 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Decision Calibration for Temporal Classification
Jun 14, 2026Temporal classification errors are often treated as representation failures, but they can also arise from how available evidence is converted into decisions. This paper proposes a representation--calibration decomposition for temporal classification. We keep a trained native classifier frozen and separate two inference-time interventions: a conservative residual multi-scale branch that adds auxiliary logits to the native prediction, and a post-hoc branch-aware calibrator that recombines native and residual evidence at decision time. This design distinguishes missing temporal evidence from underused decision-level evidence without retraining the backbone. Across FI-2010, PTB-XL, UCI-HAR, MHEALTH, and HARTH, we find that gains are strongly regime-dependent. Residual multi-scale evidence is most useful in noisy or representation-limited settings, especially short-horizon FI-2010 and weaker recurrent backbones, while branch-aware calibration helps when native and auxiliary logits contain complementary evidence not fully exploited by the raw decision rule. Near-saturated settings show limited gains from either intervention. These results suggest that temporal classification should be understood not only as representation learning, but also as the problem of trusting, combining, and calibrating evidence from multiple views.
Ensemble pruning via an integer programming approach with diversity constraints
May 02, 2022
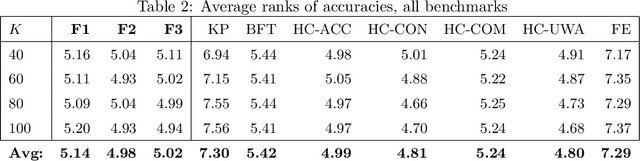
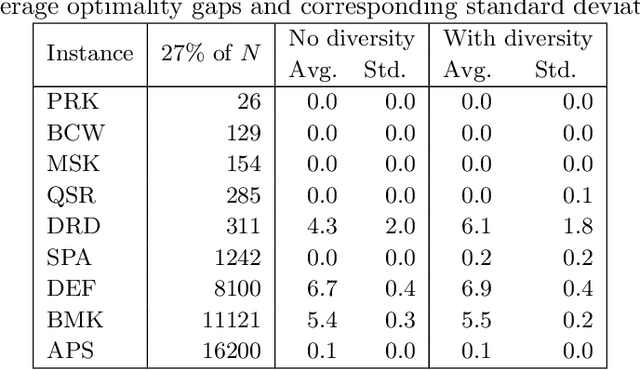
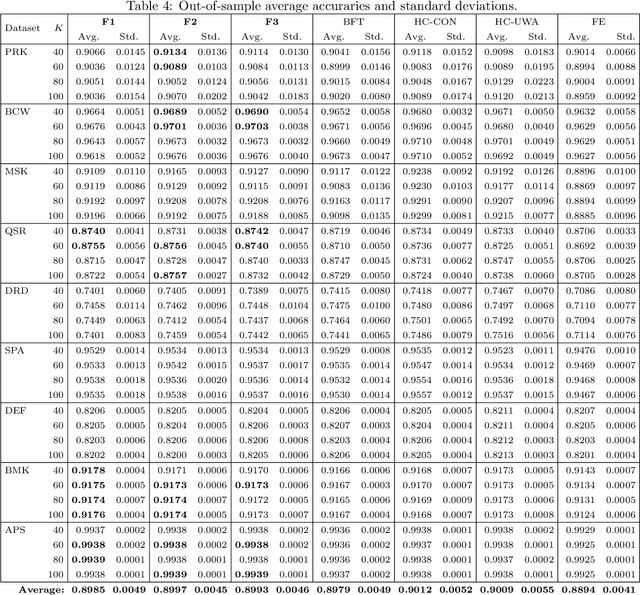
Ensemble learning combines multiple classifiers in the hope of obtaining better predictive performance. Empirical studies have shown that ensemble pruning, that is, choosing an appropriate subset of the available classifiers, can lead to comparable or better predictions than using all classifiers. In this paper, we consider a binary classification problem and propose an integer programming (IP) approach for selecting optimal classifier subsets. We propose a flexible objective function to adapt to desired criteria of different datasets. We also propose constraints to ensure minimum diversity levels in the ensemble. Despite the general case of IP being NP-Hard, state-of-the-art solvers are able to quickly obtain good solutions for datasets with up to 60000 data points. Our approach yields competitive results when compared to some of the best and most used pruning methods in literature.