 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeRo-Q: A General Framework for Stable Low Bit Quantization via Hessian Conditioning
Jan 29, 2026Post Training Quantization (PTQ), a mainstream model compression technique, often leads to the paradoxical 'low error, high loss' phenomenon because it focuses solely on minimizing quantization error. The root cause lies in the Hessian matrix of the LLM loss landscape: a few high curvature directions are extremely sensitive to perturbations. To address this, we propose the Hessian Robust Quantization (HeRo Q) algorithm, which applies a lightweight, learnable rotation-compression matrix to the weight space prior to quantization. This joint framework reshapes the loss landscape by reducing the largest Hessian eigenvalue and reducing its max eigenvalue, thereby significantly enhancing robustness to quantization noise. HeRo-Q requires no architectural modifications, incurs negligible computational overhead, and integrates seamlessly into existing PTQ pipelines. Experiments on Llama and Qwen models show that HeRo Q consistently outperforms state of the art methods including GPTQ, AWQ, and SpinQuant not only achieving superior performance under standard W4A8 settings, but also excelling in the highly challenging W3A16 ultra low bit regime, where it boosts GSM8K accuracy on Llama3 8B to 70.15\% and effectively avoids the logical collapse commonly seen in aggressive quantization.
MoE-DisCo:Low Economy Cost Training Mixture-of-Experts Models
Jan 11, 2026Training large-scale Mixture-of-Experts (MoE) models typically requires high-memory, high-bandwidth GPUs (e.g., A100), and their high cost has become a major barrier to large-model training. In contrast, affordable hardware is low-cost but constrained by memory capacity and bandwidth, making it unsuitable for direct LLM training. To address this, we propose MoE-DisCo (Mixture-of-Experts with Disentangled Clustering and Coordination), a staged training framework. MoE-DisCo decomposes the MoE model into multiple dense submodels, each consisting of a shared backbone and a single expert, and partitions the training data into subsets using unsupervised clustering. Each submodel is trained independently and in parallel on its assigned data subset using low-cost devices, without any inter-device communication. Subsequently, all experts are integrated into a complete MoE model and fine-tuned globally for a short period on high-memory, high-bandwidth GPUs. Experiments show that our method matches or even surpasses full-parameter training in performance across multiple downstream tasks, loss function, and perplexity (PPL), while reducing training cost by 47.6 percent to 69.5 percent on Qwen1.5-MoE-2.7B and Llama-MoE-3.5B across different datasets.
Rethinking Parameter Sharing as Graph Coloring for Structured Compression
Nov 10, 2025Modern deep models have massive parameter sizes, leading to high inference-time memory usage that limits practical deployment. Parameter sharing, a form of structured compression, effectively reduces redundancy, but existing approaches remain heuristic-restricted to adjacent layers and lacking a systematic analysis for cross-layer sharing. However, extending sharing across multiple layers leads to an exponentially expanding configuration space, making exhaustive search computationally infeasible and forming a critical bottleneck for parameter sharing. We recast parameter sharing from a group-theoretic perspective as introducing structural symmetries in the model's parameter space. A sharing configuration can be described by a coloring function $α:L\rightarrow C$ (L: layer indices and C: sharing classes), which determines inter-layer sharing groups while preserving structural symmetry. To determine the coloring function, we propose a second-order geometric criterion based on Taylor expansion and the Hessian spectrum. By projecting perturbations onto the Hessian's low-curvature eigensubspace, the criterion provides an analytic rule for selecting sharing groups that minimize performance impact, yielding a principled and scalable configuration procedure. Across diverse architectures and tasks, Geo-Sharing consistently outperforms state-of-the-art heuristic sharing strategies, achieving higher compression ratios with smaller accuracy degradation.
Can the capability of Large Language Models be described by human ability? A Meta Study
Apr 13, 2025



Users of Large Language Models (LLMs) often perceive these models as intelligent entities with human-like capabilities. However, the extent to which LLMs' capabilities truly approximate human abilities remains a topic of debate. In this paper, to characterize the capabilities of LLMs in relation to human capabilities, we collected performance data from over 80 models across 37 evaluation benchmarks. The evaluation benchmarks are categorized into 6 primary abilities and 11 sub-abilities in human aspect. Then, we then clustered the performance rankings into several categories and compared these clustering results with classifications based on human ability aspects. Our findings lead to the following conclusions: 1. We have confirmed that certain capabilities of LLMs with fewer than 10 billion parameters can indeed be described using human ability metrics; 2. While some abilities are considered interrelated in humans, they appear nearly uncorrelated in LLMs; 3. The capabilities possessed by LLMs vary significantly with the parameter scale of the model.
