 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-MT: Multi-Scale Mean Teacher with Contrastive Unpaired Translation for Cross-Modality Vestibular Schwannoma and Cochlea Segmentation
Mar 28, 2023



Domain shift has been a long-standing issue for medical image segmentation. Recently, unsupervised domain adaptation (UDA) methods have achieved promising cross-modality segmentation performance by distilling knowledge from a label-rich source domain to a target domain without labels. In this work, we propose a multi-scale self-ensembling based UDA framework for automatic segmentation of two key brain structures i.e., Vestibular Schwannoma (VS) and Cochlea on high-resolution T2 images. First, a segmentation-enhanced contrastive unpaired image translation module is designed for image-level domain adaptation from source T1 to target T2. Next, multi-scale deep supervision and consistency regularization are introduced to a mean teacher network for self-ensemble learning to further close the domain gap. Furthermore, self-training and intensity augmentation techniques are utilized to mitigate label scarcity and boost cross-modality segmentation performance. Our method demonstrates promising segmentation performance with a mean Dice score of 83.8% and 81.4% and an average asymmetric surface distance (ASSD) of 0.55 mm and 0.26 mm for the VS and Cochlea, respectively in the validation phase of the crossMoDA 2022 challenge.
Multimodal Continuous Emotion Recognition: A Technical Report for ABAW5
Mar 18, 2023


We used two multimodal models for continuous valence-arousal recognition using visual, audio, and linguistic information. The first model is the same as we used in ABAW2 and ABAW3, which employs the leader-follower attention. The second model has the same architecture for spatial and temporal encoding. As for the fusion block, it employs a compact and straightforward channel attention, borrowed from the End2You toolkit. Unlike our previous attempts that use Vggish feature directly as the audio feature, this time we feed the pre-trained VGG model using logmel-spectrogram and finetune it during the training. To make full use of the data and alleviate over-fitting, cross-validation is carried out. The fold with the highest concordance correlation coefficient is selected for submission. The code is to be available at https://github.com/sucv/ABAW5.
Score-based Data Generation for EEG Spatial Covariance Matrices: Towards Boosting BCI Performance
Feb 22, 2023



The efficacy of Electroencephalogram (EEG) classifiers can be augmented by increasing the quantity of available data. In the case of geometric deep learning classifiers, the input consists of spatial covariance matrices derived from EEGs. To synthesize these spatial covariance matrices, we propose a generative modeling technique based on state-of-the-art score-based models. The quality of generated samples is evaluated through visual and quantitative assessments using a binary-class motor imagery dataset. The exceptional pixel-level resolution of these generative samples highlights the formidable capacity of score-based generative modeling. Additionally, the center (Frechet mean) of the generated samples aligns with neurophysiological evidence that event-related desynchronization and synchronization occur on electrodes C3 and C4 within the Mu and Beta frequency bands during motor imagery processing. The quantitative evaluation revealed that 84.3% of the generated samples could be accurately predicted by a pre-trained classifier and an improvement of up to 8.7% in the average accuracy over ten runs for a specific test subject in a holdout experiment.
LE-UDA: Label-efficient unsupervised domain adaptation for medical image segmentation
Dec 05, 2022While deep learning methods hitherto have achieved considerable success in medical image segmentation, they are still hampered by two limitations: (i) reliance on large-scale well-labeled datasets, which are difficult to curate due to the expert-driven and time-consuming nature of pixel-level annotations in clinical practices, and (ii) failure to generalize from one domain to another, especially when the target domain is a different modality with severe domain shifts. Recent unsupervised domain adaptation~(UDA) techniques leverage abundant labeled source data together with unlabeled target data to reduce the domain gap, but these methods degrade significantly with limited source annotations. In this study, we address this underexplored UDA problem, investigating a challenging but valuable realistic scenario, where the source domain not only exhibits domain shift~w.r.t. the target domain but also suffers from label scarcity. In this regard, we propose a novel and generic framework called ``Label-Efficient Unsupervised Domain Adaptation"~(LE-UDA). In LE-UDA, we construct self-ensembling consistency for knowledge transfer between both domains, as well as a self-ensembling adversarial learning module to achieve better feature alignment for UDA. To assess the effectiveness of our method, we conduct extensive experiments on two different tasks for cross-modality segmentation between MRI and CT images. Experimental results demonstrate that the proposed LE-UDA can efficiently leverage limited source labels to improve cross-domain segmentation performance, outperforming state-of-the-art UDA approaches in the literature. Code is available at: https://github.com/jacobzhaoziyuan/LE-UDA.
