 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Meta Word Embeddings by Unsupervised Weighted Concatenation of Source Embeddings
Apr 26, 2022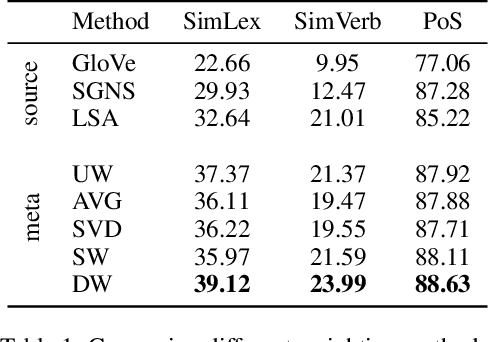
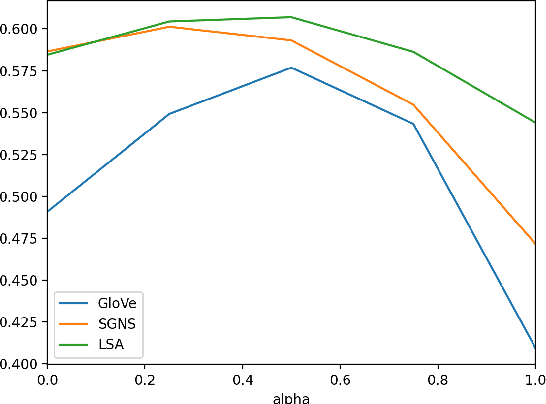
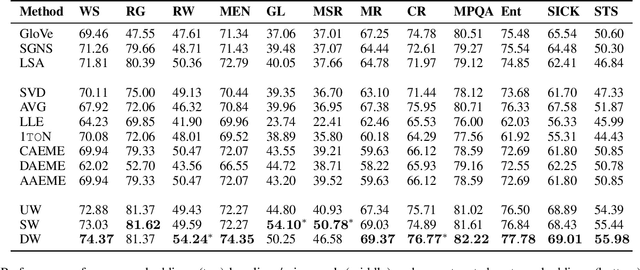
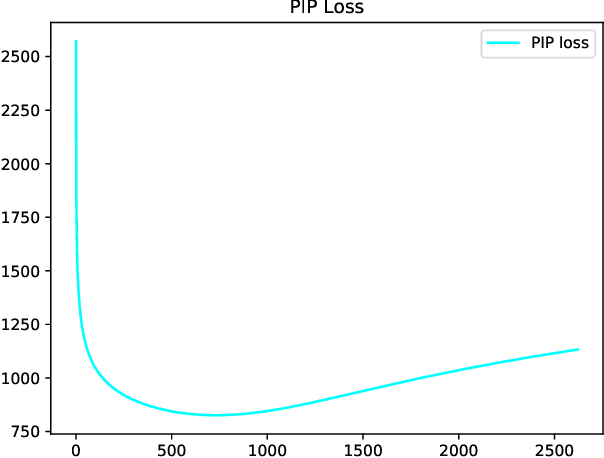
Given multiple source word embeddings learnt using diverse algorithms and lexical resources, meta word embedding learning methods attempt to learn more accurate and wide-coverage word embeddings. Prior work on meta-embedding has repeatedly discovered that simple vector concatenation of the source embeddings to be a competitive baseline. However, it remains unclear as to why and when simple vector concatenation can produce accurate meta-embeddings. We show that weighted concatenation can be seen as a spectrum matching operation between each source embedding and the meta-embedding, minimising the pairwise inner-product loss. Following this theoretical analysis, we propose two \emph{unsupervised} methods to learn the optimal concatenation weights for creating meta-embeddings from a given set of source embeddings. Experimental results on multiple benchmark datasets show that the proposed weighted concatenated meta-embedding methods outperform previously proposed meta-embedding learning methods.
A Survey on Word Meta-Embedding Learning
Apr 25, 2022Meta-embedding (ME) learning is an emerging approach that attempts to learn more accurate word embeddings given existing (source) word embeddings as the sole input. Due to their ability to incorporate semantics from multiple source embeddings in a compact manner with superior performance, ME learning has gained popularity among practitioners in NLP. To the best of our knowledge, there exist no prior systematic survey on ME learning and this paper attempts to fill this need. We classify ME learning methods according to multiple factors such as whether they (a) operate on static or contextualised embeddings, (b) trained in an unsupervised manner or (c) fine-tuned for a particular task/domain. Moreover, we discuss the limitations of existing ME learning methods and highlight potential future research directions.
* Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI-2022)
Unsupervised Attention-based Sentence-Level Meta-Embeddings from Contextualised Language Models
Apr 16, 2022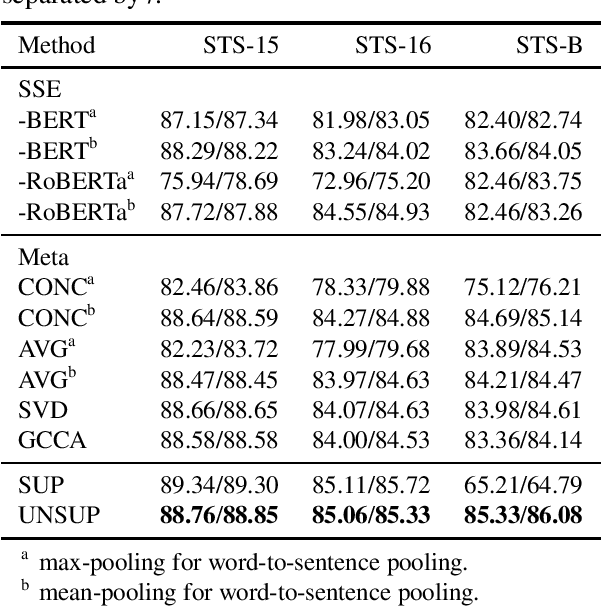
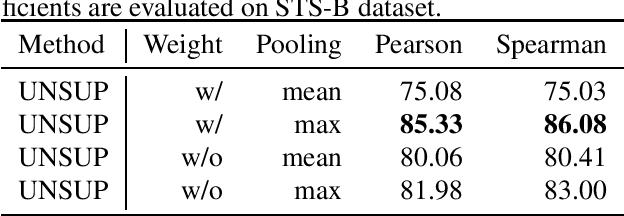
A variety of contextualised language models have been proposed in the NLP community, which are trained on diverse corpora to produce numerous Neural Language Models (NLMs). However, different NLMs have reported different levels of performances in downstream NLP applications when used as text representations. We propose a sentence-level meta-embedding learning method that takes independently trained contextualised word embedding models and learns a sentence embedding that preserves the complementary strengths of the input source NLMs. Our proposed method is unsupervised and is not tied to a particular downstream task, which makes the learnt meta-embeddings in principle applicable to different tasks that require sentence representations. Specifically, we first project the token-level embeddings obtained by the individual NLMs and learn attention weights that indicate the contributions of source embeddings towards their token-level meta-embeddings. Next, we apply mean and max pooling to produce sentence-level meta-embeddings from token-level meta-embeddings. Experimental results on semantic textual similarity benchmarks show that our proposed unsupervised sentence-level meta-embedding method outperforms previously proposed sentence-level meta-embedding methods as well as a supervised baseline.
Sense Embeddings are also Biased--Evaluating Social Biases in Static and Contextualised Sense Embeddings
Mar 16, 2022
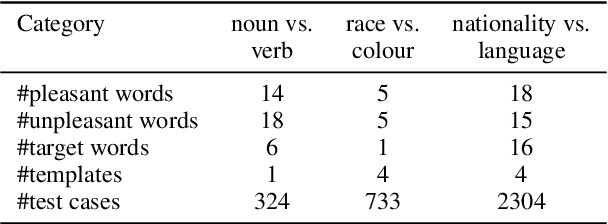

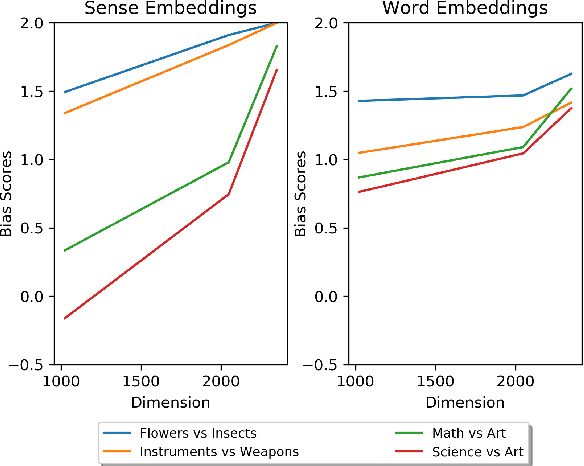
Sense embedding learning methods learn different embeddings for the different senses of an ambiguous word. One sense of an ambiguous word might be socially biased while its other senses remain unbiased. In comparison to the numerous prior work evaluating the social biases in pretrained word embeddings, the biases in sense embeddings have been relatively understudied. We create a benchmark dataset for evaluating the social biases in sense embeddings and propose novel sense-specific bias evaluation measures. We conduct an extensive evaluation of multiple static and contextualised sense embeddings for various types of social biases using the proposed measures. Our experimental results show that even in cases where no biases are found at word-level, there still exist worrying levels of social biases at sense-level, which are often ignored by the word-level bias evaluation measures.
