 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREX: Tree-Ensemble Representer-Point Explanations
Sep 24, 2020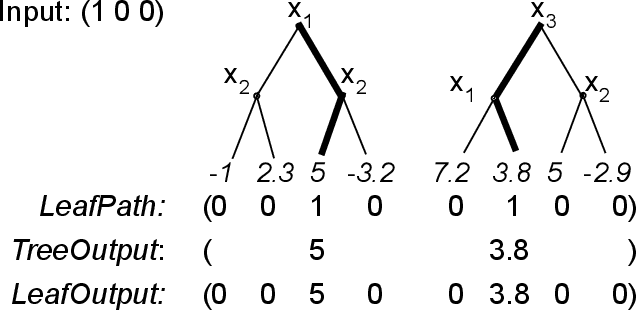
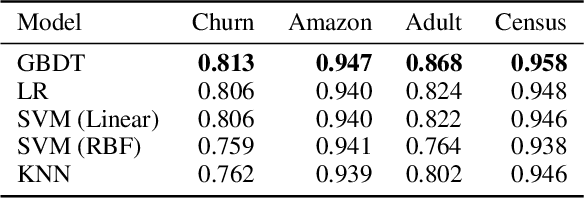
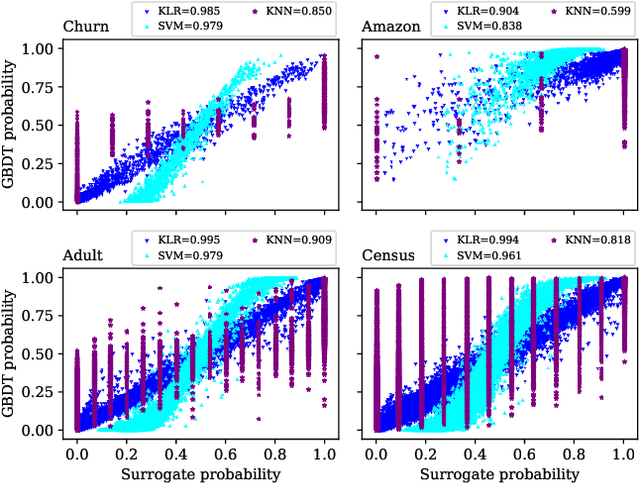
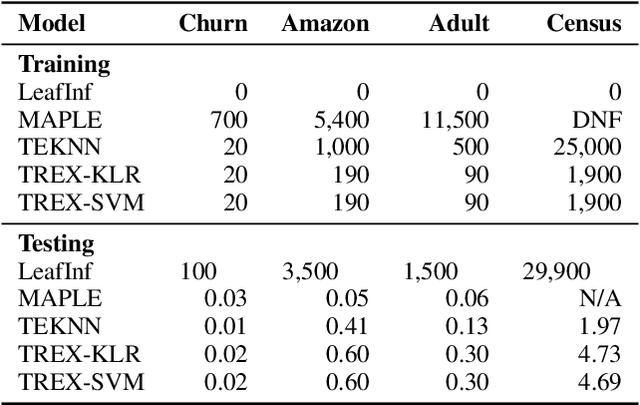
How can we identify the training examples that contribute most to the prediction of a tree ensemble? In this paper, we introduce TREX, an explanation system that provides instance-attribution explanations for tree ensembles, such as random forests and gradient boosted trees. TREX builds on the representer point framework previously developed for explaining deep neural networks. Since tree ensembles are non-differentiable, we define a kernel that captures the structure of the specific tree ensemble. By using this kernel in kernel logistic regression or a support vector machine, TREX builds a surrogate model that approximates the original tree ensemble. The weights in the kernel expansion of the surrogate model are used to define the global or local importance of each training example. Our experiments show that TREX's surrogate model accurately approximates the tree ensemble; its global importance weights are more effective in dataset debugging than the previous state-of-the-art; its explanations identify the most influential samples better than alternative methods under the remove and retrain evaluation framework; it runs orders of magnitude faster than alternative methods; and its local explanations can identify and explain errors due to domain mismatch.