Decomposing 3D Neuroimaging into 2+1D Processing for Schizophrenia Recognition
Nov 22, 2022Deep learning has been successfully applied to recognizing both natural images and medical images. However, there remains a gap in recognizing 3D neuroimaging data, especially for psychiatric diseases such as schizophrenia and depression that have no visible alteration in specific slices. In this study, we propose to process the 3D data by a 2+1D framework so that we can exploit the powerful deep 2D Convolutional Neural Network (CNN) networks pre-trained on the huge ImageNet dataset for 3D neuroimaging recognition. Specifically, 3D volumes of Magnetic Resonance Imaging (MRI) metrics (grey matter, white matter, and cerebrospinal fluid) are decomposed to 2D slices according to neighboring voxel positions and inputted to 2D CNN models pre-trained on the ImageNet to extract feature maps from three views (axial, coronal, and sagittal). Global pooling is applied to remove redundant information as the activation patterns are sparsely distributed over feature maps. Channel-wise and slice-wise convolutions are proposed to aggregate the contextual information in the third view dimension unprocessed by the 2D CNN model. Multi-metric and multi-view information are fused for final prediction. Our approach outperforms handcrafted feature-based machine learning, deep feature approach with a support vector machine (SVM) classifier and 3D CNN models trained from scratch with better cross-validation results on publicly available Northwestern University Schizophrenia Dataset and the results are replicated on another independent dataset.
Graph Neural Networks on SPD Manifolds for Motor Imagery Classification: A Perspective from the Time-Frequency Analysis
Oct 25, 2022



Motor imagery (MI) classification is one of the most widely-concern research topics in Electroencephalography (EEG)-based brain-computer interfaces (BCIs) with extensive industry value. The MI-EEG classifiers' tendency has changed fundamentally over the past twenty years, while classifiers' performance is gradually increasing. In particular, owing to the need for characterizing signals' non-Euclidean inherence, the first geometric deep learning (GDL) framework, Tensor-CSPNet, has recently emerged in the BCI study. In essence, Tensor-CSPNet is a deep learning-based classifier on the second-order statistics of EEGs. In contrast to the first-order statistics, using these second-order statistics is the classical treatment of EEG signals, and the discriminative information contained in these second-order statistics is adequate for MI-EEG classification. In this study, we present another GDL classifier for MI-EEG classification called Graph-CSPNet, using graph-based techniques to simultaneously characterize the EEG signals in both the time and frequency domains. It is realized from the perspective of the time-frequency analysis that profoundly influences signal processing and BCI studies. Contrary to Tensor-CSPNet, the architecture of Graph-CSPNet is further simplified with more flexibility to cope with variable time-frequency resolution for signal segmentation to capture the localized fluctuations. In the experiments, Graph-CSPNet is evaluated on subject-specific scenarios from two well-used MI-EEG datasets and produces near-optimal classification accuracies.