Assessment of contextualised representations in detecting outcome phrases in clinical trials
Mar 13, 2022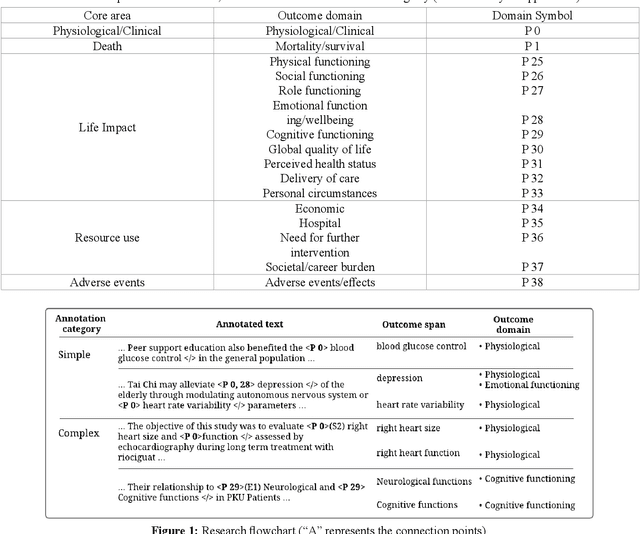

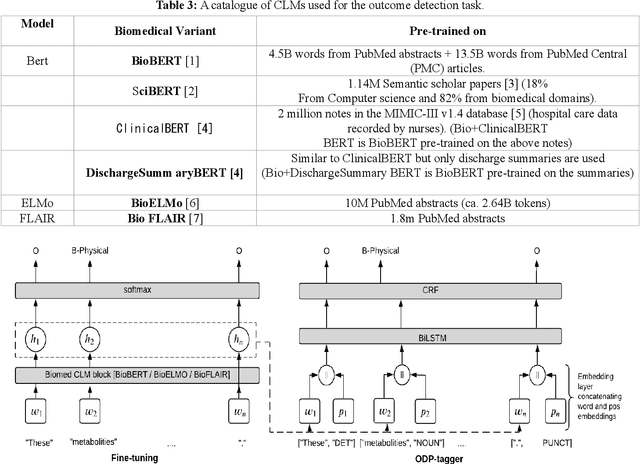
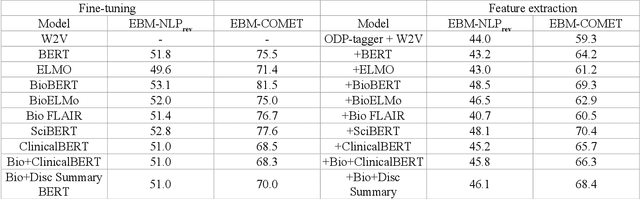
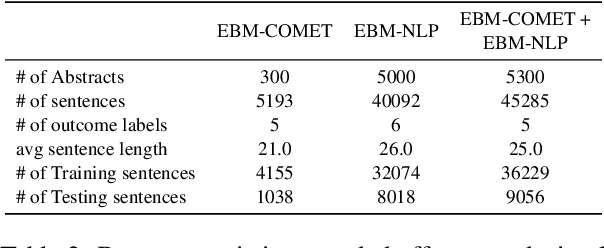
Automating the recognition of outcomes reported in clinical trials using machine learning has a huge potential of speeding up access to evidence necessary in healthcare decision-making. Prior research has however acknowledged inadequate training corpora as a challenge for the Outcome detection (OD) task. Additionally, several contextualized representations like BERT and ELMO have achieved unparalleled success in detecting various diseases, genes, proteins, and chemicals, however, the same cannot be emphatically stated for outcomes, because these models have been relatively under-tested and studied for the OD task. We introduce "EBM-COMET", a dataset in which 300 PubMed abstracts are expertly annotated for clinical outcomes. Unlike prior related datasets that use arbitrary outcome classifications, we use labels from a taxonomy recently published to standardize outcome classifications. To extract outcomes, we fine-tune a variety of pre-trained contextualized representations, additionally, we use frozen contextualized and context-independent representations in our custom neural model augmented with clinically informed Part-Of-Speech embeddings and a cost-sensitive loss function. We adopt strict evaluation for the trained models by rewarding them for correctly identifying full outcome phrases rather than words within the entities i.e. given an