 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePer-Instance Privacy Accounting for Differentially Private Stochastic Gradient Descent
Jun 07, 2022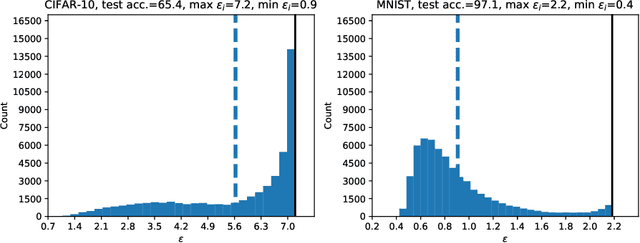
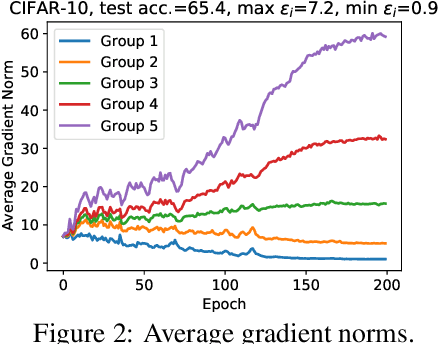

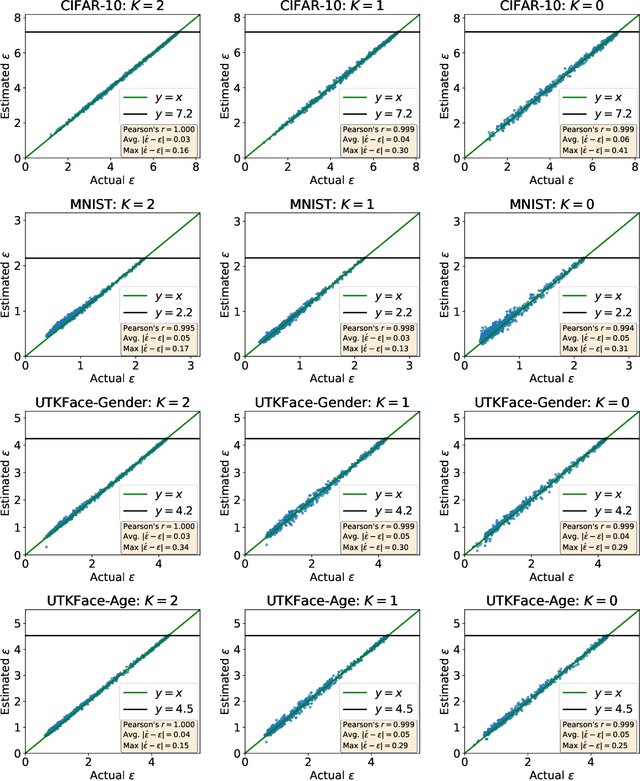
Differentially private stochastic gradient descent (DP-SGD) is the workhorse algorithm for recent advances in private deep learning. It provides a single privacy guarantee to all datapoints in the dataset. We propose an efficient algorithm to compute per-instance privacy guarantees for individual examples when running DP-SGD. We use our algorithm to investigate per-instance privacy losses across a number of datasets. We find that most examples enjoy stronger privacy guarantees than the worst-case bounds. We further discover that the loss and the privacy loss on an example are well-correlated. This implies groups that are underserved in terms of model utility are simultaneously underserved in terms of privacy loss. For example, on CIFAR-10, the average $\epsilon$ of the class with the highest loss (Cat) is 32% higher than that of the class with the lowest loss (Ship). We also run membership inference attacks to show this reflects disparate empirical privacy risks.