DART: Data Addition and Removal Trees
Sep 11, 2020
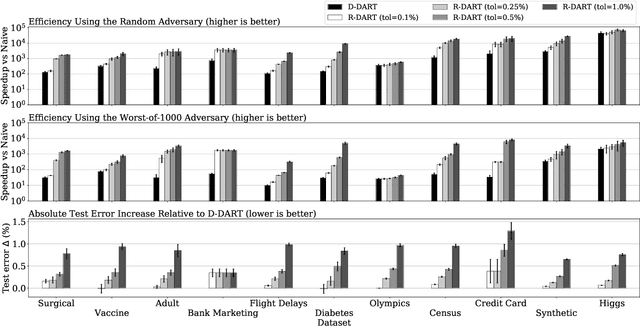
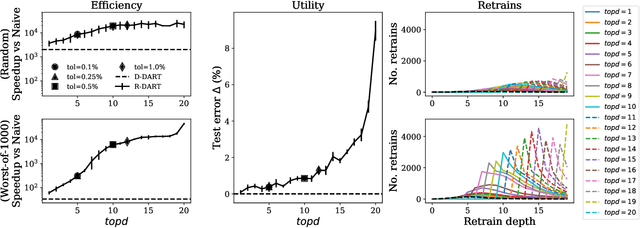
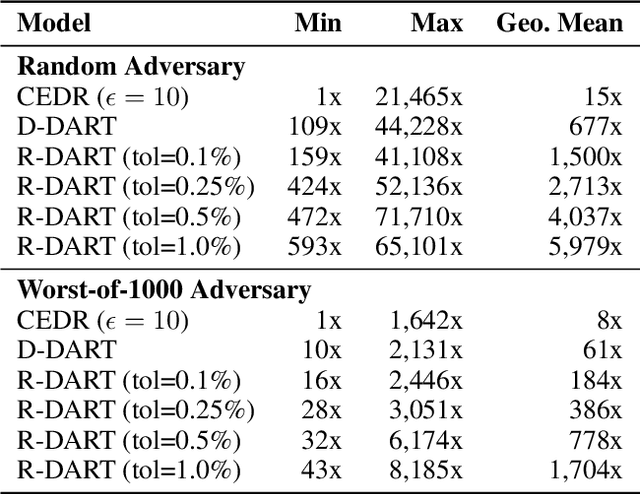
How can we update data for a machine learning model after it has already trained on that data? In this paper, we introduce DART, a variant of random forests that supports adding and removing training data with minimal retraining. Data updates in DART are exact, meaning that adding or removing examples from a DART model yields exactly the same model as retraining from scratch on updated data. DART uses two techniques to make updates efficient. The first is to cache data statistics at each node and training data at each leaf, so that only the necessary subtrees are retrained. The second is to choose the split variable randomly at the upper levels of each tree, so that the choice is completely independent of the data and never needs to change. At the lower levels, split variables are chosen to greedily maximize a split criterion such as Gini index or mutual information. By adjusting the number of random-split levels, DART can trade off between more accurate predictions and more efficient updates. In experiments on ten real-world datasets and one synthetic dataset, we find that DART is orders of magnitude faster than retraining from scratch while sacrificing very little in terms of predictive performance.