A Transformer-based deep neural network model for SSVEP classification
Oct 09, 2022
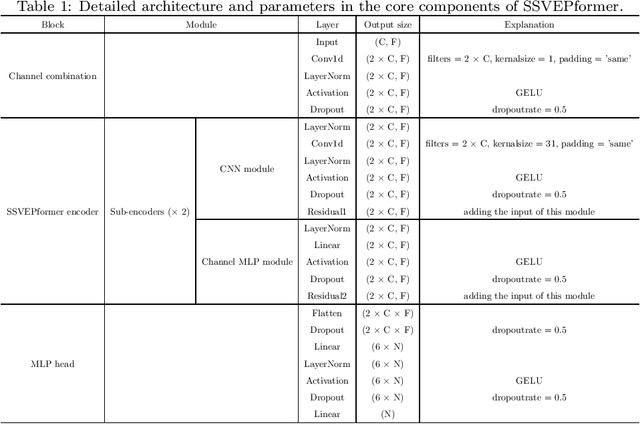
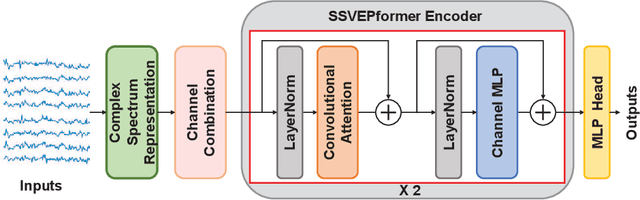
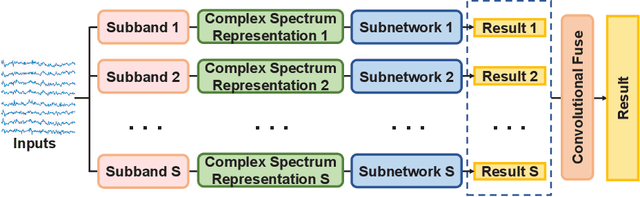
Steady-state visual evoked potential (SSVEP) is one of the most commonly used control signal in the brain-computer interface (BCI) systems. However, the conventional spatial filtering methods for SSVEP classification highly depend on the subject-specific calibration data. The need for the methods that can alleviate the demand for the calibration data become urgent. In recent years, developing the methods that can work in inter-subject classification scenario has become a promising new direction. As the popular deep learning model nowadays, Transformer has excellent performance and has been used in EEG signal classification tasks. Therefore, in this study, we propose a deep learning model for SSVEP classification based on Transformer structure in inter-subject classification scenario, termed as SSVEPformer, which is the first application of the transformer to the classification of SSVEP. Inspired by previous studies, the model adopts the frequency spectrum of SSVEP data as input, and explores the spectral and spatial domain information for classification. Furthermore, to fully utilize the harmonic information, an extended SSVEPformer based on the filter bank technology (FB-SSVEPformer) is proposed to further improve the classification performance. Experiments were conducted using two open datasets (Dataset 1: 10 subjects, 12-class task; Dataset 2: 35 subjects, 40-class task) in the inter-subject classification scenario. The experimental results show that the proposed models could achieve better results in terms of classification accuracy and information transfer rate, compared with other baseline methods. The proposed model validates the feasibility of deep learning models based on Transformer structure for SSVEP classification task, and could serve as a potential model to alleviate the calibration procedure in the practical application of SSVEP-based BCI systems.
Self-supervised Contrastive Representation Learning for Semi-supervised Time-Series Classification
Aug 13, 2022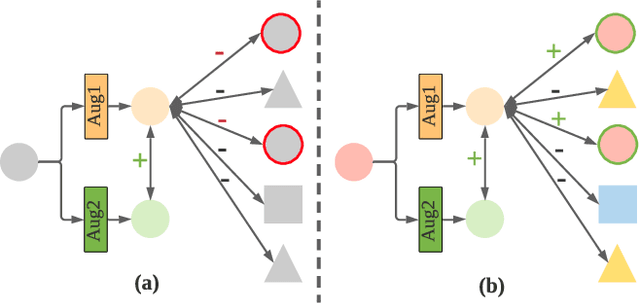
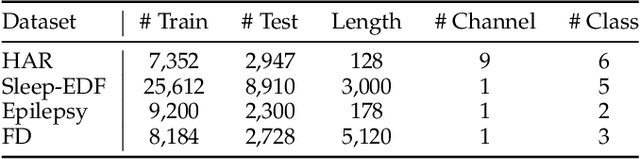
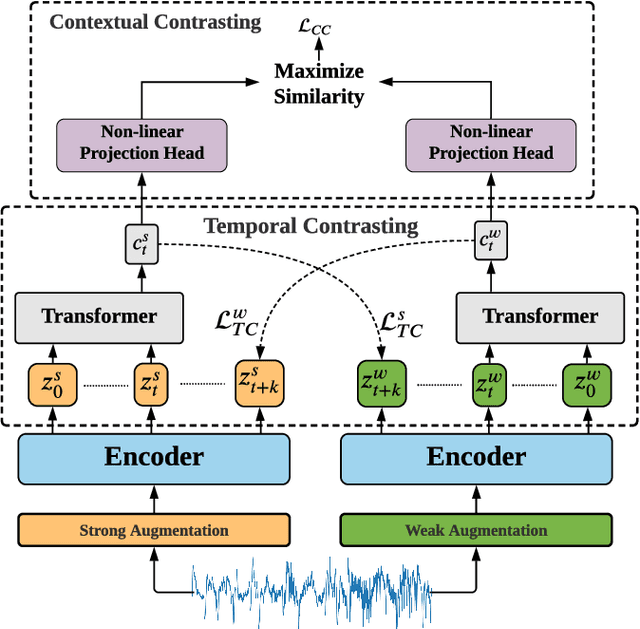
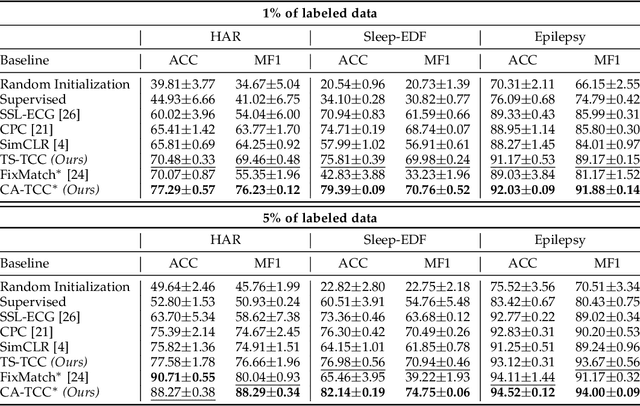
