 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Rank Matrix Completion via Grassmannian Proxy Fusion
Jan 30, 2026This paper approaches high-rank matrix completion (HRMC) by filling missing entries in a data matrix where columns lie near a union of subspaces, clustering these columns, and identifying the underlying subspaces. Current methods often lack theoretical support, produce uninterpretable results, and require more samples than theoretically necessary. We propose clustering incomplete vectors by grouping proxy subspaces and minimizing two criteria over the Grassmannian: (a) the chordal distance between each point and its corresponding subspace and (b) the geodesic distances between subspaces of all data points. Experiments on synthetic and real datasets demonstrate that our method performs comparably to leading methods in high sampling rates and significantly better in low sampling rates, thus narrowing the gap to the theoretical sampling limit of HRMC.
Subspace Clustering on Incomplete Data with Self-Supervised Contrastive Learning
Jan 30, 2026Subspace clustering aims to group data points that lie in a union of low-dimensional subspaces and finds wide application in computer vision, hyperspectral imaging, and recommendation systems. However, most existing methods assume fully observed data, limiting their effectiveness in real-world scenarios with missing entries. In this paper, we propose a contrastive self-supervised framework, Contrastive Subspace Clustering (CSC), designed for clustering incomplete data. CSC generates masked views of partially observed inputs and trains a deep neural network using a SimCLR-style contrastive loss to learn invariant embeddings. These embeddings are then clustered using sparse subspace clustering. Experiments on six benchmark datasets show that CSC consistently outperforms both classical and deep learning baselines, demonstrating strong robustness to missing data and scalability to large datasets.
Exact Minimum-Volume Confidence Set Intersection for Multinomial Outcomes
Jan 26, 2026Computation of confidence sets is central to data science and machine learning, serving as the workhorse of A/B testing and underpinning the operation and analysis of reinforcement learning algorithms. Among all valid confidence sets for the multinomial parameter, minimum-volume confidence sets (MVCs) are optimal in that they minimize average volume, but they are defined as level sets of an exact p-value that is discontinuous and difficult to compute. Rather than attempting to characterize the geometry of MVCs directly, this paper studies a practically motivated decision problem: given two observed multinomial outcomes, can one certify whether their MVCs intersect? We present a certified, tolerance-aware algorithm for this intersection problem. The method exploits the fact that likelihood ordering induces halfspace constraints in log-odds coordinates, enabling adaptive geometric partitioning of parameter space and computable lower and upper bounds on p-values over each cell. For three categories, this yields an efficient and provably sound algorithm that either certifies intersection, certifies disjointness, or returns an indeterminate result when the decision lies within a prescribed margin. We further show how the approach extends to higher dimensions. The results demonstrate that, despite their irregular geometry, MVCs admit reliable certified decision procedures for core tasks in A/B testing.
Contrastive Learning with Orthonormal Anchors (CLOA)
Mar 27, 2024This study focuses on addressing the instability issues prevalent in contrastive learning, specifically examining the InfoNCE loss function and its derivatives. We reveal a critical observation that these loss functions exhibit a restrictive behavior, leading to a convergence phenomenon where embeddings tend to merge into a singular point. This "over-fusion" effect detrimentally affects classification accuracy in subsequent supervised-learning tasks. Through theoretical analysis, we demonstrate that embeddings, when equalized or confined to a rank-1 linear subspace, represent a local minimum for InfoNCE. In response to this challenge, our research introduces an innovative strategy that leverages the same or fewer labeled data than typically used in the fine-tuning phase. The loss we proposed, Orthonormal Anchor Regression Loss, is designed to disentangle embedding clusters, significantly enhancing the distinctiveness of each embedding while simultaneously ensuring their aggregation into dense, well-defined clusters. Our method demonstrates remarkable improvements with just a fraction of the conventional label requirements, as evidenced by our results on CIFAR10 and CIFAR100 datasets.