outcome "systolic blood pressure", the models are rewarded a classification score only when they predict all 3 words in sequence, otherwise, they are not rewarded. We observe our best model (BioBERT) achieve 81.5\% F1, 81.3\% sensitivity and 98.0\% specificity. We reach a consensus on which contextualized representations are best suited for detecting outcomes from clinical-trial abstracts. Furthermore, our best model outperforms scores published on the original EBM-NLP dataset leader-board scores.
Learning Sense-Specific Static Embeddings using Contextualised Word Embeddings as a Proxy
Oct 06, 2021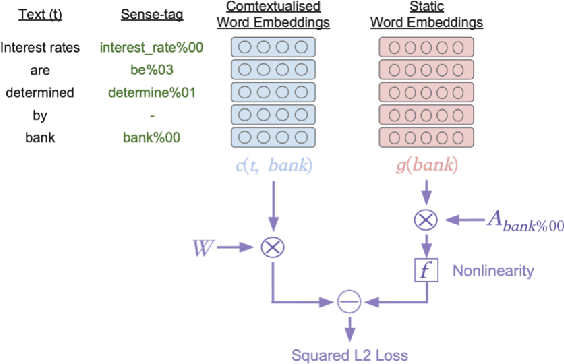
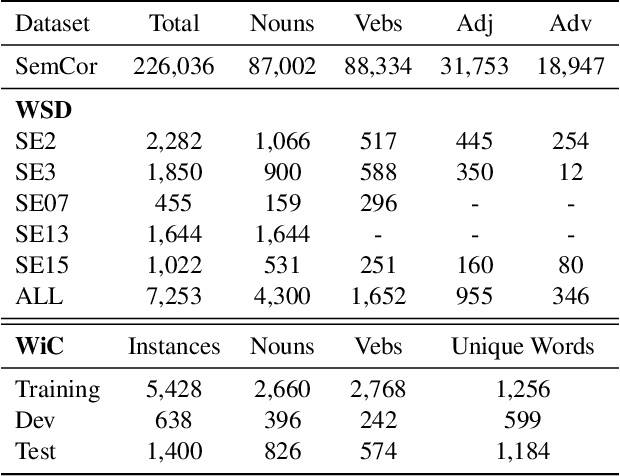
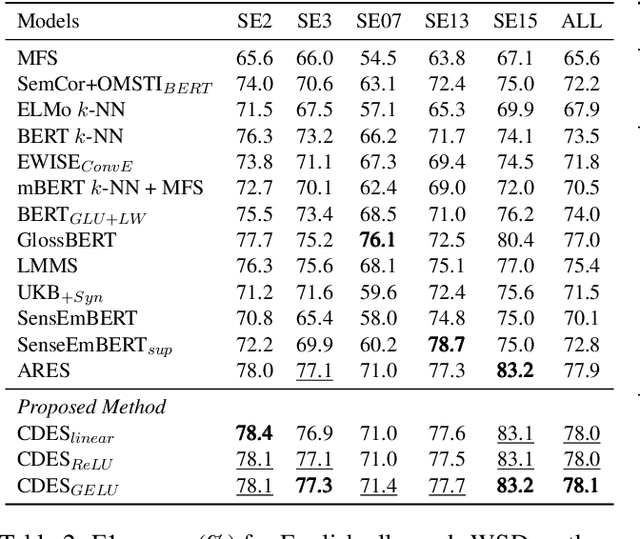
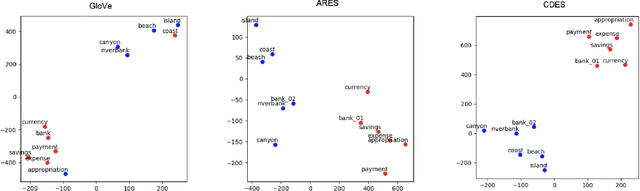
Contextualised word embeddings generated from Neural Language Models (NLMs), such as BERT, represent a word with a vector that considers the semantics of the target word as well its context. On the other hand, static word embeddings such as GloVe represent words by relatively low-dimensional, memory- and compute-efficient vectors but are not sensitive to the different senses of the word. We propose Context Derived Embeddings of Senses (CDES), a method that extracts sense related information from contextualised embeddings and injects it into static embeddings to create sense-specific static embeddings. Experimental results on multiple benchmarks for word sense disambiguation and sense discrimination tasks show that CDES can accurately learn sense-specific static embeddings reporting comparable performance to the current state-of-the-art sense embeddings.