Learning from Positive and Unlabeled Data with Arbitrary Positive Shift
Feb 24, 2020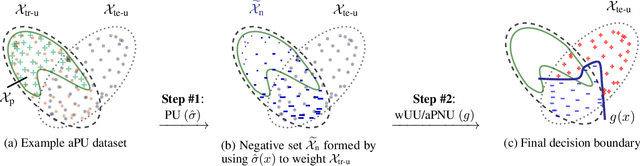
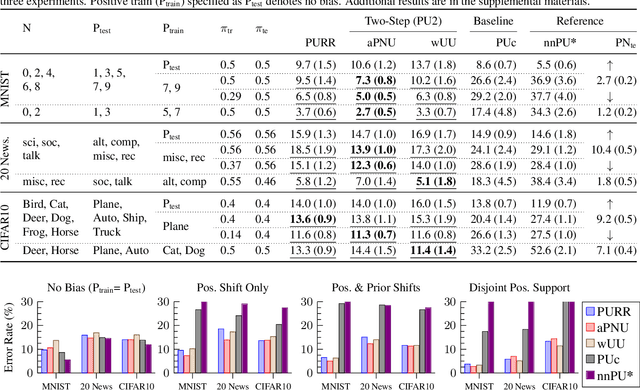
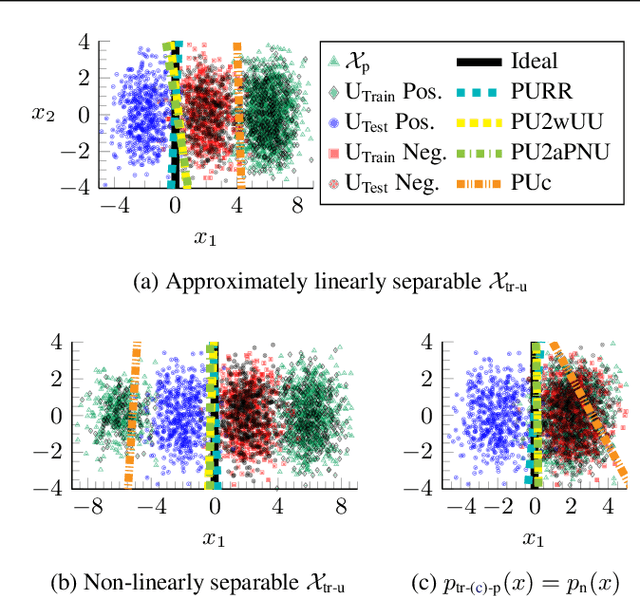
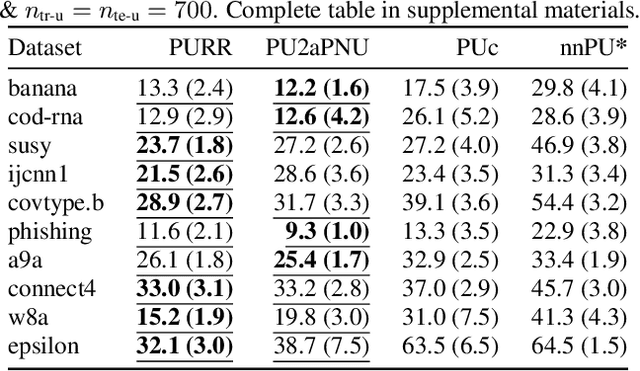
Positive-unlabeled (PU) learning trains a binary classifier using only positive and unlabeled data. A common simplifying assumption is that the positive data is representative of the target positive class. This assumption is often violated in practice due to time variation, domain shift, or adversarial concept drift. This paper shows that PU learning is possible even with arbitrarily non-representative positive data when provided unlabeled datasets from the source and target distributions. Our key insight is that only the negative class's distribution need be fixed. We propose two methods to learn under such arbitrary positive bias. The first couples negative-unlabeled (NU) learning with unlabeled-unlabeled (UU) learning while the other uses a novel recursive risk estimator robust to positive shift. Experimental results demonstrate our methods' effectiveness across numerous real-world datasets and forms of positive data bias, including disjoint positive class-conditional supports.