Learning time-series representations when only unlabeled data or few labeled samples are available can be a challenging task. Recently, contrastive self-supervised learning has shown great improvement in extracting useful representations from unlabeled data via contrasting different augmented views of data. In this work, we propose a novel Time-Series representation learning framework via Temporal and Contextual Contrasting (TS-TCC) that learns representations from unlabeled data with contrastive learning. Specifically, we propose time-series specific weak and strong augmentations and use their views to learn robust temporal relations in the proposed temporal contrasting module, besides learning discriminative representations by our proposed contextual contrasting module. Additionally, we conduct a systematic study of time-series data augmentation selection, which is a key part of contrastive learning. We also extend TS-TCC to the semi-supervised learning settings and propose a Class-Aware TS-TCC (CA-TCC) that benefits from the available few labeled data to further improve representations learned by TS-TCC. Specifically, we leverage robust pseudo labels produced by TS-TCC to realize class-aware contrastive loss. Extensive experiments show that the linear evaluation of the features learned by our proposed framework performs comparably with the fully supervised training. Additionally, our framework shows high efficiency in few labeled data and transfer learning scenarios. The code is publicly available at \url{https://github.com/emadeldeen24/TS-TCC}.
OCTAve: 2D en face Optical Coherence Tomography Angiography Vessel Segmentation in Weakly-Supervised Learning with Locality Augmentation
Jul 25, 2022
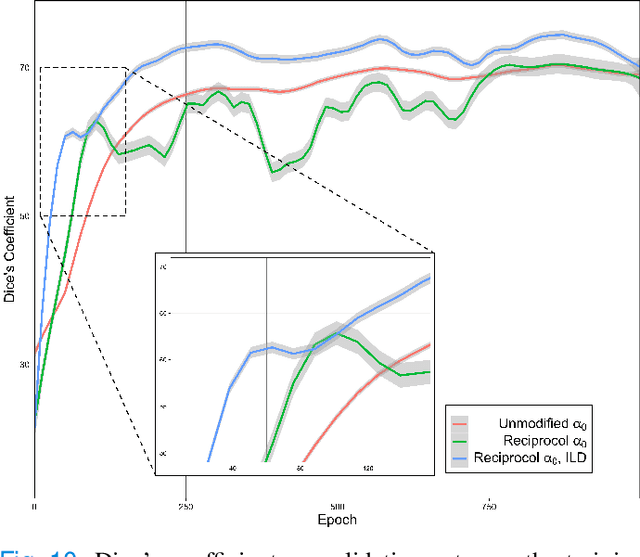

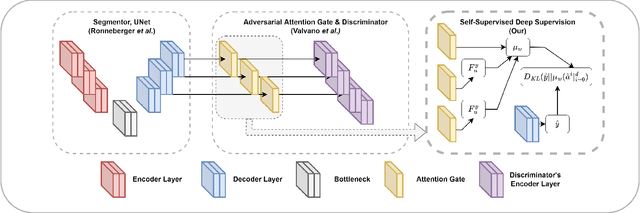
While there have been increased researches using deep learning techniques for the extraction of vascular structure from the 2D en face OCTA, for such approach, it is known that the data annotation process on the curvilinear structure like the retinal vasculature is very costly and time consuming, albeit few tried to address the annotation problem. In this work, we propose the application of the scribble-base weakly-supervised learning method to automate the pixel-level annotation. The proposed method, called OCTAve, combines the weakly-supervised learning using scribble-annotated ground truth augmented with an adversarial and a novel self-supervised deep supervision. Our novel mechanism is designed to utilize the discriminative outputs from the discrimination layer of a UNet-like architecture where the Kullback-Liebler Divergence between the aggregate discriminative outputs and the segmentation map predicate is minimized during the training. This combined method leads to the better localization of the vascular structure as shown in our experiments. We validate our proposed method on the large public datasets i.e., ROSE, OCTA-500. The segmentation performance is compared against both state-of-the-art fully-supervised and scribble-based weakly-supervised approaches. The implementation of our work used in the experiments is located at [LINK].