Indiscriminate Poisoning Attacks Are Shortcuts
Nov 01, 2021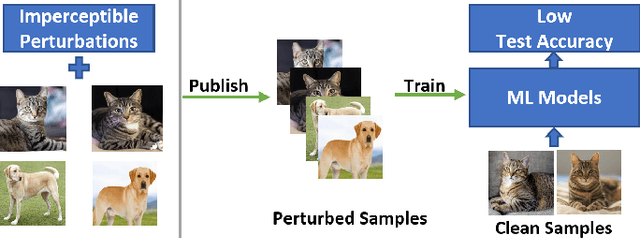
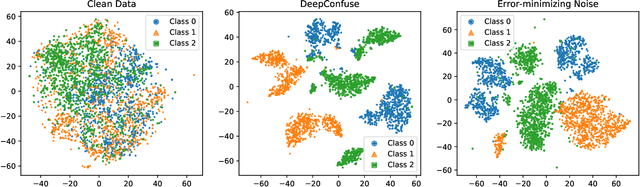
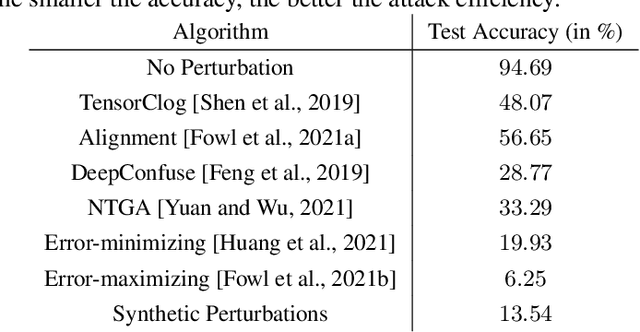

Indiscriminate data poisoning attacks, which add imperceptible perturbations to training data to maximize the test error of trained models, have become a trendy topic because they are thought to be capable of preventing unauthorized use of data. In this work, we investigate why these perturbations work in principle. We find that the perturbations of advanced poisoning attacks are almost \textbf{linear separable} when assigned with the target labels of the corresponding samples, which hence can work as \emph{shortcuts} for the learning objective. This important population property has not been unveiled before. Moreover, we further verify that linear separability is indeed the workhorse for poisoning attacks. We synthesize linear separable data as perturbations and show that such synthetic perturbations are as powerful as the deliberately crafted attacks. Our finding suggests that the \emph{shortcut learning} problem is more serious than previously believed as deep learning heavily relies on shortcuts even if they are of an imperceptible scale and mixed together with the normal features. This finding also suggests that pre-trained feature extractors would disable these poisoning attacks effectively.
Differentially Private Fine-tuning of Language Models
Oct 13, 2021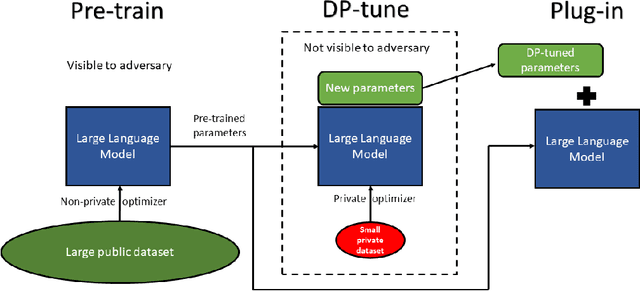


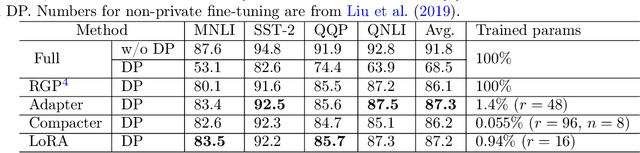
We give simpler, sparser, and faster algorithms for differentially private fine-tuning of large-scale pre-trained language models, which achieve the state-of-the-art privacy versus utility tradeoffs on many standard NLP tasks. We propose a meta-framework for this problem, inspired by the recent success of highly parameter-efficient methods for fine-tuning. Our experiments show that differentially private adaptations of these approaches outperform previous private algorithms in three important dimensions: utility, privacy, and the computational and memory cost of private training. On many commonly studied datasets, the utility of private models approaches that of non-private models. For example, on the MNLI dataset we achieve an accuracy of $87.8\%$ using RoBERTa-Large and $83.5\%$ using RoBERTa-Base with a privacy budget of $\epsilon = 6.7$. In comparison, absent privacy constraints, RoBERTa-Large achieves an accuracy of $90.2\%$. Our findings are similar for natural language generation tasks. Privately fine-tuning with DART, GPT-2-Small, GPT-2-Medium, GPT-2-Large, and GPT-2-XL achieve BLEU scores of 38.5, 42.0, 43.1, and 43.8 respectively (privacy budget of $\epsilon = 6.8,\delta=$ 1e-5) whereas the non-private baseline is $48.1$. All our experiments suggest that larger models are better suited for private fine-tuning: while they are well known to achieve superior accuracy non-privately, we find that they also better maintain their accuracy when privacy is introduced.