EGGS: A Flexible Approach to Relational Modeling of Social Network Spam
Jan 28, 2020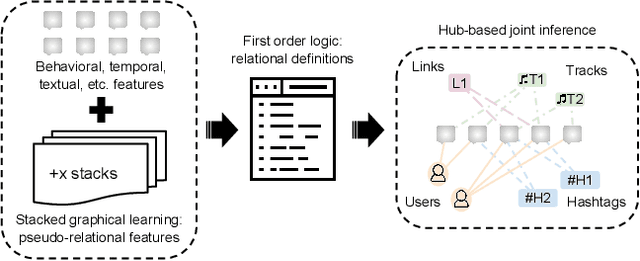
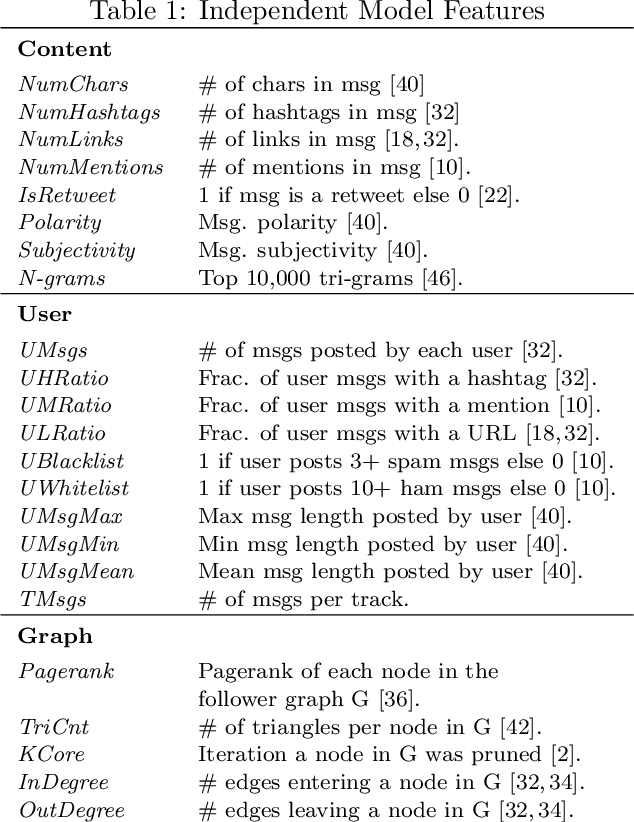

Social networking websites face a constant barrage of spam, unwanted messages that distract, annoy, and even defraud honest users. These messages tend to be very short, making them difficult to identify in isolation. Furthermore, spammers disguise their messages to look legitimate, tricking users into clicking on links and tricking spam filters into tolerating their malicious behavior. Thus, some spam filters examine relational structure in the domain, such as connections among users and messages, to better identify deceptive content. However, even when it is used, relational structure is often exploited in an incomplete or ad hoc manner. In this paper, we present Extended Group-based Graphical models for Spam (EGGS), a general-purpose method for classifying spam in online social networks. Rather than labeling each message independently, we group related messages together when they have the same author, the same content, or other domain-specific connections. To reason about related messages, we combine two popular methods: stacked graphical learning (SGL) and probabilistic graphical models (PGM). Both methods capture the idea that messages are more likely to be spammy when related messages are also spammy, but they do so in different ways; SGL uses sequential classifier predictions and PGMs use probabilistic inference. We apply our method to four different social network domains. EGGS is more accurate than an independent model in most experimental settings, especially when the correct label is uncertain. For the PGM implementation, we compare Markov logic networks to probabilistic soft logic and find that both work well with neither one dominating, and the combination of SGL and PGMs usually performs better than either on its own.
On Adversarial Examples for Character-Level Neural Machine Translation
Jun 23, 2018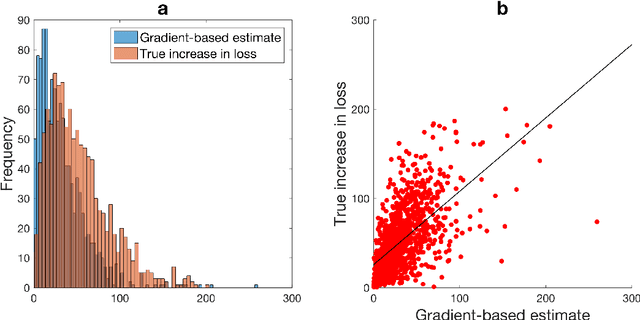
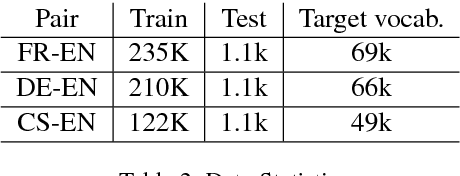
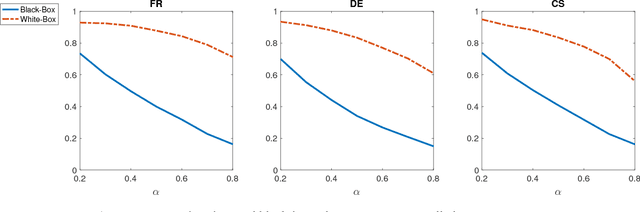
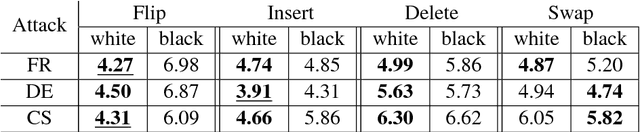
Evaluating on adversarial examples has become a standard procedure to measure robustness of deep learning models. Due to the difficulty of creating white-box adversarial examples for discrete text input, most analyses of the robustness of NLP models have been done through black-box adversarial examples. We investigate adversarial examples for character-level neural machine translation (NMT), and contrast black-box adversaries with a novel white-box adversary, which employs differentiable string-edit operations to rank adversarial changes. We propose two novel types of attacks which aim to remove or change a word in a translation, rather than simply break the NMT. We demonstrate that white-box adversarial examples are significantly stronger than their black-box counterparts in different attack scenarios, which show more serious vulnerabilities than previously known. In addition, after performing adversarial training, which takes only 3 times longer than regular training, we can improve the model's robustness significantly.