TransFusion: Contrastive Learning with Transformers
Mar 27, 2024



This paper proposes a novel framework, TransFusion, designed to make the process of contrastive learning more analytical and explainable. TransFusion consists of attention blocks whose softmax being replaced by ReLU, and its final block's weighted-sum operation is truncated to leave the adjacency matrix as the output. The model is trained by minimizing the Jensen-Shannon Divergence between its output and the target affinity matrix, which indicates whether each pair of samples belongs to the same or different classes. The main contribution of TransFusion lies in defining a theoretical limit for answering two fundamental questions in the field: the maximum level of data augmentation and the minimum batch size required for effective contrastive learning. Furthermore, experimental results indicate that TransFusion successfully extracts features that isolate clusters from complex real-world data, leading to improved classification accuracy in downstream tasks.
Fusion Subspace Clustering for Incomplete Data
May 22, 2022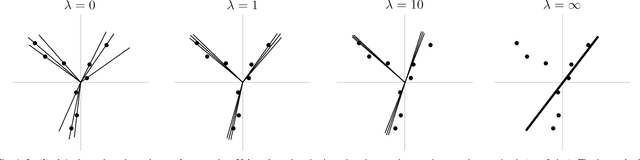
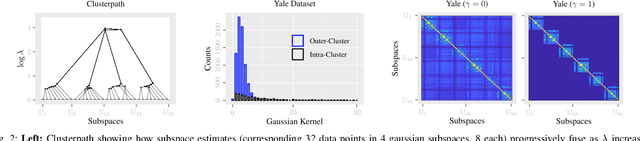
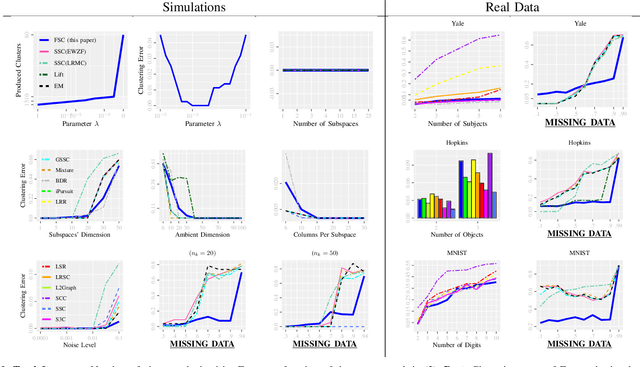
This paper introduces {\em fusion subspace clustering}, a novel method to learn low-dimensional structures that approximate large scale yet highly incomplete data. The main idea is to assign each datum to a subspace of its own, and minimize the distance between the subspaces of all data, so that subspaces of the same cluster get {\em fused} together. Our method allows low, high, and even full-rank data; it directly accounts for noise, and its sample complexity approaches the information-theoretic limit. In addition, our approach provides a natural model selection {\em clusterpath}, and a direct completion method. We give convergence guarantees, analyze computational complexity, and show through extensive experiments on real and synthetic data that our approach performs comparably to the state-of-the-art with complete data, and dramatically better if data is missing.
Geometry of the Minimum Volume Confidence Sets
Feb 16, 2022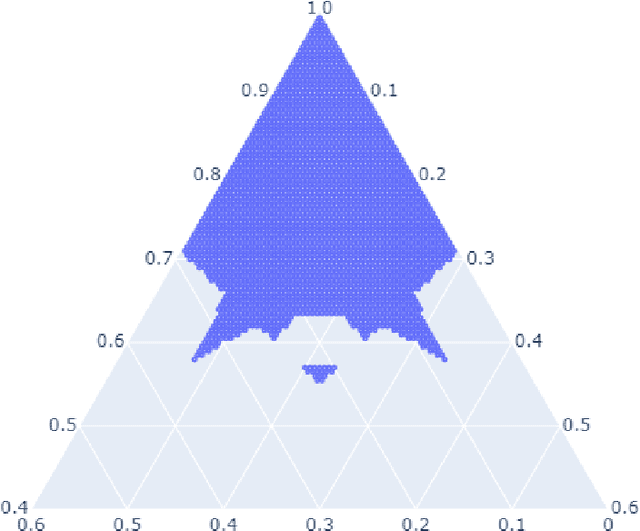
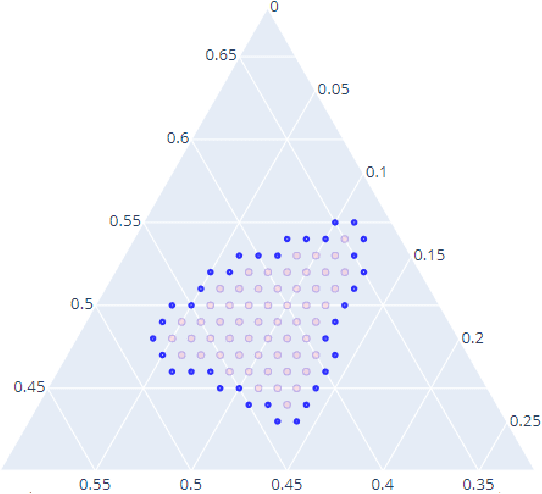
