 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Wish I Would Have Loved This One, But I Didn't -- A Multilingual Dataset for Counterfactual Detection in Product Reviews
Apr 14, 2021
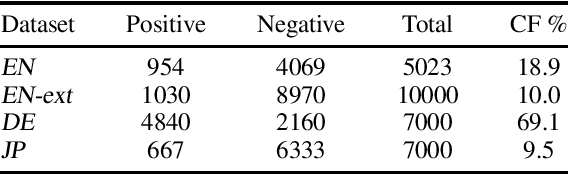

Counterfactual statements describe events that did not or cannot take place. We consider the problem of counterfactual detection (CFD) in product reviews. For this purpose, we annotate a multilingual CFD dataset from Amazon product reviews covering counterfactual statements written in English, German, and Japanese languages. The dataset is unique as it contains counterfactuals in multiple languages, covers a new application area of e-commerce reviews, and provides high quality professional annotations. We train CFD models using different text representation methods and classifiers. We find that these models are robust against the selectional biases introduced due to cue phrase-based sentence selection. Moreover, our CFD dataset is compatible with prior datasets and can be merged to learn accurate CFD models. Applying machine translation on English counterfactual examples to create multilingual data performs poorly, demonstrating the language-specificity of this problem, which has been ignored so far.
Semantically-Conditioned Negative Samples for Efficient Contrastive Learning
Feb 12, 2021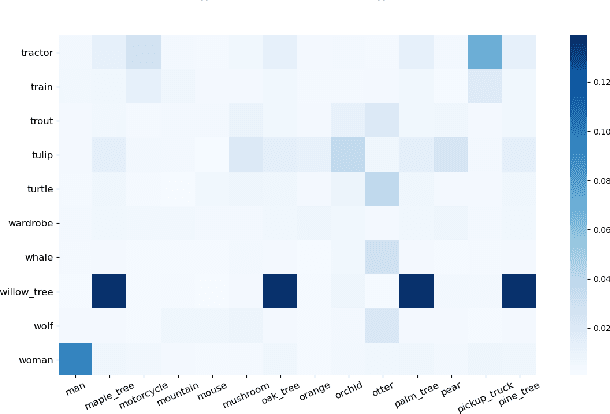
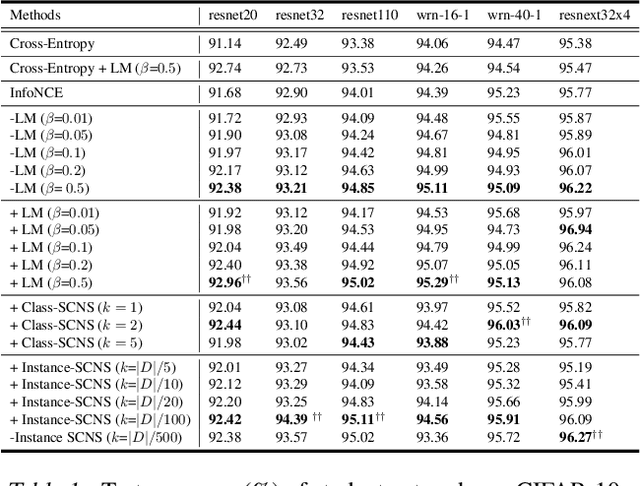
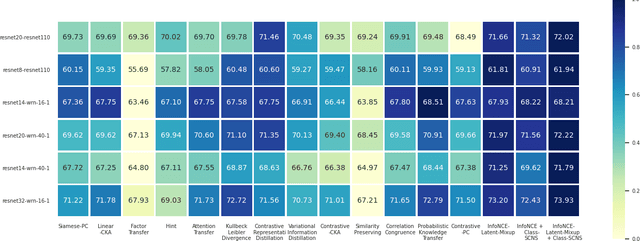
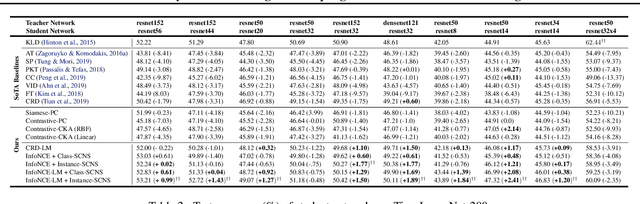
Negative sampling is a limiting factor w.r.t. the generalization of metric-learned neural networks. We show that uniform negative sampling provides little information about the class boundaries and thus propose three novel techniques for efficient negative sampling: drawing negative samples from (1) the top-$k$ most semantically similar classes, (2) the top-$k$ most semantically similar samples and (3) interpolating between contrastive latent representations to create pseudo negatives. Our experiments on CIFAR-10, CIFAR-100 and Tiny-ImageNet-200 show that our proposed \textit{Semantically Conditioned Negative Sampling} and Latent Mixup lead to consistent performance improvements. In the standard supervised learning setting, on average we increase test accuracy by 1.52\% percentage points on CIFAR-10 across various network architectures. In the knowledge distillation setting, (1) the performance of student networks increase by 4.56\% percentage points on Tiny-ImageNet-200 and 3.29\% on CIFAR-100 over student networks trained with no teacher and (2) 1.23\% and 1.72\% respectively over a \textit{hard-to-beat} baseline (Hinton et al., 2015).
