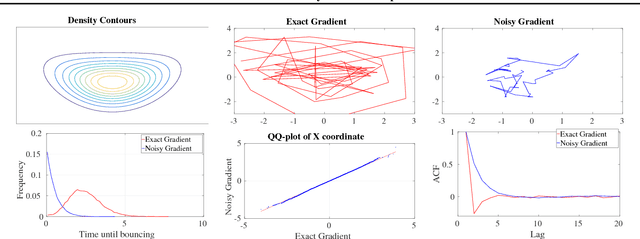
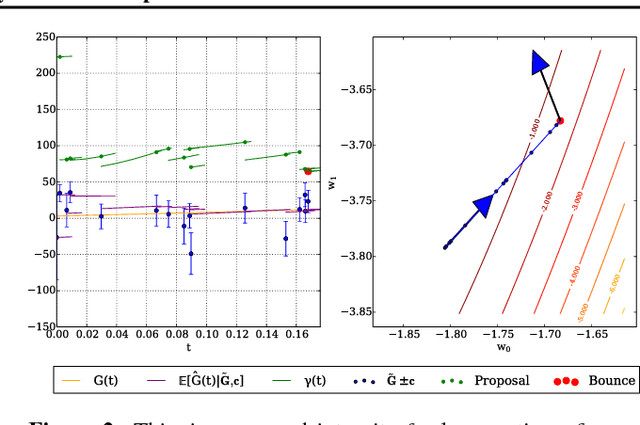
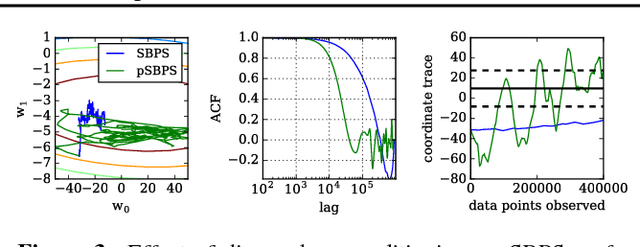
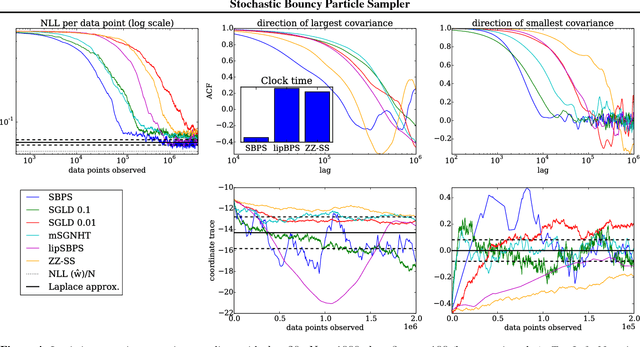
We introduce a novel stochastic version of the non-reversible, rejection-free Bouncy Particle Sampler (BPS), a Markov process whose sample trajectories are piecewise linear. The algorithm is based on simulating first arrival times in a doubly stochastic Poisson process using the thinning method, and allows efficient sampling of Bayesian posteriors in big datasets. We prove that in the BPS no bias is introduced by noisy evaluations of the log-likelihood gradient. On the other hand, we argue that efficiency considerations favor a small, controllable bias in the construction of the thinning proposals, in exchange for faster mixing. We introduce a simple regression-based proposal intensity for the thinning method that controls this trade-off. We illustrate the algorithm in several examples in which it outperforms both unbiased, but slowly mixing stochastic versions of BPS, as well as biased stochastic gradient-based samplers.