Computation of confidence sets is central to data science and machine learning, serving as the workhorse of A/B testing and underpinning the operation and analysis of reinforcement learning algorithms. This paper studies the geometry of the minimum-volume confidence sets for the multinomial parameter. When used in place of more standard confidence sets and intervals based on bounds and asymptotic approximation, learning algorithms can exhibit improved sample complexity. Prior work showed the minimum-volume confidence sets are the level-sets of a discontinuous function defined by an exact p-value. While the confidence sets are optimal in that they have minimum average volume, computation of membership of a single point in the set is challenging for problems of modest size. Since the confidence sets are level-sets of discontinuous functions, little is apparent about their geometry. This paper studies the geometry of the minimum volume confidence sets by enumerating and covering the continuous regions of the exact p-value function. This addresses a fundamental question in A/B testing: given two multinomial outcomes, how can one determine if their corresponding minimum volume confidence sets are disjoint? We answer this question in a restricted setting.
Tensor Methods for Nonlinear Matrix Completion
Apr 26, 2018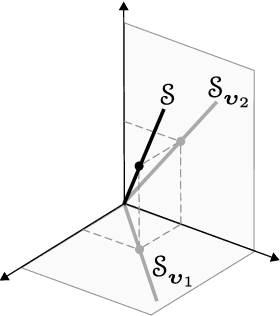
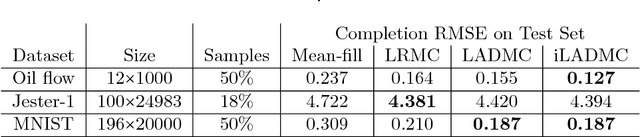

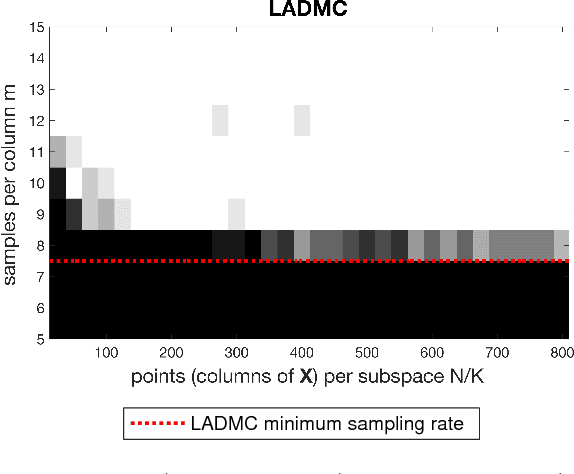
In the low rank matrix completion (LRMC) problem, the low rank assumption means that the columns (or rows) of the matrix to be completed are points on a low-dimensional linear algebraic variety. This paper extends this thinking to cases where the columns are points on a low-dimensional nonlinear algebraic variety, a problem we call Low Algebraic Dimension Matrix Completion (LADMC). Matrices whose columns belong to a union of subspaces (UoS) are an important special case. We propose a LADMC algorithm that leverages existing LRMC methods on a tensorized representation of the data. For example, a second-order tensorization representation is formed by taking the outer product of each column with itself, and we consider higher order tensorizations as well. This approach will succeed in many cases where traditional LRMC is guaranteed to fail because the data are low-rank in the tensorized representation but not in the original representation. We also provide a formal mathematical justification for the success of our method. In particular, we show bounds of the rank of these data in the tensorized representation, and we prove sampling requirements to guarantee uniqueness of the solution. Interestingly, the sampling requirements of our LADMC algorithm nearly match the information theoretic lower bounds for matrix completion under a UoS model. We also provide experimental results showing that the new approach significantly outperforms existing state-of-the-art methods for matrix completion in many situations.