Large Scale Private Learning via Low-rank Reparametrization
Jun 28, 2021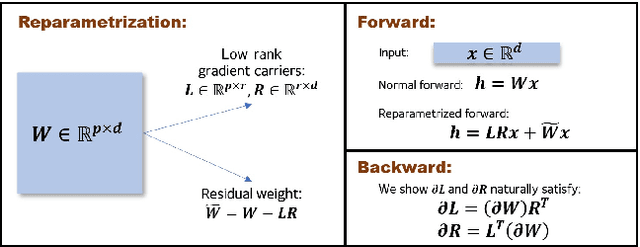

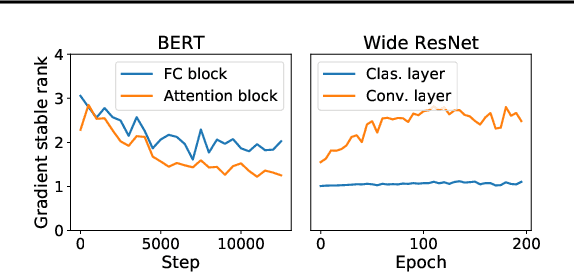
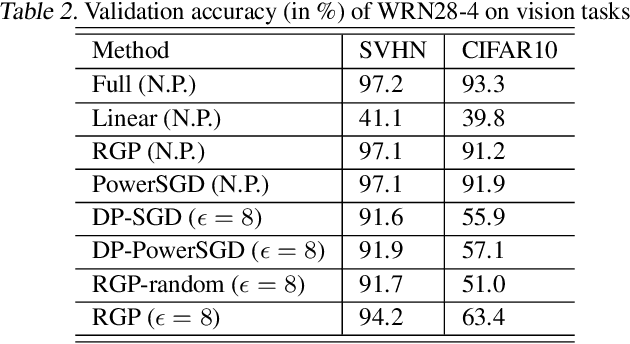
We propose a reparametrization scheme to address the challenges of applying differentially private SGD on large neural networks, which are 1) the huge memory cost of storing individual gradients, 2) the added noise suffering notorious dimensional dependence. Specifically, we reparametrize each weight matrix with two \emph{gradient-carrier} matrices of small dimension and a \emph{residual weight} matrix. We argue that such reparametrization keeps the forward/backward process unchanged while enabling us to compute the projected gradient without computing the gradient itself. To learn with differential privacy, we design \emph{reparametrized gradient perturbation (RGP)} that perturbs the gradients on gradient-carrier matrices and reconstructs an update for the original weight from the noisy gradients. Importantly, we use historical updates to find the gradient-carrier matrices, whose optimality is rigorously justified under linear regression and empirically verified with deep learning tasks. RGP significantly reduces the memory cost and improves the utility. For example, we are the first able to apply differential privacy on the BERT model and achieve an average accuracy of $83.9\%$ on four downstream tasks with $\epsilon=8$, which is within $5\%$ loss compared to the non-private baseline but enjoys much lower privacy leakage risk.
Do Not Let Privacy Overbill Utility: Gradient Embedding Perturbation for Private Learning
Feb 26, 2021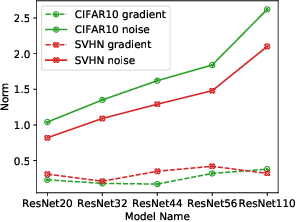
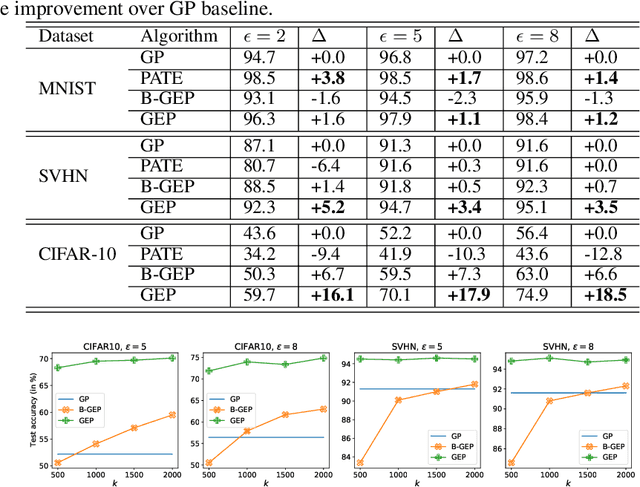
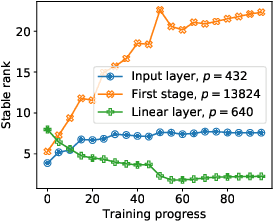
The privacy leakage of the model about the training data can be bounded in the differential privacy mechanism. However, for meaningful privacy parameters, a differentially private model degrades the utility drastically when the model comprises a large number of trainable parameters. In this paper, we propose an algorithm \emph{Gradient Embedding Perturbation (GEP)} towards training differentially private deep models with decent accuracy. Specifically, in each gradient descent step, GEP first projects individual private gradient into a non-sensitive anchor subspace, producing a low-dimensional gradient embedding and a small-norm residual gradient. Then, GEP perturbs the low-dimensional embedding and the residual gradient separately according to the privacy budget. Such a decomposition permits a small perturbation variance, which greatly helps to break the dimensional barrier of private learning. With GEP, we achieve decent accuracy with reasonable computational cost and modest privacy guarantee for deep models. Especially, with privacy bound $\epsilon=8$, we achieve $74.9\%$ test accuracy on CIFAR10 and $95.1\%$ test accuracy on SVHN, significantly improving over existing results.