Unsupervised Abstractive Opinion Summarization by Generating Sentences with Tree-Structured Topic Guidance
Jun 15, 2021

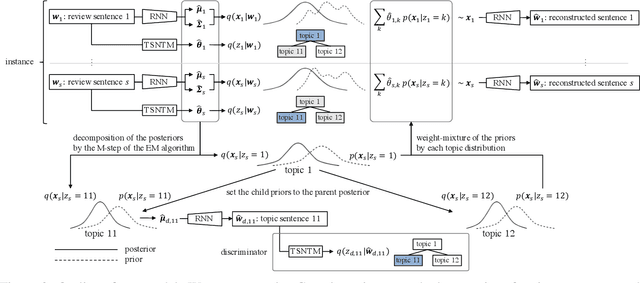
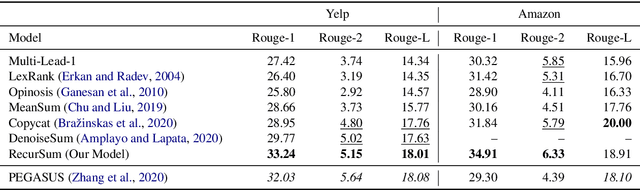
This paper presents a novel unsupervised abstractive summarization method for opinionated texts. While the basic variational autoencoder-based models assume a unimodal Gaussian prior for the latent code of sentences, we alternate it with a recursive Gaussian mixture, where each mixture component corresponds to the latent code of a topic sentence and is mixed by a tree-structured topic distribution. By decoding each Gaussian component, we generate sentences with tree-structured topic guidance, where the root sentence conveys generic content, and the leaf sentences describe specific topics. Experimental results demonstrate that the generated topic sentences are appropriate as a summary of opinionated texts, which are more informative and cover more input contents than those generated by the recent unsupervised summarization model (Bra\v{z}inskas et al., 2020). Furthermore, we demonstrate that the variance of latent Gaussians represents the granularity of sentences, analogous to Gaussian word embedding (Vilnis and McCallum, 2015).
