 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdam-Smith at SemEval-2023 Task 4: Discovering Human Values in Arguments with Ensembles of Transformer-based Models
May 15, 2023
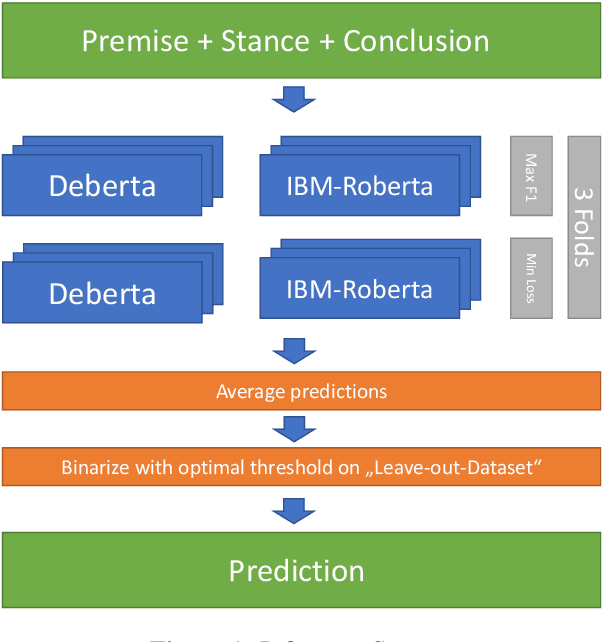

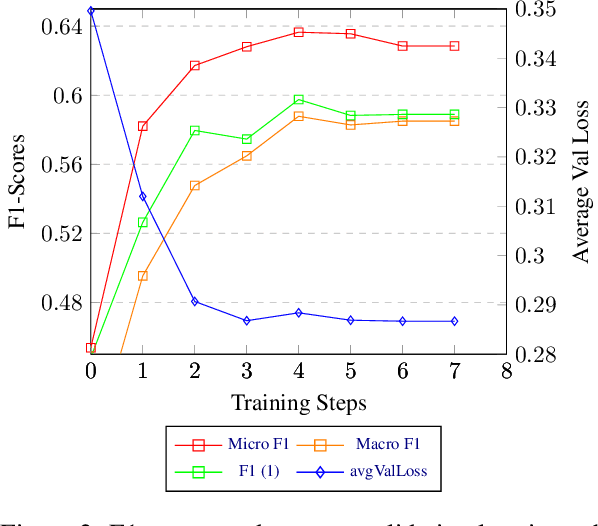
This paper presents the best-performing approach alias "Adam Smith" for the SemEval-2023 Task 4: "Identification of Human Values behind Arguments". The goal of the task was to create systems that automatically identify the values within textual arguments. We train transformer-based models until they reach their loss minimum or f1-score maximum. Ensembling the models by selecting one global decision threshold that maximizes the f1-score leads to the best-performing system in the competition. Ensembling based on stacking with logistic regressions shows the best performance on an additional dataset provided to evaluate the robustness ("Nahj al-Balagha"). Apart from outlining the submitted system, we demonstrate that the use of the large ensemble model is not necessary and that the system size can be significantly reduced.