RelWalk A Latent Variable Model Approach to Knowledge Graph Embedding
Jan 25, 2021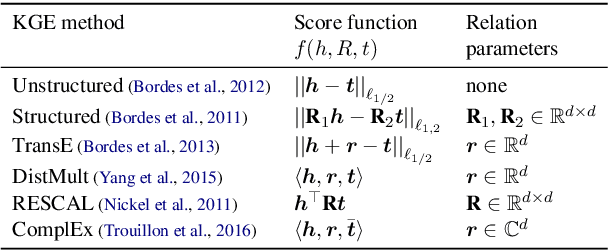
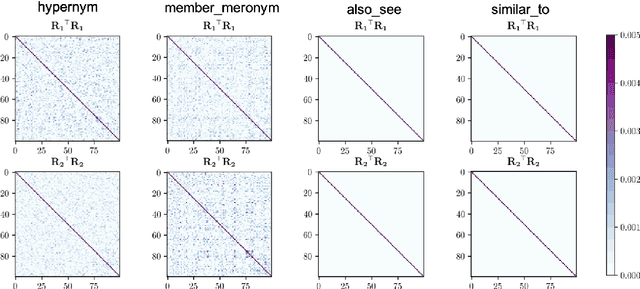
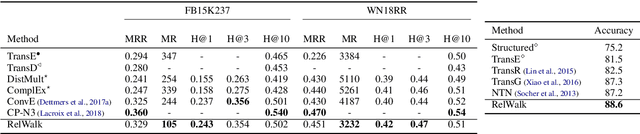
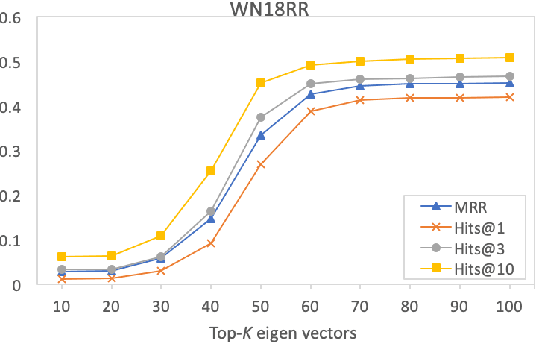
Embedding entities and relations of a knowledge graph in a low-dimensional space has shown impressive performance in predicting missing links between entities. Although progresses have been achieved, existing methods are heuristically motivated and theoretical understanding of such embeddings is comparatively underdeveloped. This paper extends the random walk model (Arora et al., 2016a) of word embeddings to Knowledge Graph Embeddings (KGEs) to derive a scoring function that evaluates the strength of a relation R between two entities h (head) and t (tail). Moreover, we show that marginal loss minimisation, a popular objective used in much prior work in KGE, follows naturally from the log-likelihood ratio maximisation under the probabilities estimated from the KGEs according to our theoretical relationship. We propose a learning objective motivated by the theoretical analysis to learn KGEs from a given knowledge graph. Using the derived objective, accurate KGEs are learnt from FB15K237 and WN18RR benchmark datasets, providing empirical evidence in support of the theory.
