 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRELATE: A Modern Processing Platform for Romanian Language
Oct 29, 2024This paper presents the design and evolution of the RELATE platform. It provides a high-performance environment for natural language processing activities, specially constructed for Romanian language. Initially developed for text processing, it has been recently updated to integrate audio processing tools. Technical details are provided with regard to core components. We further present different usage scenarios, derived from actual use in national and international research projects, thus demonstrating that RELATE is a mature, modern, state-of-the-art platform for processing Romanian language corpora. Finally, we present very recent developments including bimodal (text and audio) features available within the platform.
Towards Improving the Performance of Pre-Trained Speech Models for Low-Resource Languages Through Lateral Inhibition
Jun 30, 2023


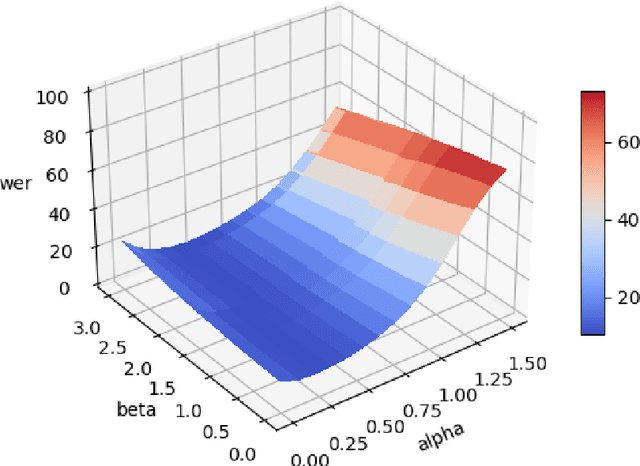
With the rise of bidirectional encoder representations from Transformer models in natural language processing, the speech community has adopted some of their development methodologies. Therefore, the Wav2Vec models were introduced to reduce the data required to obtain state-of-the-art results. This work leverages this knowledge and improves the performance of the pre-trained speech models by simply replacing the fine-tuning dense layer with a lateral inhibition layer inspired by the biological process. Our experiments on Romanian, a low-resource language, show an average improvement of 12.5% word error rate (WER) using the lateral inhibition layer. In addition, we obtain state-of-the-art results on both the Romanian Speech Corpus and the Robin Technical Acquisition Corpus with 1.78% WER and 29.64% WER, respectively.
Distilling the Knowledge of Romanian BERTs Using Multiple Teachers
Jan 11, 2022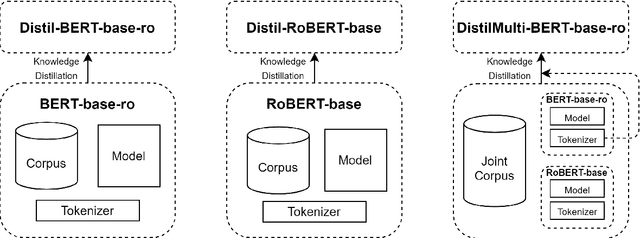
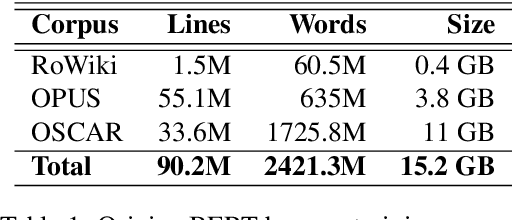

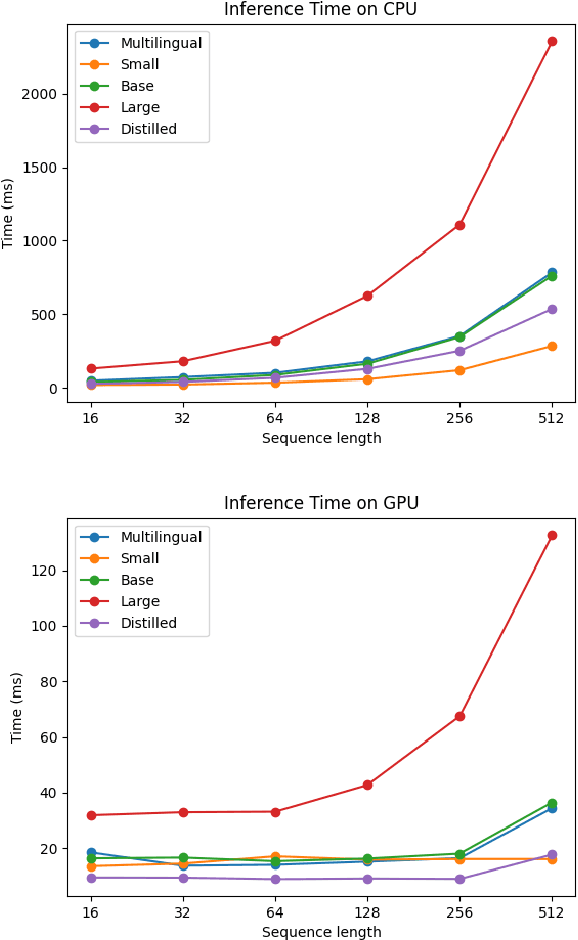
Running large-scale pre-trained language models in computationally constrained environments remains a challenging problem yet to be addressed, while transfer learning from these models has become prevalent in Natural Language Processing tasks. Several solutions, including knowledge distillation, network quantization, or network pruning have been previously proposed; however, these approaches focus mostly on the English language, thus widening the gap when considering low-resource languages. In this work, we