HotFlip: White-Box Adversarial Examples for Text Classification
May 24, 2018
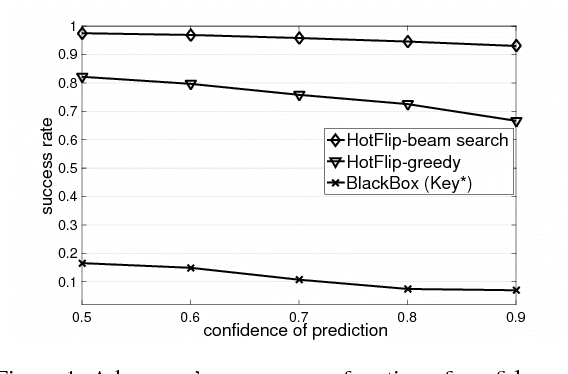
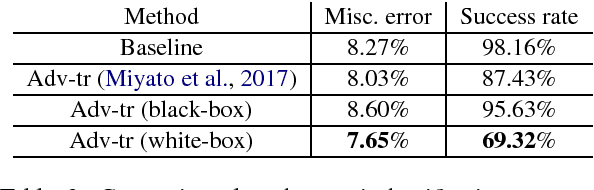

We propose an efficient method to generate white-box adversarial examples to trick a character-level neural classifier. We find that only a few manipulations are needed to greatly decrease the accuracy. Our method relies on an atomic flip operation, which swaps one token for another, based on the gradients of the one-hot input vectors. Due to efficiency of our method, we can perform adversarial training which makes the model more robust to attacks at test time. With the use of a few semantics-preserving constraints, we demonstrate that HotFlip can be adapted to attack a word-level classifier as well.
Neural-Symbolic Learning and Reasoning: A Survey and Interpretation
Nov 10, 2017

The study and understanding of human behaviour is relevant to computer science, artificial intelligence, neural computation, cognitive science, philosophy, psychology, and several other areas. Presupposing cognition as basis of behaviour, among the most prominent tools in the modelling of behaviour are computational-logic systems, connectionist models of cognition, and models of uncertainty. Recent studies in cognitive science, artificial intelligence, and psychology have produced a number of cognitive models of reasoning, learning, and language that are underpinned by computation. In addition, efforts in computer science research have led to the development of cognitive computational systems integrating machine learning and automated reasoning. Such systems have shown promise in a range of applications, including computational biology, fault diagnosis, training and assessment in simulators, and software verification. This joint survey reviews the personal ideas and views of several researchers on neural-symbolic learning and reasoning. The article is organised in three parts: Firstly, we frame the scope and goals of neural-symbolic computation and have a look at the theoretical foundations. We then proceed to describe the realisations of neural-symbolic computation, systems, and applications. Finally we present the challenges facing the area and avenues for further research.