A General Error-Theoretical Analysis Framework for Constructing Compression Strategies
Feb 19, 2025The exponential growth in parameter size and computational complexity of deep models poses significant challenges for efficient deployment. The core problem of existing compression methods is that different layers of the model have significant differences in their tolerance to compression levels. For instance, the first layer of a model can typically sustain a higher compression level compared to the last layer without compromising performance. Thus, the key challenge lies in how to allocate compression levels across layers in a way that minimizes performance loss while maximizing parameter reduction. To address this challenge, we propose a Compression Error Theory (CET) framework, designed to determine the optimal compression level for each layer. Taking quantization as an example, CET leverages differential expansion and algebraic geometry to reconstruct the quadratic form of quantization error as ellipsoids and hyperbolic paraboloids, and utilizes their geometric structures to define an error subspace. To identify the error subspace with minimal performance loss, by performing orthogonal decomposition of the geometric space, CET transforms the optimization process of the error subspace into a complementary problem. The final theoretical analysis shows that constructing the quantization subspace along the major axis results in minimal performance degradation. Through experimental verification of the theory, CET can greatly retain performance while compressing. Specifically, on the ResNet-34 model, CET achieves nearly 11$\times$ parameter compression while even surpassing performance comparable to the original model.
FP=xINT:A Low-Bit Series Expansion Algorithm for Post-Training Quantization
Dec 09, 2024



Post-Training Quantization (PTQ) converts pre-trained Full-Precision (FP) models into quantized versions without training. While existing methods reduce size and computational costs, they also significantly degrade performance and quantization efficiency at extremely low settings due to quantization noise. We introduce a deep model series expansion framework to address this issue, enabling rapid and accurate approximation of unquantized models without calibration sets or fine-tuning. This is the first use of series expansion for neural network quantization. Specifically, our method expands the FP model into multiple low-bit basis models. To ensure accurate quantization, we develop low-bit basis model expansions at different granularities (tensor, layer, model), and theoretically confirm their convergence to the dense model, thus restoring FP model accuracy. Additionally, we design AbelianAdd/Mul operations between isomorphic models in the low-bit expansion, forming an Abelian group to ensure operation parallelism and commutativity. The experiments show that our algorithm achieves state-of-the-art performance in low-bit settings; for example, 4-bit quantization of ResNet-50 surpasses the original accuracy, reaching 77.03%. The code will be made public.
Lossless Model Compression via Joint Low-Rank Factorization Optimization
Dec 09, 2024Low-rank factorization is a popular model compression technique that minimizes the error $\delta$ between approximated and original weight matrices. Despite achieving performances close to the original models when $\delta$ is optimized, a performance discrepancy remains due to the separate optimization processes for low-rank factorization and model performance, resulting in unavoidable losses. We address this issue by introducing a novel joint optimization strategy for lossless low-rank weight factorization, which, for the first time, enhances the model's performance beyond the original. Our approach begins with a theoretical analysis of the relationship between low-rank factorization and model optimization objectives, establishing a precise perturbation range for matrix factorization errors on model performance. This challenge is then reformulated as a numerical rank deficiency problem with inequality constraints and develop a joint objective that simultaneously addresses factorization error and model performance. Based on the above analysis, we propose two optimization algorithms: \textbf{a lossless optimization algorithm} that maximizes model accuracy while ensuring compression, and \textbf{a compact optimization algorithm} that minimizes model size while preserving performance. These algorithms do not require fine-tuning and can directly compress numerous deep models to achieve lossless results. Our methods demonstrate robust efficacy across various vision and language tasks. For example, the compressed model reduced by 70\% on ResNext50 outperforms the original. Our code will be made public.