introduce three light and fast versions of distilled BERT models for the Romanian language: Distil-BERT-base-ro, Distil-RoBERT-base, and DistilMulti-BERT-base-ro. The first two models resulted from the individual distillation of knowledge from two base versions of Romanian BERTs available in literature, while the last one was obtained by distilling their ensemble. To our knowledge, this is the first attempt to create publicly available Romanian distilled BERT models, which were thoroughly evaluated on five tasks: part-of-speech tagging, named entity recognition, sentiment analysis, semantic textual similarity, and dialect identification. Our experimental results argue that the three distilled models maintain most performance in terms of accuracy with their teachers, while being twice as fast on a GPU and ~35% smaller. In addition, we further test the similarity between the predictions of our students versus their teachers by measuring their label and probability loyalty, together with regression loyalty - a new metric introduced in this work.
Romanian Speech Recognition Experiments from the ROBIN Project
Nov 23, 2021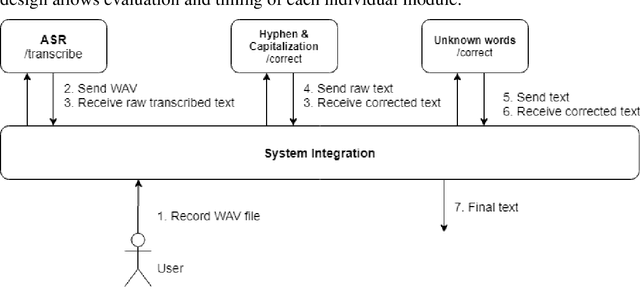
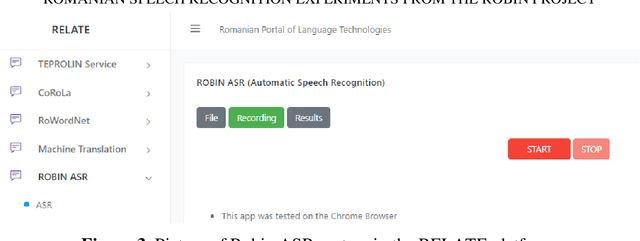
One of the fundamental functionalities for accepting a socially assistive robot is its communication capabilities with other agents in the environment. In the context of the ROBIN project, situational dialogue through voice interaction with a robot was investigated. This paper presents different speech recognition experiments with deep neural networks focusing on producing fast (under 100ms latency from the network itself), while still reliable models. Even though one of the key desired characteristics is low latency, the final deep neural network model achieves state of the art results for recognizing Romanian language, obtaining a 9.91% word error rate (WER), when combined with a language model, thus improving over the previous results while offering at the same time an improved runtime performance. Additionally, we explore two modules for correcting the ASR output (hyphen and capitalization restoration and unknown words correction), targeting the ROBIN project's goals (dialogue in closed micro-worlds). We design a modular architecture based on APIs allowing an integration engine (either in the robot or external) to chain together the available modules as needed. Finally, we test the proposed design by integrating it in the RELATE platform and making the ASR service available to web users by either uploading a file or recording new speech.
