 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Accelerating Benders Decomposition via Reinforcement Learning Surrogate Models
Jul 17, 2023



Stochastic optimization (SO) attempts to offer optimal decisions in the presence of uncertainty. Often, the classical formulation of these problems becomes intractable due to (a) the number of scenarios required to capture the uncertainty and (b) the discrete nature of real-world planning problems. To overcome these tractability issues, practitioners turn to decomposition methods that divide the problem into smaller, more tractable sub-problems. The focal decomposition method of this paper is Benders decomposition (BD), which decomposes stochastic optimization problems on the basis of scenario independence. In this paper we propose a method of accelerating BD with the aid of a surrogate model in place of an NP-hard integer master problem. Through the acceleration method we observe 30% faster average convergence when compared to other accelerated BD implementations. We introduce a reinforcement learning agent as a surrogate and demonstrate how it can be used to solve a stochastic inventory management problem.
On the Connection between Game-Theoretic Feature Attributions and Counterfactual Explanations
Jul 13, 2023



Explainable Artificial Intelligence (XAI) has received widespread interest in recent years, and two of the most popular types of explanations are feature attributions, and counterfactual explanations. These classes of approaches have been largely studied independently and the few attempts at reconciling them have been primarily empirical. This work establishes a clear theoretical connection between game-theoretic feature attributions, focusing on but not limited to SHAP, and counterfactuals explanations. After motivating operative changes to Shapley values based feature attributions and counterfactual explanations, we prove that, under conditions, they are in fact equivalent. We then extend the equivalency result to game-theoretic solution concepts beyond Shapley values. Moreover, through the analysis of the conditions of such equivalence, we shed light on the limitations of naively using counterfactual explanations to provide feature importances. Experiments on three datasets quantitatively show the difference in explanations at every stage of the connection between the two approaches and corroborate the theoretical findings.
* Accepted at AIES 2023
SHAP@k:Efficient and Probably Approximately Correct (PAC) Identification of Top-k Features
Jul 10, 2023



The SHAP framework provides a principled method to explain the predictions of a model by computing feature importance. Motivated by applications in finance, we introduce the Top-k Identification Problem (TkIP), where the objective is to identify the k features with the highest SHAP values. While any method to compute SHAP values with uncertainty estimates (such as KernelSHAP and SamplingSHAP) can be trivially adapted to solve TkIP, doing so is highly sample inefficient. The goal of our work is to improve the sample efficiency of existing methods in the context of solving TkIP. Our key insight is that TkIP can be framed as an Explore-m problem--a well-studied problem related to multi-armed bandits (MAB). This connection enables us to improve sample efficiency by leveraging two techniques from the MAB literature: (1) a better stopping-condition (to stop sampling) that identifies when PAC (Probably Approximately Correct) guarantees have been met and (2) a greedy sampling scheme that judiciously allocates samples between different features. By adopting these methods we develop KernelSHAP@k and SamplingSHAP@k to efficiently solve TkIP, offering an average improvement of $5\times$ in sample-efficiency and runtime across most common credit related datasets.
GLOBE-CE: A Translation-Based Approach for Global Counterfactual Explanations
May 26, 2023



Counterfactual explanations have been widely studied in explainability, with a range of application dependent methods prominent in fairness, recourse and model understanding. The major shortcoming associated with these methods, however, is their inability to provide explanations beyond the local or instance-level. While many works touch upon the notion of a global explanation, typically suggesting to aggregate masses of local explanations in the hope of ascertaining global properties, few provide frameworks that are both reliable and computationally tractable. Meanwhile, practitioners are requesting more efficient and interactive explainability tools. We take this opportunity to propose Global & Efficient Counterfactual Explanations (GLOBE-CE), a flexible framework that tackles the reliability and scalability issues associated with current state-of-the-art, particularly on higher dimensional datasets and in the presence of continuous features. Furthermore, we provide a unique mathematical analysis of categorical feature translations, utilising it in our method. Experimental evaluation with publicly available datasets and user studies demonstrate that GLOBE-CE performs significantly better than the current state-of-the-art across multiple metrics (e.g., speed, reliability).
Robust Counterfactual Explanations for Neural Networks With Probabilistic Guarantees
May 19, 2023