Compression for Better: A General and Stable Lossless Compression Framework
Dec 09, 2024This work focus on how to stabilize and lossless model compression, aiming to reduce model complexity and enhance efficiency without sacrificing performance due to compression errors. A key challenge is effectively leveraging compression errors and defining the boundaries for lossless compression to minimize model loss. i.e., compression for better. Currently, there is no systematic approach to determining this error boundary or understanding its specific impact on model performance. We propose a general \textbf{L}oss\textbf{L}ess \textbf{C}ompression theoretical framework (\textbf{LLC}), which further delineates the compression neighborhood and higher-order analysis boundaries through the total differential, thereby specifying the error range within which a model can be compressed without loss. To verify the effectiveness of LLC, we apply various compression techniques, including quantization and decomposition. Specifically, for quantization, we reformulate the classic quantization search problem as a grouped knapsack problem within the lossless neighborhood, achieving lossless quantization while improving computational efficiency. For decomposition, LLC addresses the approximation problem under low-rank constraints, automatically determining the rank for each layer and producing lossless low-rank models. We conduct extensive experiments on multiple neural network architectures on different datasets. The results show that without fancy tricks, LLC can effectively achieve lossless model compression. Our code will be made publicly.
Mixed-Precision Inference Quantization: Radically Towards Faster inference speed, Lower Storage requirement, and Lower Loss
Jul 20, 2022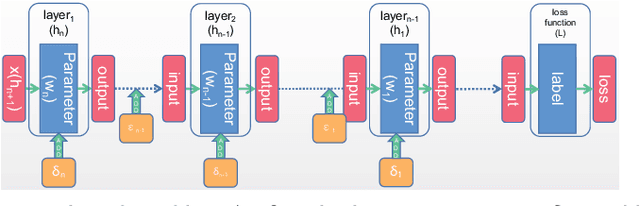
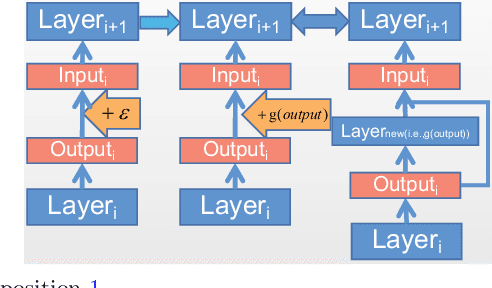
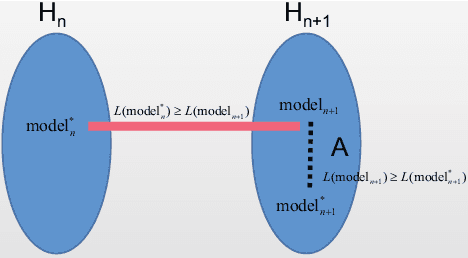
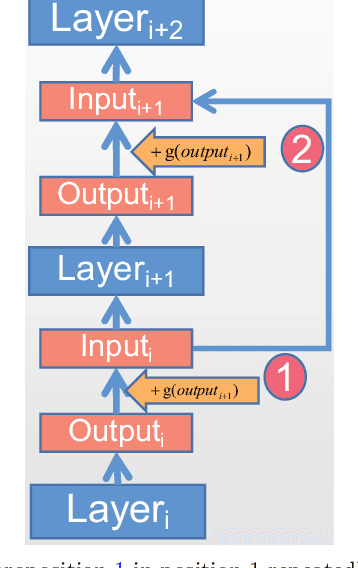
Based on the model's resilience to computational noise, model quantization is important for compressing models and improving computing speed. Existing quantization techniques rely heavily on experience and "fine-tuning" skills. In the majority of instances, the quantization model has a larger loss than a full precision model. This study provides a methodology for acquiring a mixed-precise quantization model with a lower loss than the full precision model. In addition, the analysis demonstrates that, throughout the inference process, the loss function is mostly affected by the noise of the layer inputs. In particular, we will demonstrate that neural networks with massive identity mappings are resistant to the quantization method. It is also difficult to improve the performance of these networks using quantization.
Quantization in Layer's Input is Matter
Feb 10, 2022In this paper, we will show that the quantization in layer's input is more important than parameters' quantization for loss function. And the algorithm which is based on the layer's input quantization error is better than hessian-based mixed precision layout algorithm.