More Romanian word embeddings from the RETEROM project
Nov 21, 2021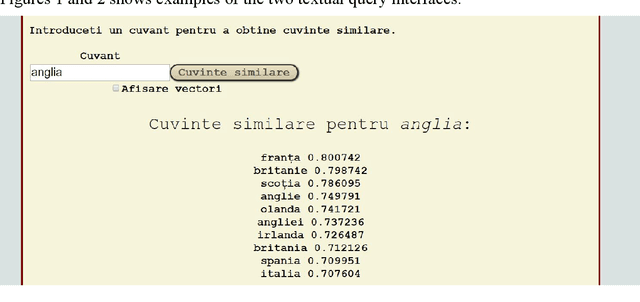
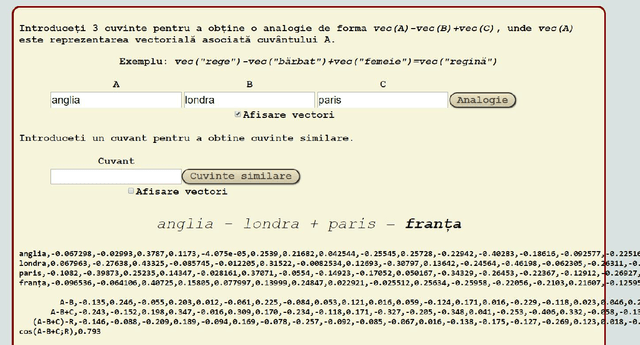

Automatically learned vector representations of words, also known as "word embeddings", are becoming a basic building block for more and more natural language processing algorithms. There are different ways and tools for constructing word embeddings. Most of the approaches rely on raw texts, the construction items being the word occurrences and/or letter n-grams. More elaborated research is using additional linguistic features extracted after text preprocessing. Morphology is clearly served by vector representations constructed from raw texts and letter n-grams. Syntax and semantics studies may profit more from the vector representations constructed with additional features such as lemma, part-of-speech, syntactic or semantic dependants associated with each word. One of the key objectives of the ReTeRom project is the development of advanced technologies for Romanian natural language processing, including morphological, syntactic and semantic analysis of text. As such, we plan to develop an open-access large library of ready-to-use word embeddings sets, each set being characterized by different parameters: used features (wordforms, letter n-grams, lemmas, POSes etc.), vector lengths, window/context size and frequency thresholds. To this end, the previously created sets of word embeddings (based on word occurrences) on the CoRoLa corpus (P\u{a}i\c{s} and Tufi\c{s}, 2018) are and will be further augmented with new representations learned from the same corpus by using specific features such as lemmas and parts of speech. Furthermore, in order to better understand and explore the vectors, graphical representations will be available by customized interfaces.
* Publlished in Proceedings of the 13th International Conference on Linguistic Resources and Tools for Processing Romanian Language - CONSILR 2018. Complete proceedings volume available here: https://profs.info.uaic.ro/~consilr/2019/wp-content/uploads/2019/06/volum-ConsILR-2018-1.pdf
Capitalization and Punctuation Restoration: a Survey
Nov 21, 2021
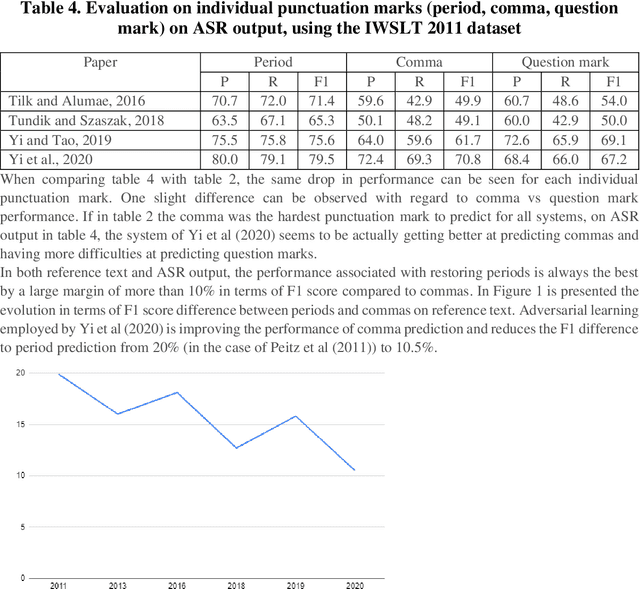
Ensuring proper punctuation and letter casing is a key pre-processing step towards applying complex natural language processing algorithms. This is especially significant for textual sources where punctuation and casing are missing, such as the raw output of automatic speech recognition systems. Additionally, short text messages and micro-blogging platforms offer unreliable and often wrong punctuation and casing. This survey offers an overview of both historical and state-of-the-art techniques for restoring punctuation and correcting word casing. Furthermore, current challenges and research directions are highlighted.