There is an emerging interest in generating robust counterfactual explanations that would remain valid if the model is updated or changed even slightly. Towards finding robust counterfactuals, existing literature often assumes that the original model $m$ and the new model $M$ are bounded in the parameter space, i.e., $\|\text{Params}(M){-}\text{Params}(m)\|{<}\Delta$. However, models can often change significantly in the parameter space with little to no change in their predictions or accuracy on the given dataset. In this work, we introduce a mathematical abstraction termed \emph{naturally-occurring} model change, which allows for arbitrary changes in the parameter space such that the change in predictions on points that lie on the data manifold is limited. Next, we propose a measure -- that we call \emph{Stability} -- to quantify the robustness of counterfactuals to potential model changes for differentiable models, e.g., neural networks. Our main contribution is to show that counterfactuals with sufficiently high value of \emph{Stability} as defined by our measure will remain valid after potential ``naturally-occurring'' model changes with high probability (leveraging concentration bounds for Lipschitz function of independent Gaussians). Since our quantification depends on the local Lipschitz constant around a data point which is not always available, we also examine practical relaxations of our proposed measure and demonstrate experimentally how they can be incorporated to find robust counterfactuals for neural networks that are close, realistic, and remain valid after potential model changes.
Bayesian Hierarchical Models for Counterfactual Estimation
Jan 21, 2023



Counterfactual explanations utilize feature perturbations to analyze the outcome of an original decision and recommend an actionable recourse. We argue that it is beneficial to provide several alternative explanations rather than a single point solution and propose a probabilistic paradigm to estimate a diverse set of counterfactuals. Specifically, we treat the perturbations as random variables endowed with prior distribution functions. This allows sampling multiple counterfactuals from the posterior density, with the added benefit of incorporating inductive biases, preserving domain specific constraints and quantifying uncertainty in estimates. More importantly, we leverage Bayesian hierarchical modeling to share information across different subgroups of a population, which can both improve robustness and measure fairness. A gradient based sampler with superior convergence characteristics efficiently computes the posterior samples. Experiments across several datasets demonstrate that the counterfactuals estimated using our approach are valid, sparse, diverse and feasible.
Learn to explain yourself, when you can: Equipping Concept Bottleneck Models with the ability to abstain on their concept predictions
Nov 21, 2022



The Concept Bottleneck Models (CBMs) of Koh et al. [2020] provide a means to ensure that a neural network based classifier bases its predictions solely on human understandable concepts. The concept labels, or rationales as we refer to them, are learned by the concept labeling component of the CBM. Another component learns to predict the target classification label from these predicted concept labels. Unfortunately, these models are heavily reliant on human provided concept labels for each datapoint. To enable CBMs to behave robustly when these labels are not readily available, we show how to equip them with the ability to abstain from predicting concepts when the concept labeling component is uncertain. In other words, our model learns to provide rationales for its predictions, but only whenever it is sure the rationale is correct.
Rethinking Log Odds: Linear Probability Modelling and Expert Advice in Interpretable Machine Learning
Nov 11, 2022



We introduce a family of interpretable machine learning models, with two broad additions: Linearised Additive Models (LAMs) which replace the ubiquitous logistic link function in General Additive Models (GAMs); and SubscaleHedge, an expert advice algorithm for combining base models trained on subsets of features called subscales. LAMs can augment any additive binary classification model equipped with a sigmoid link function. Moreover, they afford direct global and local attributions of additive components to the model output in probability space. We argue that LAMs and SubscaleHedge improve the interpretability of their base algorithms. Using rigorous null-hypothesis significance testing on a broad suite of financial modelling data, we show that our algorithms do not suffer from large performance penalties in terms of ROC-AUC and calibration.
Towards learning to explain with concept bottleneck models: mitigating information leakage
Nov 07, 2022

Concept bottleneck models perform classification by first predicting which of a list of human provided concepts are true about a datapoint. Then a downstream model uses these predicted concept labels to predict the target label. The predicted concepts act as a rationale for the target prediction. Model trust issues emerge in this paradigm when soft concept labels are used: it has previously been observed that extra information about the data distribution leaks into the concept predictions. In this work we show how Monte-Carlo Dropout can be used to attain soft concept predictions that do not contain leaked information.
Feature Importance for Time Series Data: Improving KernelSHAP
Oct 05, 2022
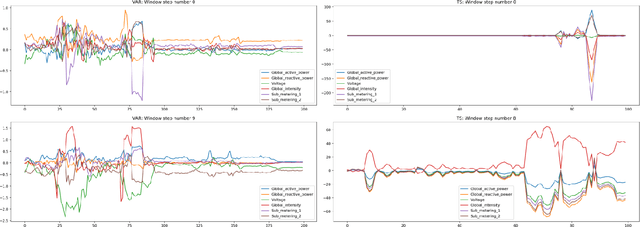
Feature importance techniques have enjoyed widespread attention in the explainable AI literature as a means of determining how trained machine learning models make their predictions. We consider Shapley value based approaches to feature importance, applied in the context of time series data. We present closed form solutions for the SHAP values of a number of time series models, including VARMAX. We also show how KernelSHAP can be applied to time series tasks, and how the feature importances that come from this technique can be combined to perform "event detection". Finally, we explore the use of Time Consistent Shapley values for feature importance.