A Probabilistic Approach to Knowledge Translation
Jul 12, 2015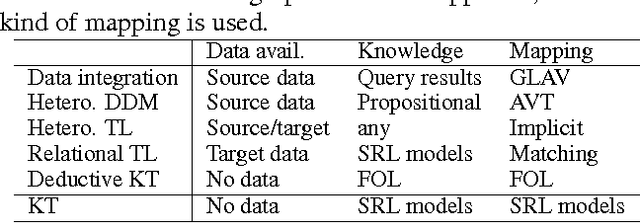
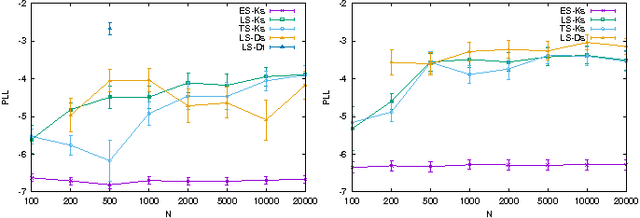
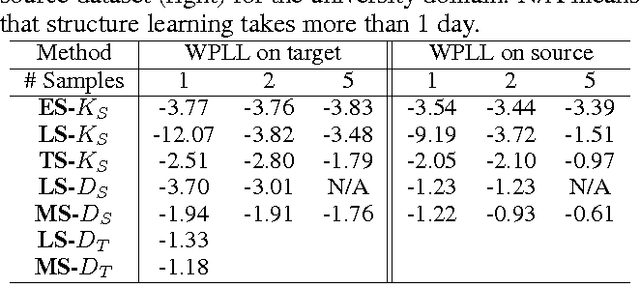
In this paper, we focus on a novel knowledge reuse scenario where the knowledge in the source schema needs to be translated to a semantically heterogeneous target schema. We refer to this task as "knowledge translation" (KT). Unlike data translation and transfer learning, KT does not require any data from the source or target schema. We adopt a probabilistic approach to KT by representing the knowledge in the source schema, the mapping between the source and target schemas, and the resulting knowledge in the target schema all as probability distributions, specially using Markov random fields and Markov logic networks. Given the source knowledge and mappings, we use standard learning and inference algorithms for probabilistic graphical models to find an explicit probability distribution in the target schema that minimizes the Kullback-Leibler divergence from the implicit distribution. This gives us a compact probabilistic model that represents knowledge from the source schema as well as possible, respecting the uncertainty in both the source knowledge and the mapping. In experiments on both propositional and relational domains, we find that the knowledge obtained by KT is comparable to other approaches that require data, demonstrating that knowledge can be reused without data.
Ontology Matching with Knowledge Rules
Jul 11, 2015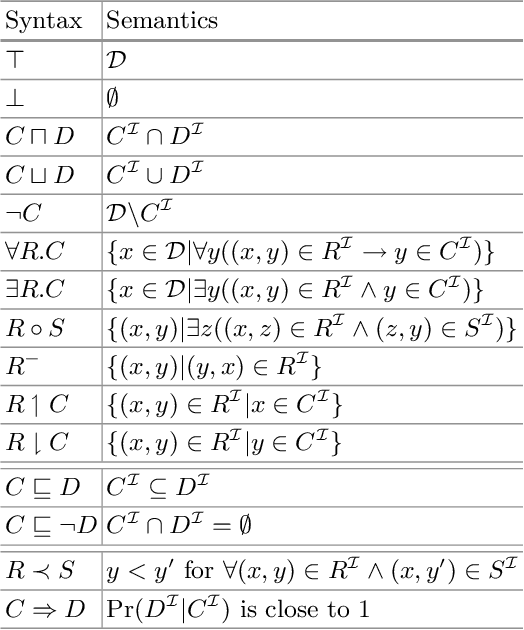
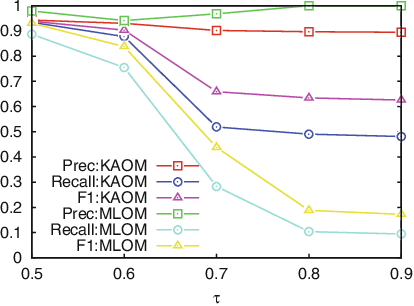
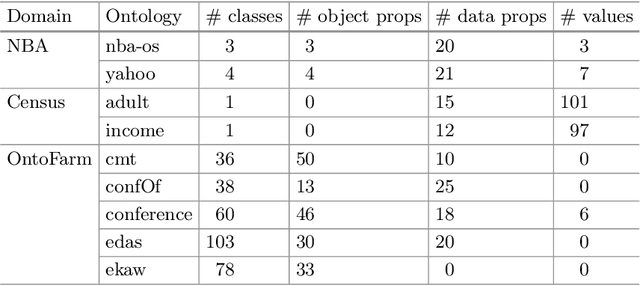
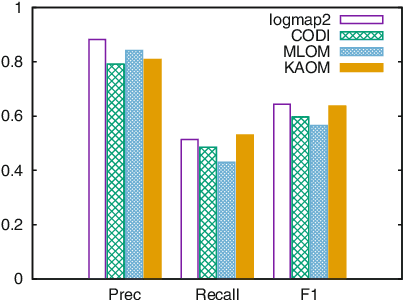