Dictionary-based Debiasing of Pre-trained Word Embeddings
Jan 23, 2021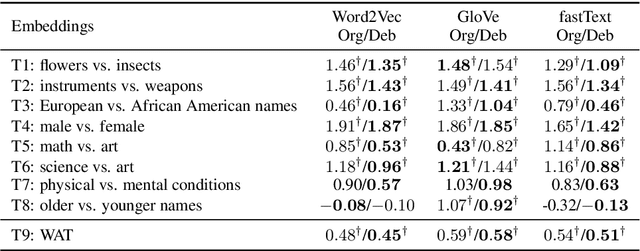
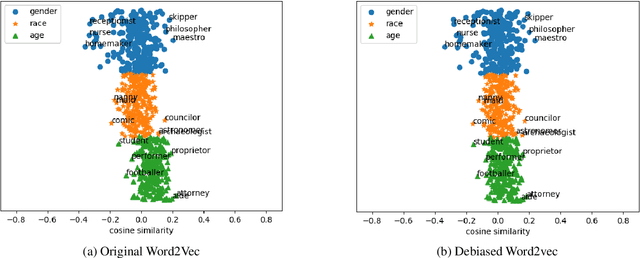
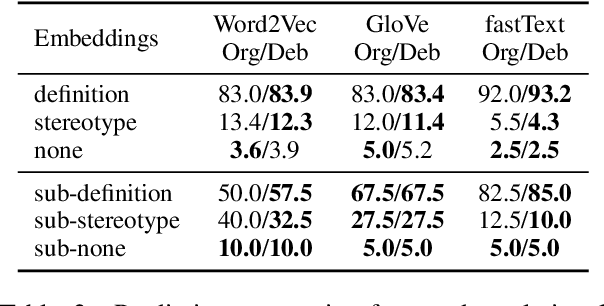
Word embeddings trained on large corpora have shown to encode high levels of unfair discriminatory gender, racial, religious and ethnic biases. In contrast, human-written dictionaries describe the meanings of words in a concise, objective and an unbiased manner. We propose a method for debiasing pre-trained word embeddings using dictionaries, without requiring access to the original training resources or any knowledge regarding the word embedding algorithms used. Unlike prior work, our proposed method does not require the types of biases to be pre-defined in the form of word lists, and learns the constraints that must be satisfied by unbiased word embeddings automatically from dictionary definitions of the words. Specifically, we learn an encoder to generate a debiased version of an input word embedding such that it (a) retains the semantics of the pre-trained word embeddings, (b) agrees with the unbiased definition of the word according to the dictionary, and (c) remains orthogonal to the vector space spanned by any biased basis vectors in the pre-trained word embedding space. Experimental results on standard benchmark datasets show that the proposed method can accurately remove unfair biases encoded in pre-trained word embeddings, while preserving useful semantics.
Debiasing Pre-trained Contextualised Embeddings
Jan 23, 2021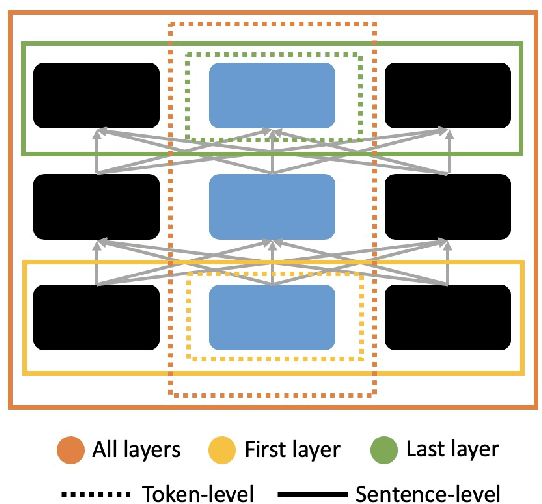
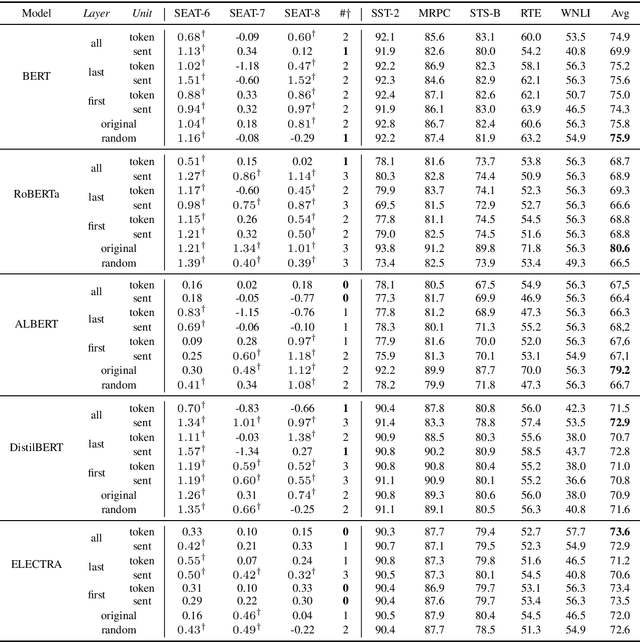
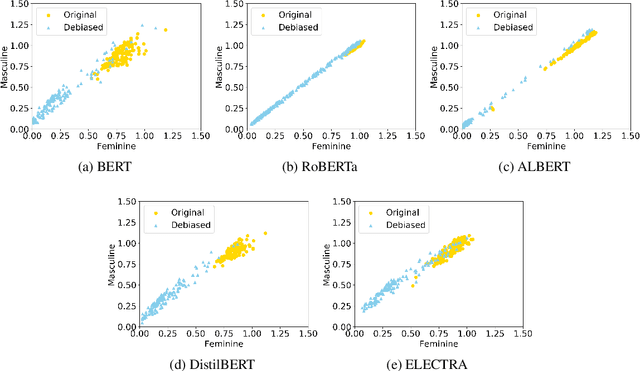
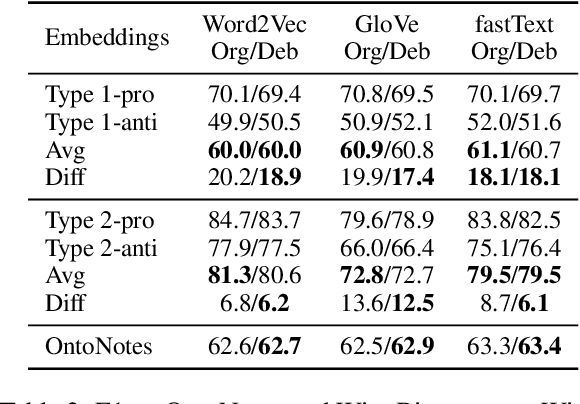
In comparison to the numerous debiasing methods proposed for the static non-contextualised word embeddings, the discriminative biases in contextualised embeddings have received relatively little attention. We propose a fine-tuning method that can be applied at token- or sentence-levels to debias pre-trained contextualised embeddings. Our proposed method can be applied to any pre-trained contextualised embedding model, without requiring to retrain