* An improved version of this paper was published in Artificial Intelligence Review. This is the article version prior to any reviewer comments and improvements
The European Language Technology Landscape in 2020: Language-Centric and Human-Centric AI for Cross-Cultural Communication in Multilingual Europe
Mar 30, 2020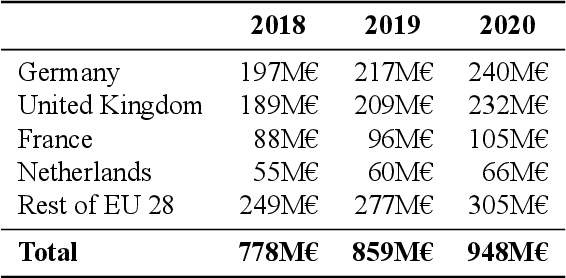
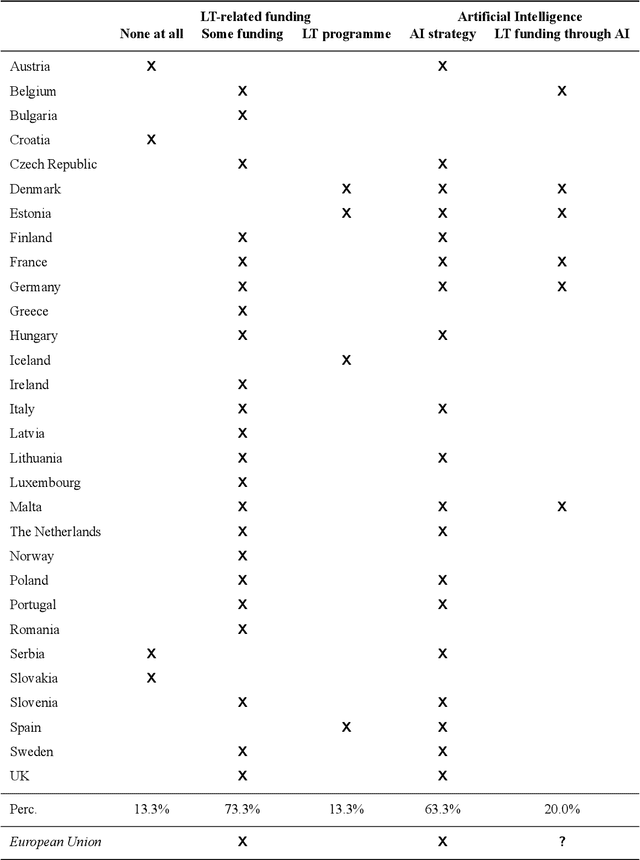
Multilingualism is a cultural cornerstone of Europe and firmly anchored in the European treaties including full language equality. However, language barriers impacting business, cross-lingual and cross-cultural communication are still omnipresent. Language Technologies (LTs) are a powerful means to break down these barriers. While the last decade has seen various initiatives that created a multitude of approaches and technologies tailored to Europe's specific needs, there is still an immense level of fragmentation. At the same time, AI has become an increasingly important concept in the European Information and Communication Technology area. For a few years now, AI, including many opportunities, synergies but also misconceptions, has been overshadowing every other topic. We present an overview of the European LT landscape, describing funding programmes, activities, actions and challenges in the different countries with regard to LT, including the current state of play in industry and the LT market. We present a brief overview of the main LT-related activities on the EU level in the last ten years and develop strategic guidance with regard to four key dimensions.