 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASTILLO: Characterizing Response Length Distributions of Large Language Models
May 22, 2025



Efficiently managing compute resources for Large Language Model (LLM) inference remains challenging due to the inherently stochastic and variable lengths of autoregressive text generation. Accurately estimating response lengths in advance enables proactive resource allocation, yet existing approaches either bias text generation towards certain lengths or rely on assumptions that ignore model- and prompt-specific variability. We introduce CASTILLO, a dataset characterizing response length distributions across 13 widely-used open-source LLMs evaluated on seven distinct instruction-following corpora. For each $\langle$prompt, model$\rangle$ sample pair, we generate 10 independent completions using fixed decoding hyper-parameters, record the token length of each response, and publish summary statistics (mean, std-dev, percentiles), along with the shortest and longest completions, and the exact generation settings. Our analysis reveals significant inter- and intra-model variability in response lengths (even under identical generation settings), as well as model-specific behaviors and occurrences of partial text degeneration in only subsets of responses. CASTILLO enables the development of predictive models for proactive scheduling and provides a systematic framework for analyzing model-specific generation behaviors. We publicly release the dataset and code to foster research at the intersection of generative language modeling and systems.
Robust Generalization of Graph Neural Networks for Carrier Scheduling
Jul 11, 2024Battery-free sensor tags are devices that leverage backscatter techniques to communicate with standard IoT devices, thereby augmenting a network's sensing capabilities in a scalable way. For communicating, a sensor tag relies on an unmodulated carrier provided by a neighboring IoT device, with a schedule coordinating this provisioning across the network. Carrier scheduling--computing schedules to interrogate all sensor tags while minimizing energy, spectrum utilization, and latency--is an NP-Hard optimization problem. Recent work introduces learning-based schedulers that achieve resource savings over a carefully-crafted heuristic, generalizing to networks of up to 60 nodes. However, we find that their advantage diminishes in networks with hundreds of nodes, and degrades further in larger setups. This paper introduces RobustGANTT, a GNN-based scheduler that improves generalization (without re-training) to networks up to 1000 nodes (100x training topology sizes). RobustGANTT not only achieves better and more consistent generalization, but also computes schedules requiring up to 2x less resources than existing systems. Our scheduler exhibits average runtimes of hundreds of milliseconds, allowing it to react fast to changing network conditions. Our work not only improves resource utilization in large-scale backscatter networks, but also offers valuable insights in learning-based scheduling.
DeepGANTT: A Scalable Deep Learning Scheduler for Backscatter Networks
Dec 24, 2021



Recent backscatter communication techniques enable ultra low power wireless devices that operate without batteries while interoperating directly with unmodified commodity wireless devices. Commodity devices cooperate in providing the unmodulated carrier that the battery-free nodes need to communicate while collecting energy from their environment to perform sensing, computation, and communication tasks. The optimal provision of the unmodulated carrier limits the size of the network because it is an NP-hard combinatorial optimization problem. Consequently, previous works either ignore carrier optimization altogether or resort to suboptimal heuristics, wasting valuable energy and spectral resources. We present DeepGANTT, a deep learning scheduler for battery-free devices interoperating with wireless commodity ones. DeepGANTT leverages graph neural networks to overcome variable input and output size challenges inherent to this problem. We train our deep learning scheduler with optimal schedules of relatively small size obtained from a constraint optimization solver. DeepGANTT not only outperforms a carefully crafted heuristic solution but also performs within ~3% of the optimal scheduler on trained problem sizes. Finally, DeepGANTT generalizes to problems more than four times larger than the maximum used for training, therefore breaking the scalability limitations of the optimal scheduler and paving the way for more efficient backscatter networks.
Learning Combinatorial Optimization on Graphs: A Survey with Applications to Networking
May 22, 2020
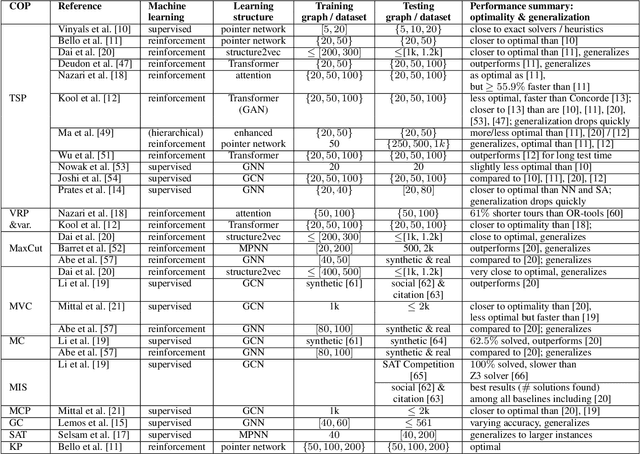
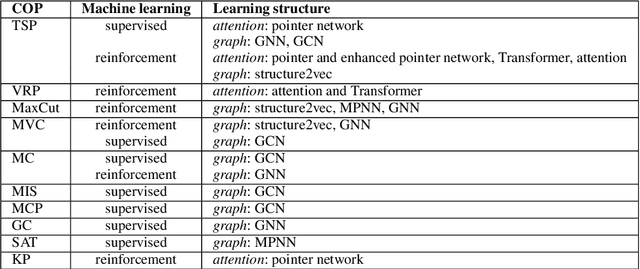

Existing approaches to solving combinatorial optimization problems on graphs suffer from the need to engineer each problem algorithmically, with practical problems recurring in many instances. The practical side of theoretical computer science, such as computational complexity then needs to be addressed. Relevant developments in machine learning research on graphs is surveyed, for this purpose. We organize and compare the structures involved with learning to solve combinatorial optimization problems, with a special eye on the telecommunications domain and its continuous development of live and research networks.