those models. Using gender bias as an illustrative example, we then conduct a systematic study using several state-of-the-art (SoTA) contextualised representations on multiple benchmark datasets to evaluate the level of biases encoded in different contextualised embeddings before and after debiasing using the proposed method. We find that applying token-level debiasing for all tokens and across all layers of a contextualised embedding model produces the best performance. Interestingly, we observe that there is a trade-off between creating an accurate vs. unbiased contextualised embedding model, and different contextualised embedding models respond differently to this trade-off.
$k$-Neighbor Based Curriculum Sampling for Sequence Prediction
Jan 22, 2021
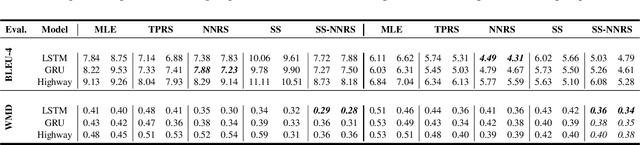
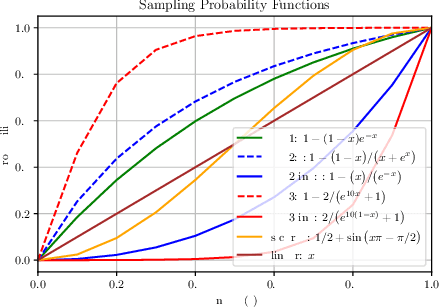
Multi-step ahead prediction in language models is challenging due to the discrepancy between training and test time processes. At test time, a sequence predictor is required to make predictions given past predictions as the input, instead of the past targets that are provided during training. This difference, known as exposure bias, can lead to the compounding of errors along a generated sequence at test time. To improve generalization in neural language models and address compounding errors, we propose \textit{Nearest-Neighbor Replacement Sampling} -- a curriculum learning-based method that gradually changes an initially deterministic teacher policy to a stochastic policy. A token at a given time-step is replaced with a sampled nearest neighbor of the past target with a truncated probability proportional to the cosine similarity between the original word and its top $k$ most similar words. This allows the learner to explore alternatives when the current policy provided by the teacher is sub-optimal or difficult to learn from. The proposed method is straightforward, online and requires little additional memory requirements. We report our findings on two language modelling benchmarks and find that the proposed method further improves performance when used in conjunction with scheduled sampling.
