 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Stylization for Robust Features
Aug 16, 2020



Local features that are robust to both viewpoint and appearance changes are crucial for many computer vision tasks. In this work we investigate if photorealistic image stylization improves robustness of local features to not only day-night, but also weather and season variations. We show that image stylization in addition to color augmentation is a powerful method of learning robust features. We evaluate learned features on visual localization benchmarks, outperforming state of the art baseline models despite training without ground-truth 3D correspondences using synthetic homographies only. We use trained feature networks to compete in Long-Term Visual Localization and Map-based Localization for Autonomous Driving challenges achieving competitive scores.
Predicting Visual Overlap of Images Through Interpretable Non-Metric Box Embeddings
Aug 13, 2020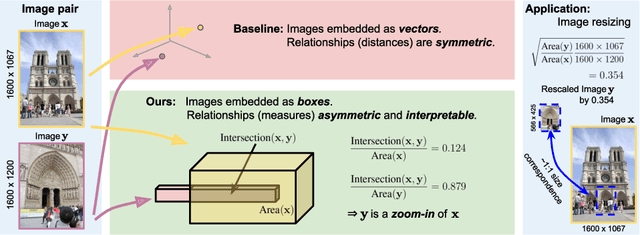
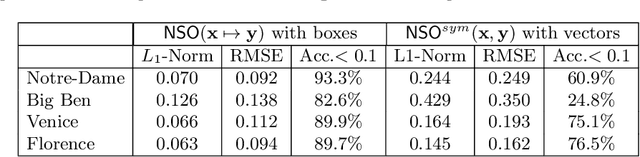

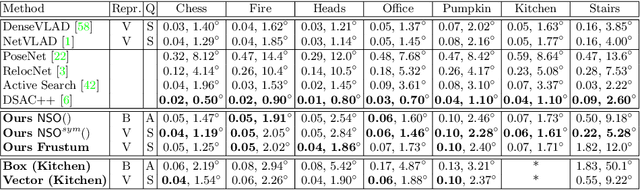
To what extent are two images picturing the same 3D surfaces? Even when this is a known scene, the answer typically requires an expensive search across scale space, with matching and geometric verification of large sets of local features. This expense is further multiplied when a query image is evaluated against a gallery, e.g. in visual relocalization. While we don't obviate the need for geometric verification, we propose an interpretable image-embedding that cuts the search in scale space to essentially a lookup. Our approach measures the asymmetric relation between two images. The model then learns a scene-specific measure of similarity, from training examples with known 3D visible-surface overlaps. The result is that we can quickly identify, for example, which test image is a close-up version of another, and by what scale factor. Subsequently, local features need only be detected at that scale. We validate our scene-specific model by showing how this embedding yields competitive image-matching results, while being simpler, faster, and also interpretable by humans.
Self-Supervised Monocular Depth Hints
Sep 19, 2019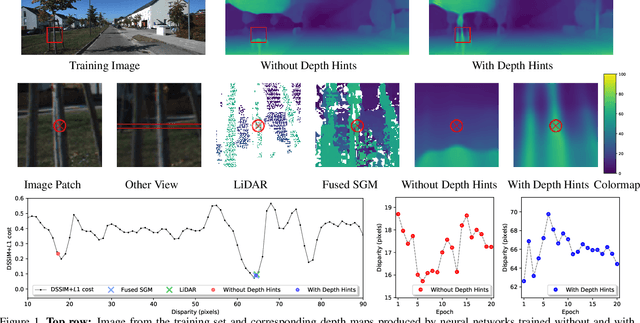
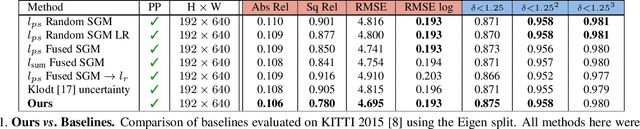
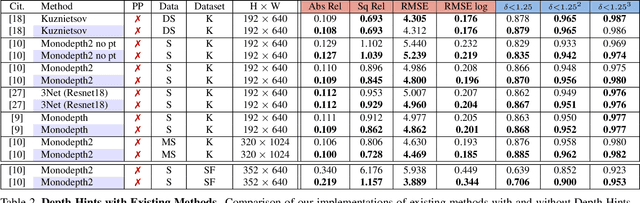
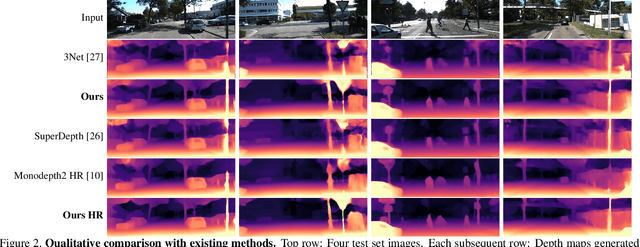