Membership Inference with Privately Augmented Data Endorses the Benign while Suppresses the Adversary
Jul 21, 2020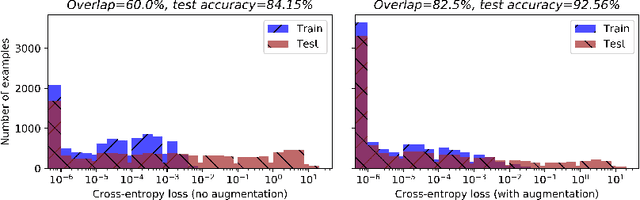
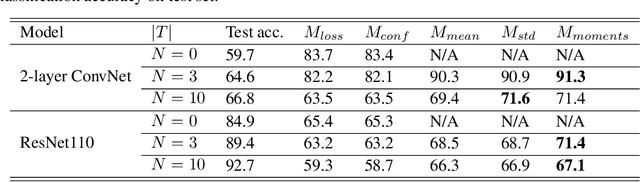
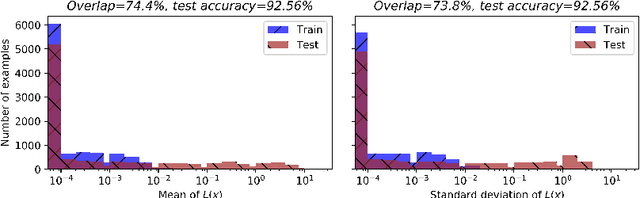

Membership inference (MI) in machine learning decides whether a given example is in target model's training set. It can be used in two ways: adversaries use it to steal private membership information while legitimate users can use it to verify whether their data has been forgotten by a trained model. Therefore, MI is a double-edged sword to privacy preserving machine learning. In this paper, we propose using private augmented data to sharpen its good side while passivate its bad side. To sharpen the good side, we exploit the data augmentation used in training to boost the accuracy of membership inference. Specifically, we compose a set of augmented instances for each sample and then the membership inference is formulated as a set classification problem, i.e., classifying a set of augmented data points instead of one point. We design permutation invariant features based on the losses of augmented instances. Our approach significantly improves the MI accuracy over existing algorithms. To passivate the bad side, we apply different data augmentation methods to each legitimate user and keep the augmented data as secret. We show that the malicious adversaries cannot benefit from our algorithms if being ignorant of the augmented data used in training. Extensive experiments demonstrate the superior efficacy of our algorithms. Our source code is available at anonymous GitHub page \url{https://github.com/AnonymousDLMA/MI_with_DA}.