Backretrieval: An Image-Pivoted Evaluation Metric for Cross-Lingual Text Representations Without Parallel Corpora
May 11, 2021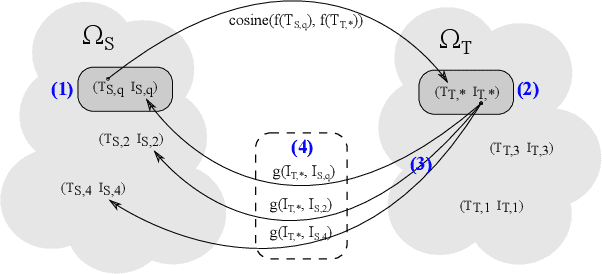
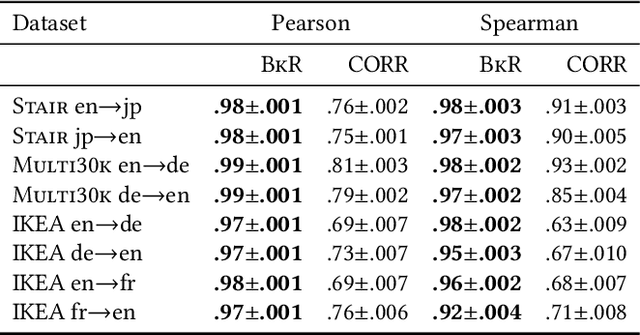
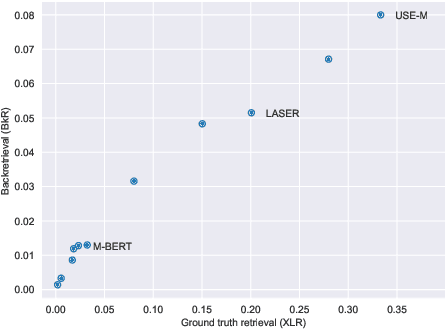
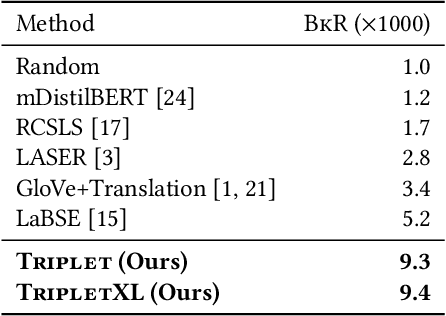
Cross-lingual text representations have gained popularity lately and act as the backbone of many tasks such as unsupervised machine translation and cross-lingual information retrieval, to name a few. However, evaluation of such representations is difficult in the domains beyond standard benchmarks due to the necessity of obtaining domain-specific parallel language data across different pairs of languages. In this paper, we propose an automatic metric for evaluating the quality of cross-lingual textual representations using images as a proxy in a paired image-text evaluation dataset. Experimentally, Backretrieval is shown to highly correlate with ground truth metrics on annotated datasets, and our analysis shows statistically significant improvements over baselines. Our experiments conclude with a case study on a recipe dataset without parallel cross-lingual data. We illustrate how to judge cross-lingual embedding quality with Backretrieval, and validate the outcome with a small human study.
Detect and Classify -- Joint Span Detection and Classification for Health Outcomes
Apr 15, 2021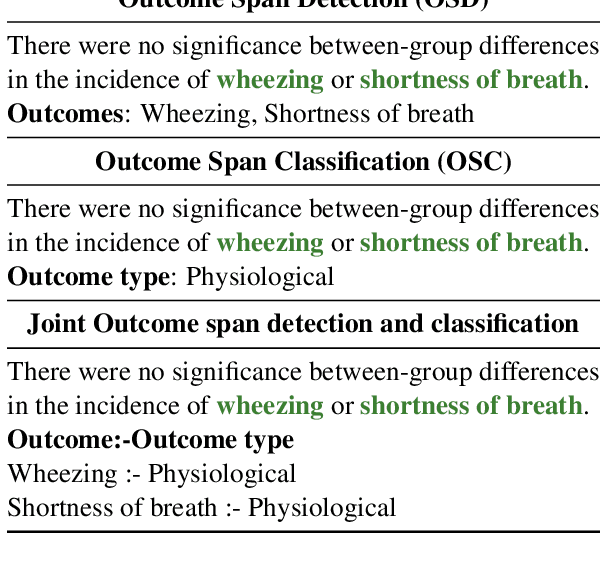
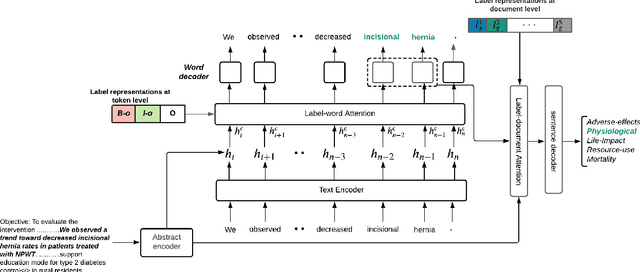
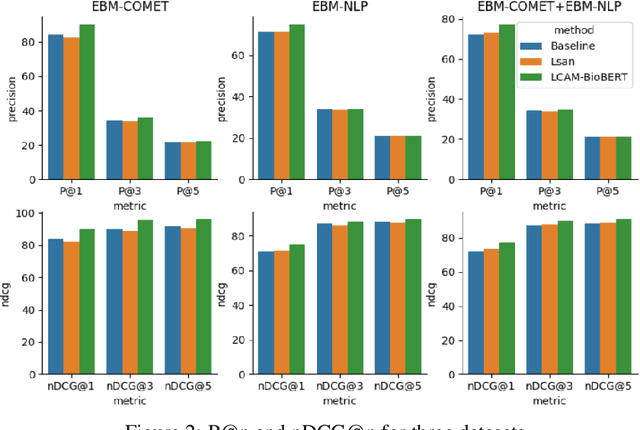
A health outcome is a measurement or an observation used to capture and assess the effect of a treatment. Automatic detection of health outcomes from text would undoubtedly speed up access to evidence necessary in healthcare decision making. Prior work on outcome detection has modelled this task as either (a) a sequence labelling task, where the goal is to detect which text spans describe health outcomes or (b) a classification task, where the goal is to classify a text into a pre-defined set of categories depending on an outcome that is mentioned somewhere in that text. However, this decoupling of span detection and classification is problematic from a modelling perspective and ignores global structural