 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIA-EPT: Membership Inference Attack via Error Prediction for Tabular Data
Sep 16, 2025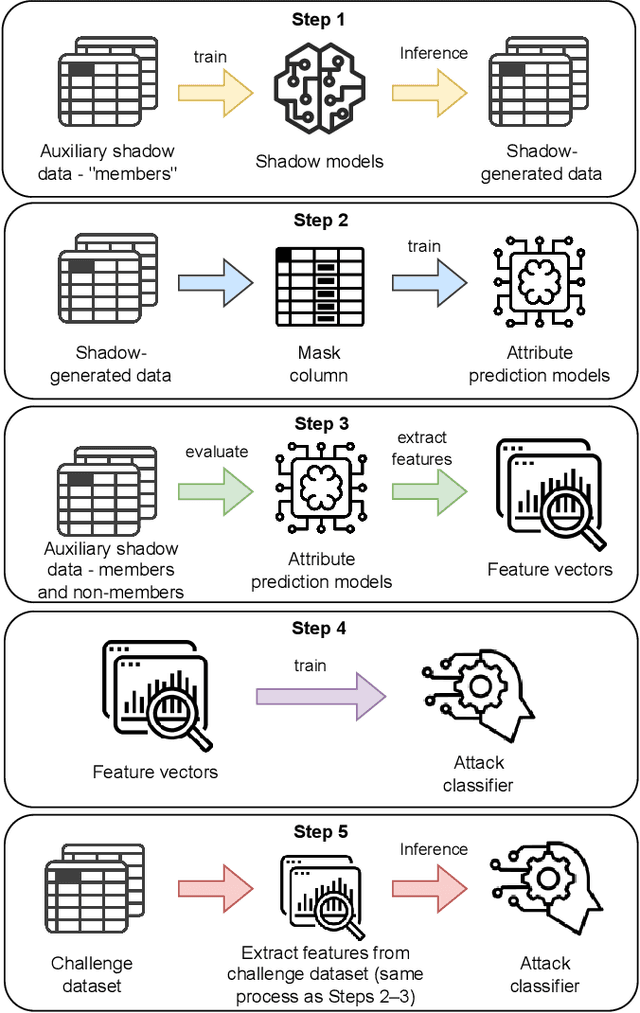

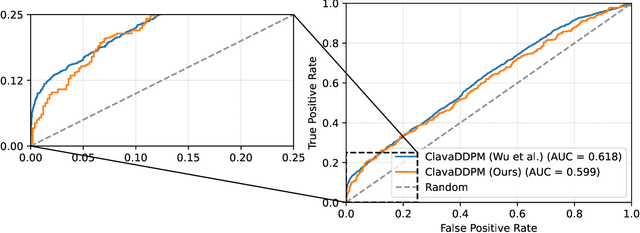
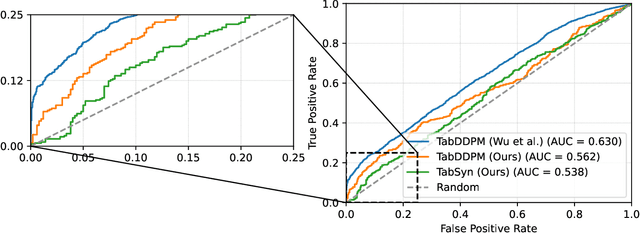
Synthetic data generation plays an important role in enabling data sharing, particularly in sensitive domains like healthcare and finance. Recent advances in diffusion models have made it possible to generate realistic, high-quality tabular data, but they may also memorize training records and leak sensitive information. Membership inference attacks (MIAs) exploit this vulnerability by determining whether a record was used in training. While MIAs have been studied in images and text, their use against tabular diffusion models remains underexplored despite the unique risks of structured attributes and limited record diversity. In this paper, we introduce MIAEPT, Membership Inference Attack via Error Prediction for Tabular Data, a novel black-box attack specifically designed to target tabular diffusion models. MIA-EPT constructs errorbased feature vectors by masking and reconstructing attributes of target records, disclosing membership signals based on how well these attributes are predicted. MIA-EPT operates without access to the internal components of the generative model, relying only on its synthetic data output, and was shown to generalize across multiple state-of-the-art diffusion models. We validate MIA-EPT on three diffusion-based synthesizers, achieving AUC-ROC scores of up to 0.599 and TPR@10% FPR values of 22.0% in our internal tests. Under the MIDST 2025 competition conditions, MIA-EPT achieved second place in the Black-box Multi-Table track (TPR@10% FPR = 20.0%). These results demonstrate that our method can uncover substantial membership leakage in synthetic tabular data, challenging the assumption that synthetic data is inherently privacy-preserving. Our code is publicly available at https://github.com/eyalgerman/MIA-EPT.
Tab-MIA: A Benchmark Dataset for Membership Inference Attacks on Tabular Data in LLMs
Jul 23, 2025Large language models (LLMs) are increasingly trained on tabular data, which, unlike unstructured text, often contains personally identifiable information (PII) in a highly structured and explicit format. As a result, privacy risks arise, since sensitive records can be inadvertently retained by the model and exposed through data extraction or membership inference attacks (MIAs). While existing MIA methods primarily target textual content, their efficacy and threat implications may differ when applied to structured data, due to its limited content, diverse data types, unique value distributions, and column-level semantics. In this paper, we present Tab-MIA, a benchmark dataset for evaluating MIAs on tabular data in LLMs and demonstrate how it can be used. Tab-MIA comprises five data collections, each represented in six different encoding formats. Using our Tab-MIA benchmark, we conduct the first evaluation of state-of-the-art MIA methods on LLMs finetuned with tabular data across multiple encoding formats. In the evaluation, we analyze the memorization behavior of pretrained LLMs on structured data derived from Wikipedia tables. Our findings show that LLMs memorize tabular data in ways that vary across encoding formats, making them susceptible to extraction via MIAs. Even when fine-tuned for as few as three epochs, models exhibit high vulnerability, with AUROC scores approaching 90% in most cases. Tab-MIA enables systematic evaluation of these risks and provides a foundation for developing privacy-preserving methods for tabular data in LLMs.