Gradient Perturbation is Underrated for Differentially Private Convex Optimization
Nov 26, 2019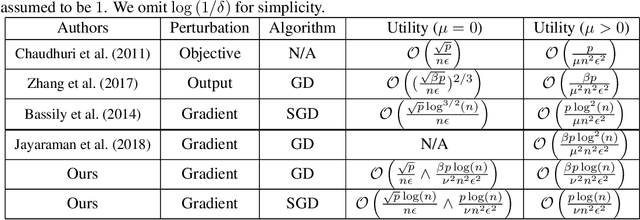
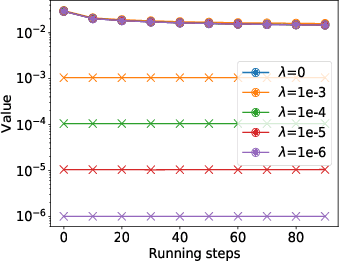
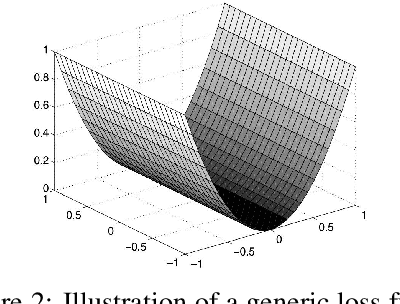
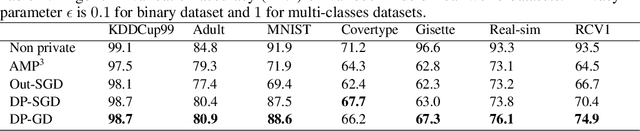
Gradient perturbation, widely used for differentially private optimization, injects noise at every iterative update to guarantee differential privacy. Previous work first determines the noise level that can satisfy the privacy requirement and then analyzes the utility of noisy gradient updates as in non-private case. In this paper, we explore how the privacy noise affects the optimization property. We show that for differentially private convex optimization, the utility guarantee of both DP-GD and DP-SGD is determined by an \emph{expected curvature} rather than the minimum curvature. The \emph{expected curvature} represents the average curvature over the optimization path, which is usually much larger than the minimum curvature and hence can help us achieve a significantly improved utility guarantee. By using the \emph{expected curvature}, our theory justifies the advantage of gradient perturbation over other perturbation methods and closes the gap between theory and practice. Extensive experiments on real world datasets corroborate our theoretical findings.
Training Over-parameterized Deep ResNet Is almost as Easy as Training a Two-layer Network
Mar 17, 2019
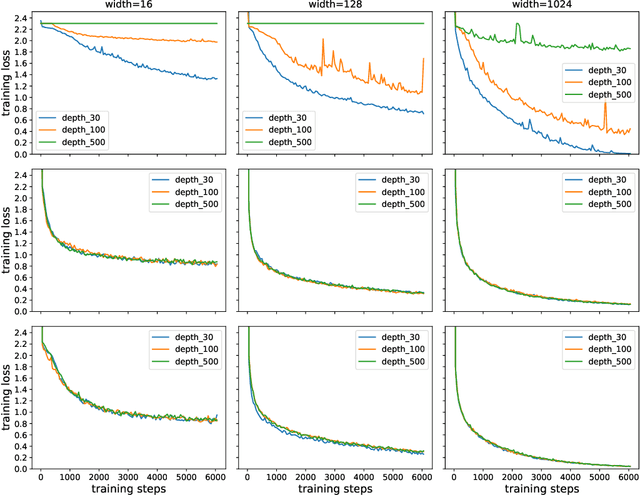
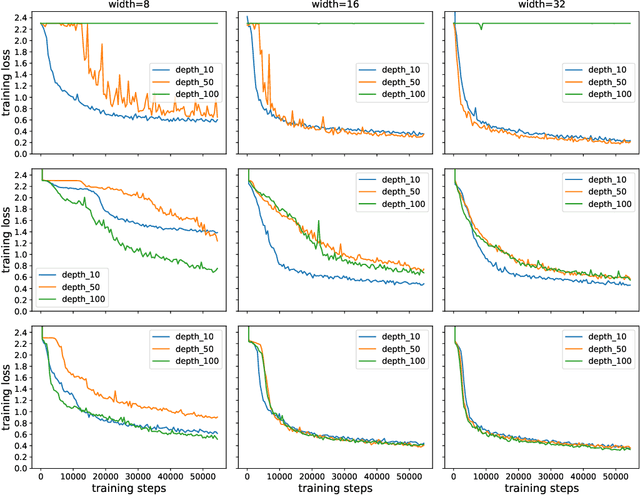
It has been proved that gradient descent converges linearly to the global minima for training deep neural network in the over-parameterized regime. However, according to \citet{allen2018convergence}, the width of each layer should grow at least with the polynomial of the depth (the number of layers) for residual network (ResNet) in order to guarantee the linear convergence of gradient descent, which shows no obvious advantage over feedforward network. In this paper, we successfully remove the dependence of the width on the depth of the network for ResNet and reach a conclusion that training deep residual network can be as easy as training a two-layer network. This theoretically justifies the benefit of skip connection in terms of facilitating the convergence of gradient descent. Our experiments also justify that the width of ResNet to guarantee successful training is much smaller than that of deep feedforward neural network.