Ontology matching is the process of automatically determining the semantic equivalences between the concepts of two ontologies. Most ontology matching algorithms are based on two types of strategies: terminology-based strategies, which align concepts based on their names or descriptions, and structure-based strategies, which exploit concept hierarchies to find the alignment. In many domains, there is additional information about the relationships of concepts represented in various ways, such as Bayesian networks, decision trees, and association rules. We propose to use the similarities between these relationships to find more accurate alignments. We accomplish this by defining soft constraints that prefer alignments where corresponding concepts have the same local relationships encoded as knowledge rules. We use a probabilistic framework to integrate this new knowledge-based strategy with standard terminology-based and structure-based strategies. Furthermore, our method is particularly effective in identifying correspondences between complex concepts. Our method achieves substantially better F-score than the previous state-of-the-art on three ontology matching domains.
The Libra Toolkit for Probabilistic Models
Apr 01, 2015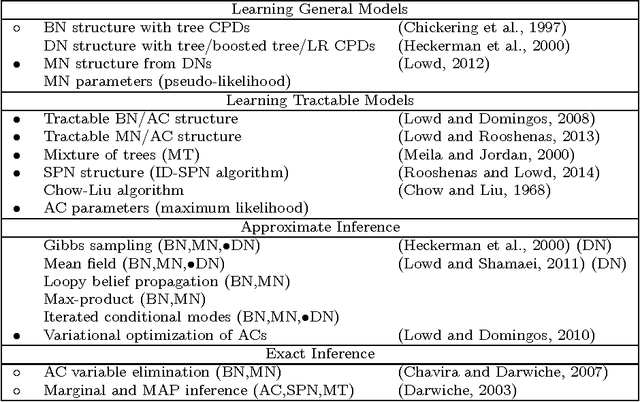
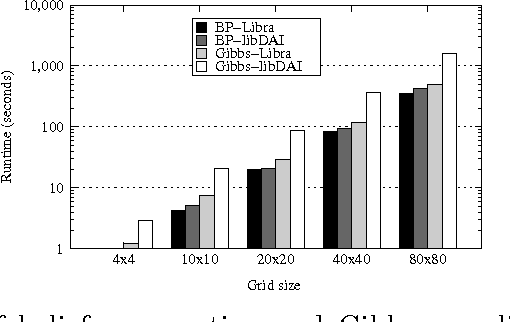
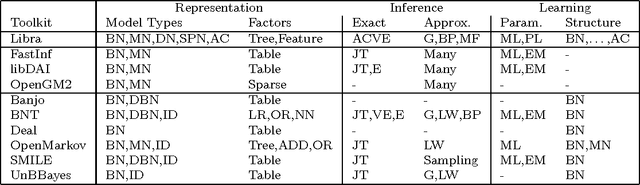
The Libra Toolkit is a collection of algorithms for learning and inference with discrete probabilistic models, including Bayesian networks, Markov networks, dependency networks, and sum-product networks. Compared to other toolkits, Libra places a greater emphasis on learning the structure of tractable models in which exact inference is efficient. It also includes a variety of algorithms for learning graphical models in which inference is potentially intractable, and for performing exact and approximate inference. Libra is released under a 2-clause BSD license to encourage broad use in academia and industry.