correspondences between sentence-level and word-level information present in a given text. We propose a method that uses both word-level and sentence-level information to simultaneously perform outcome span detection and outcome type classification. In addition to injecting contextual information to hidden vectors, we use label attention to appropriately weight both word-level and sentence-level information. Experimental results on several benchmark datasets for health outcome detection show that our model consistently outperforms decoupled methods, reporting competitive results.
Unmasking the Mask -- Evaluating Social Biases in Masked Language Models
Apr 15, 2021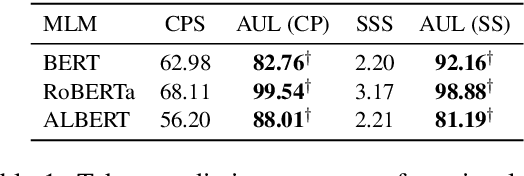
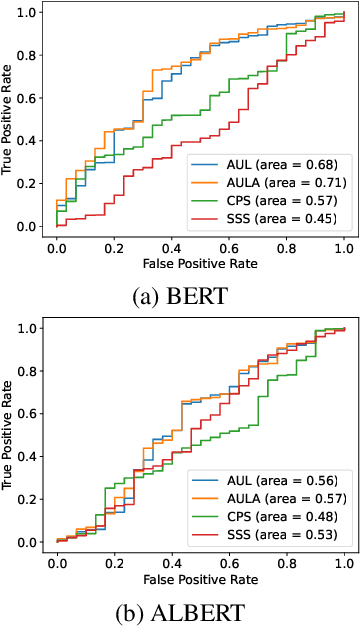

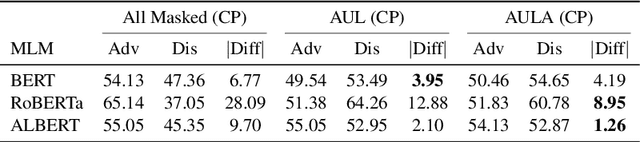
Masked Language Models (MLMs) have shown superior performances in numerous downstream NLP tasks when used as text encoders. Unfortunately, MLMs also demonstrate significantly worrying levels of social biases. We show that the previously proposed evaluation metrics for quantifying the social biases in MLMs are problematic due to following reasons: (1) prediction accuracy of the masked tokens itself tend to be low in some MLMs, which raises questions regarding the reliability of the evaluation metrics that use the (pseudo) likelihood of the predicted tokens, and (2) the correlation between the prediction accuracy of the mask and the performance in downstream NLP tasks is not taken into consideration, and (3) high frequency words in the training data are masked more often, introducing noise due to this selection bias in the test cases. To overcome the above-mentioned disfluencies, we propose All Unmasked Likelihood (AUL), a bias evaluation measure that predicts all tokens in a test case given the MLM embedding of the unmasked input. We find that AUL accurately detects different types of biases in MLMs. We also propose AUL with attention weights (AULA) to evaluate tokens based on their importance in a sentence. However, unlike AUL and AULA, previously proposed bias evaluation measures for MLMs systematically overestimate the measured biases, and are heavily influenced by the unmasked tokens in the context.