Monocular depth estimators can be trained with various forms of self-supervision from binocular-stereo data to circumvent the need for high-quality laser scans or other ground-truth data. The disadvantage, however, is that the photometric reprojection losses used with self-supervised learning typically have multiple local minima. These plausible-looking alternatives to ground truth can restrict what a regression network learns, causing it to predict depth maps of limited quality. As one prominent example, depth discontinuities around thin structures are often incorrectly estimated by current state-of-the-art methods. Here, we study the problem of ambiguous reprojections in depth prediction from stereo-based self-supervision, and introduce Depth Hints to alleviate their effects. Depth Hints are complementary depth suggestions obtained from simple off-the-shelf stereo algorithms. These hints enhance an existing photometric loss function, and are used to guide a network to learn better weights. They require no additional data, and are assumed to be right only sometimes. We show that using our Depth Hints gives a substantial boost when training several leading self-supervised-from-stereo models, not just our own. Further, combined with other good practices, we produce state-of-the-art depth predictions on the KITTI benchmark.
Interpretable Transformations with Encoder-Decoder Networks
Oct 19, 2017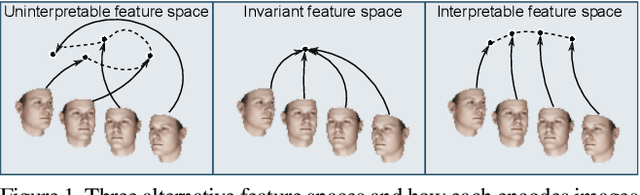
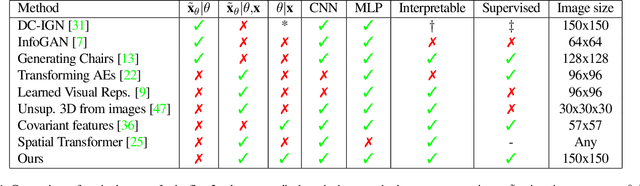
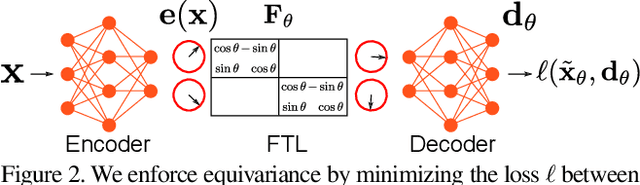
Deep feature spaces have the capacity to encode complex transformations of their input data. However, understanding the relative feature-space relationship between two transformed encoded images is difficult. For instance, what is the relative feature space relationship between two rotated images? What is decoded when we interpolate in feature space? Ideally, we want to disentangle confounding factors, such as pose, appearance, and illumination, from object identity. Disentangling these is difficult because they interact in very nonlinear ways. We propose a simple method to construct a deep feature space, with explicitly disentangled representations of several known transformations. A person or algorithm can then manipulate the disentangled representation, for example, to re-render an image with explicit control over parameterized degrees of freedom. The feature space is constructed using a transforming encoder-decoder network with a custom feature transform layer, acting on the hidden representations. We demonstrate the advantages of explicit disentangling on a variety of datasets and transformations, and as an aid for traditional tasks, such as classification.