Autoencoding Improves Pre-trained Word Embeddings
Oct 27, 2020
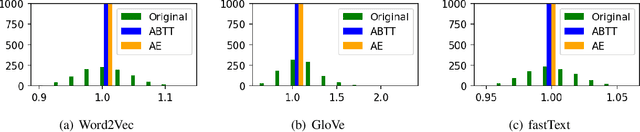
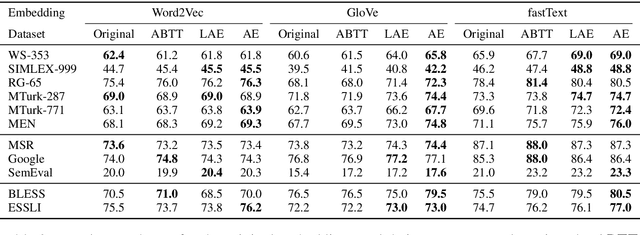
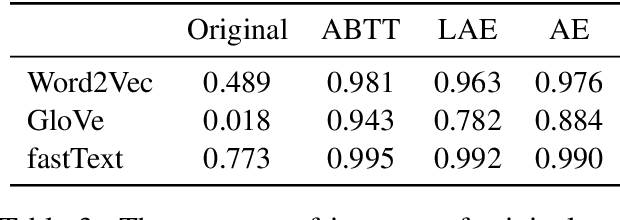
Prior work investigating the geometry of pre-trained word embeddings have shown that word embeddings to be distributed in a narrow cone and by centering and projecting using principal component vectors one can increase the accuracy of a given set of pre-trained word embeddings. However, theoretically, this post-processing step is equivalent to applying a linear autoencoder to minimise the squared l2 reconstruction error. This result contradicts prior work (Mu and Viswanath, 2018) that proposed to remove the top principal components from pre-trained embeddings. We experimentally verify our theoretical claims and show that retaining the top principal components is indeed useful for improving pre-trained word embeddings, without requiring access to additional linguistic resources or labelled data.
Spatio-temporal Attention Model for Tactile Texture Recognition
Aug 10, 2020



Recently, tactile sensing has attracted great interest in robotics, especially for facilitating exploration of unstructured environments and effective manipulation. A detailed understanding of the surface textures via tactile sensing is essential for many of these tasks. Previous works on texture recognition using camera based tactile sensors have been limited to treating all regions in one tactile image or all samples in one tactile sequence equally, which includes much irrelevant or redundant information. In this paper, we propose a novel Spatio-Temporal Attention Model (STAM) for tactile texture recognition, which is the very first of its kind to our best knowledge. The proposed STAM pays attention to both spatial focus of each single tactile texture and the temporal correlation of a tactile sequence. In the experiments to discriminate 100 different fabric textures, the spatially and temporally selective attention has resulted in a significant improvement of the recognition accuracy, by up to 18.8%, compared to the non-attention based models. Specifically, after introducing noisy data that is collected before the contact happens, our proposed STAM can learn the salient features efficiently and the accuracy can increase by 15.23% on average compared with the CNN based baseline approach. The improved tactile texture perception can be applied to facilitate robot tasks like grasping and manipulation.