ACT-Net: Asymmetric Co-Teacher Network for Semi-supervised Memory-efficient Medical Image Segmentation
Jul 05, 2022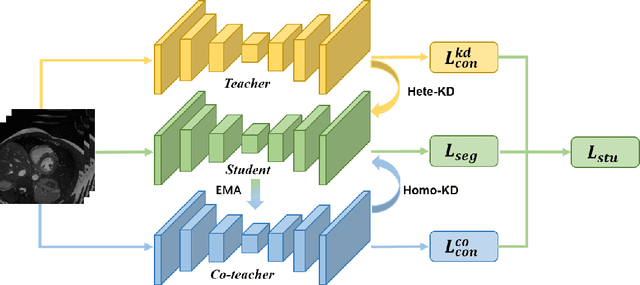
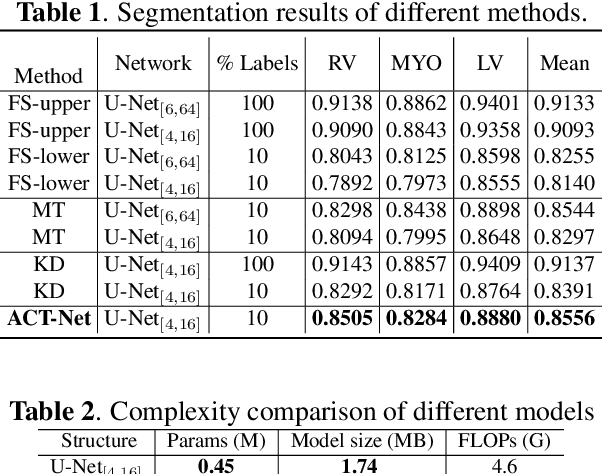
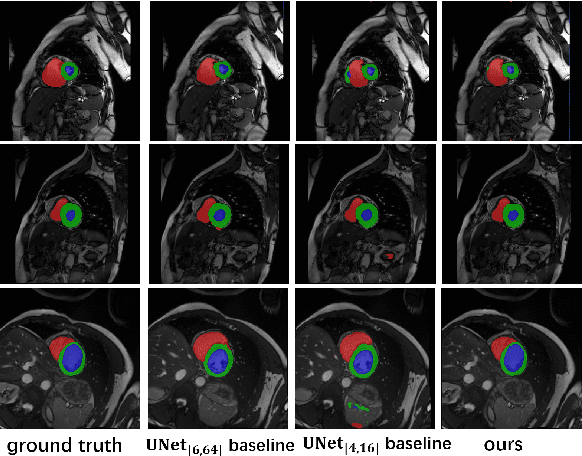
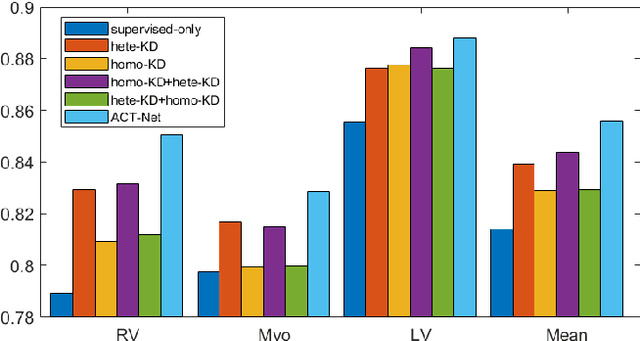
While deep models have shown promising performance in medical image segmentation, they heavily rely on a large amount of well-annotated data, which is difficult to access, especially in clinical practice. On the other hand, high-accuracy deep models usually come in large model sizes, limiting their employment in real scenarios. In this work, we propose a novel asymmetric co-teacher framework, ACT-Net, to alleviate the burden on both expensive annotations and computational costs for semi-supervised knowledge distillation. We advance teacher-student learning with a co-teacher network to facilitate asymmetric knowledge distillation from large models to small ones by alternating student and teacher roles, obtaining tiny but accurate models for clinical employment. To verify the effectiveness of our ACT-Net, we employ the ACDC dataset for cardiac substructure segmentation in our experiments. Extensive experimental results demonstrate that ACT-Net outperforms other knowledge distillation methods and achieves lossless segmentation performance with 250x fewer parameters.