Harmonic Networks: Deep Translation and Rotation Equivariance
Apr 11, 2017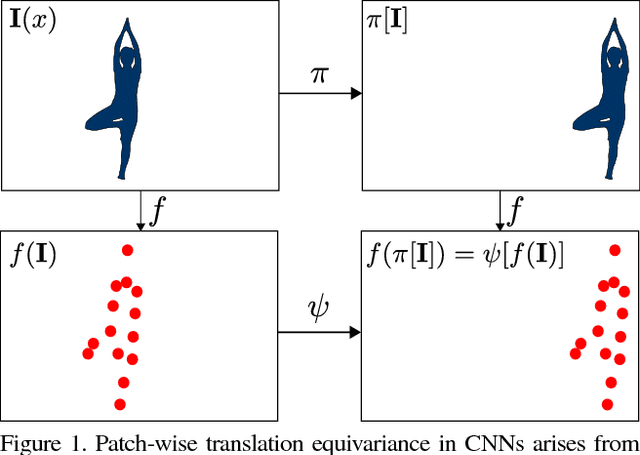
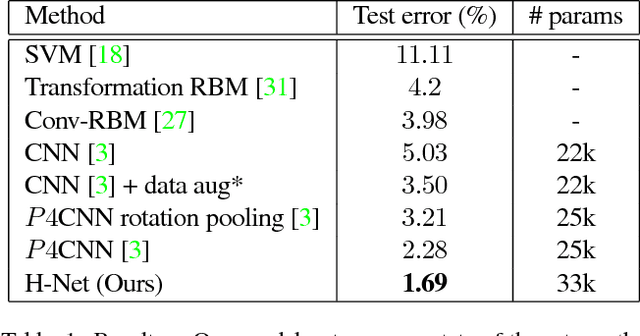
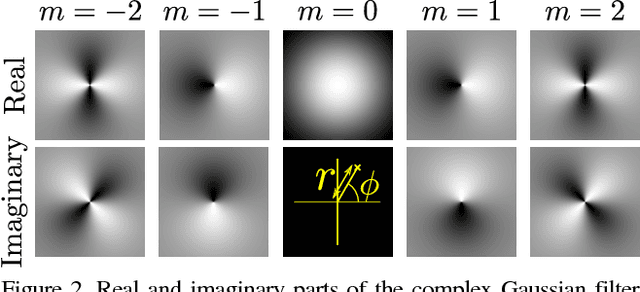
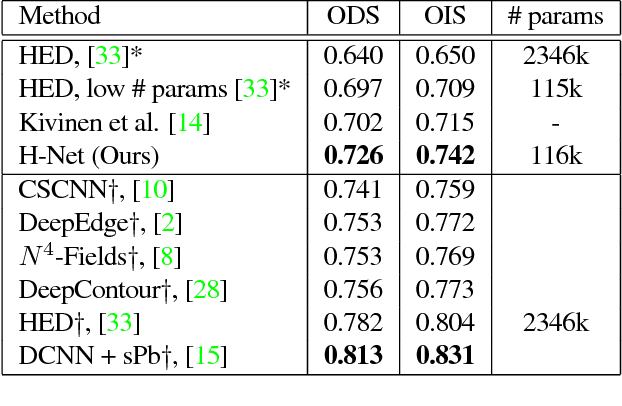
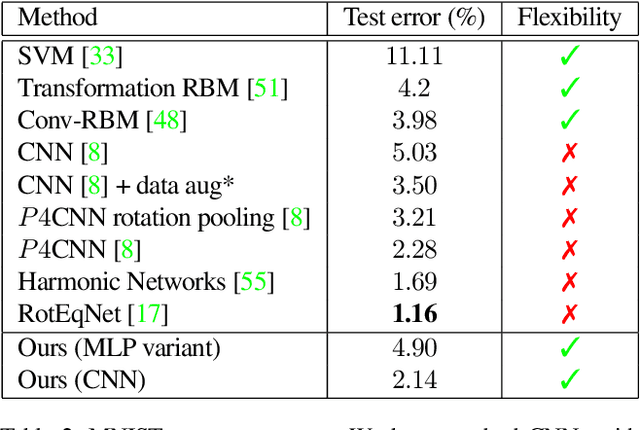
Translating or rotating an input image should not affect the results of many computer vision tasks. Convolutional neural networks (CNNs) are already translation equivariant: input image translations produce proportionate feature map translations. This is not the case for rotations. Global rotation equivariance is typically sought through data augmentation, but patch-wise equivariance is more difficult. We present Harmonic Networks or H-Nets, a CNN exhibiting equivariance to patch-wise translation and 360-rotation. We achieve this by replacing regular CNN filters with circular harmonics, returning a maximal response and orientation for every receptive field patch. H-Nets use a rich, parameter-efficient and low computational complexity representation, and we show that deep feature maps within the network encode complicated rotational invariants. We demonstrate that our layers are general enough to be used in conjunction with the latest architectures and techniques, such as deep supervision and batch normalization. We also achieve state-of-the-art classification on rotated-MNIST, and competitive results on other benchmark challenges.