Do not let the history haunt you -- Mitigating Compounding Errors in Conversational Question Answering
May 12, 2020
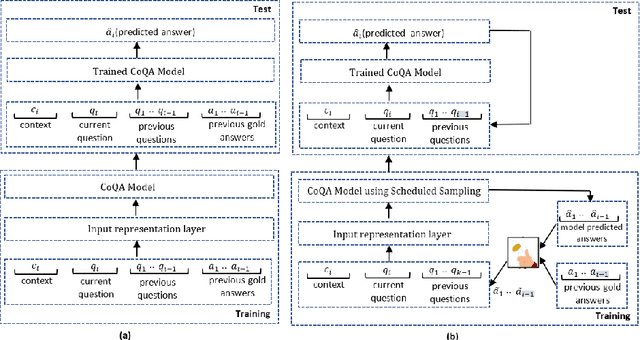

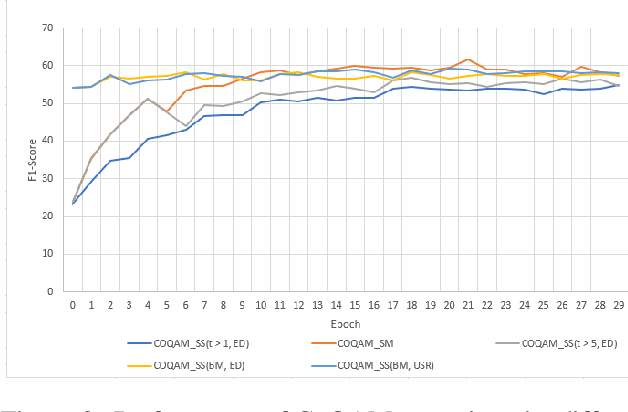
The Conversational Question Answering (CoQA) task involves answering a sequence of inter-related conversational questions about a contextual paragraph. Although existing approaches employ human-written ground-truth answers for answering conversational questions at test time, in a realistic scenario, the CoQA model will not have any access to ground-truth answers for the previous questions, compelling the model to rely upon its own previously predicted answers for answering the subsequent questions. In this paper, we find that compounding errors occur when using previously predicted answers at test time, significantly lowering the performance of CoQA systems. To solve this problem, we propose a sampling strategy that dynamically selects between target answers and model predictions during training, thereby closely simulating the situation at test time. Further, we analyse the severity of this phenomena as a function of the question type, conversation length and domain type.
Weakly-Supervised Neural Response Selection from an Ensemble of Task-Specialised Dialogue Agents
May 06, 2020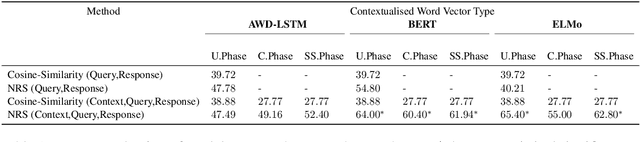
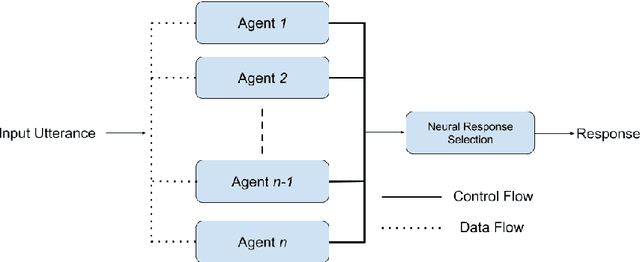
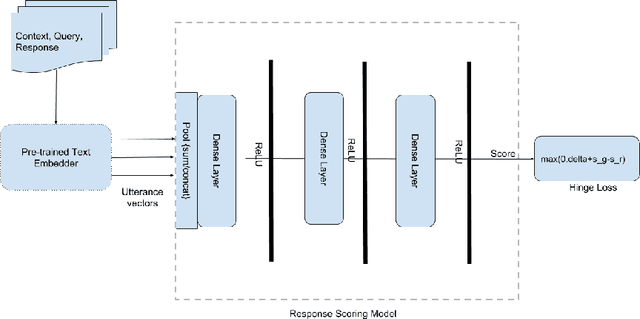
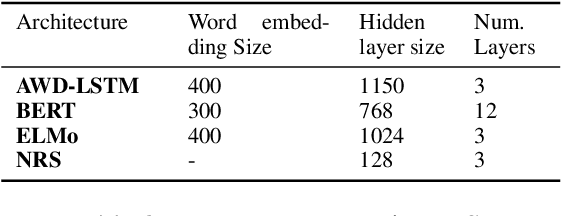
Dialogue engines that incorporate different types of agents to converse with humans are popular. However, conversations are dynamic in the sense that a selected response will change the conversation on-the-fly, influencing the subsequent utterances in the conversation, which makes the response selection a challenging problem. We model the problem of selecting the best response from a set of responses generated by a heterogeneous set of dialogue agents by taking into account the conversational history, and propose a \emph{Neural Response Selection} method. The proposed method is trained to predict a coherent set of responses within a single conversation, considering its own predictions via a curriculum training mechanism. Our experimental results show that the proposed method can accurately select the most appropriate responses, thereby significantly improving the user experience in dialogue systems.