 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Specific Independence in Bayesian Networks
Feb 13, 2013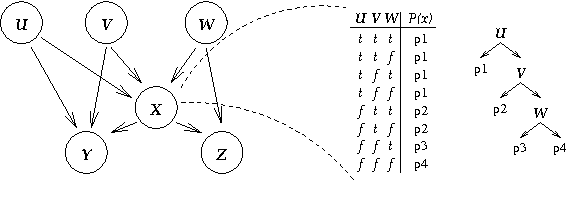
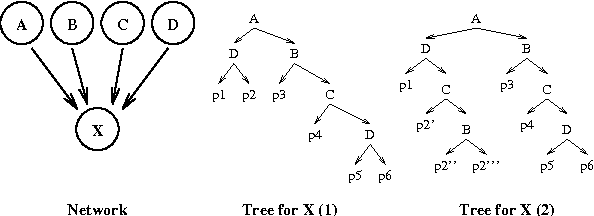
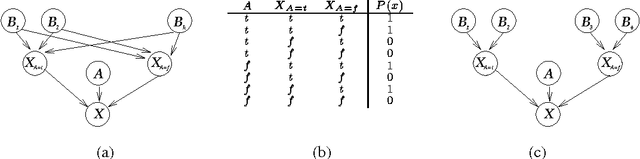
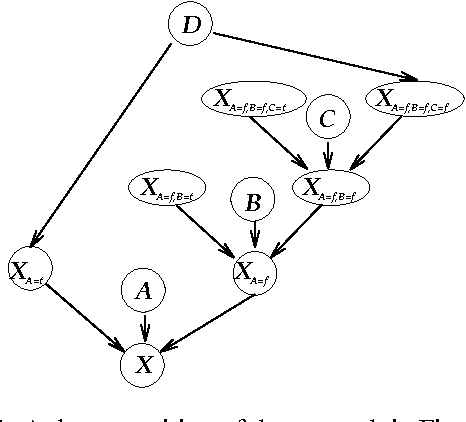
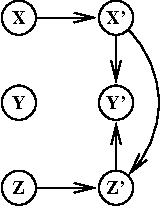
Bayesian networks provide a language for qualitatively representing the conditional independence properties of a distribution. This allows a natural and compact representation of the distribution, eases knowledge acquisition, and supports effective inference algorithms. It is well-known, however, that there are certain independencies that we cannot capture qualitatively within the Bayesian network structure: independencies that hold only in certain contexts, i.e., given a specific assignment of values to certain variables. In this paper, we propose a formal notion of context-specific independence (CSI), based on regularities in the conditional probability tables (CPTs) at a node. We present a technique, analogous to (and based on) d-separation, for determining when such independence holds in a given network. We then focus on a particular qualitative representation scheme - tree-structured CPTs - for capturing CSI. We suggest ways in which this representation can be used to support effective inference algorithms. In particular, we present a structural decomposition of the resulting network which can improve the performance of clustering algorithms, and an alternative algorithm based on cutset conditioning.
Structured Arc Reversal and Simulation of Dynamic Probabilistic Networks
Feb 06, 2013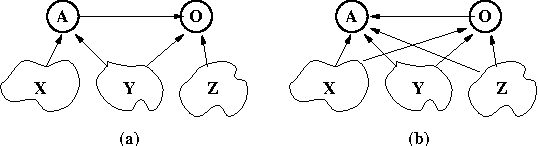
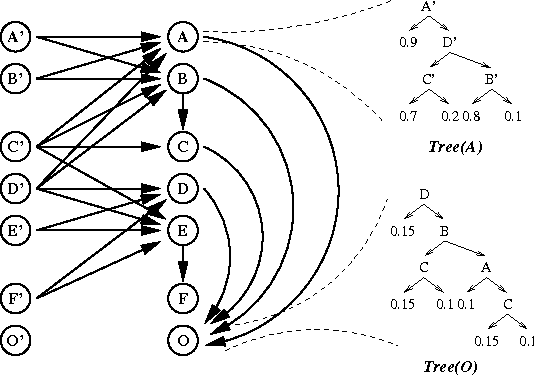
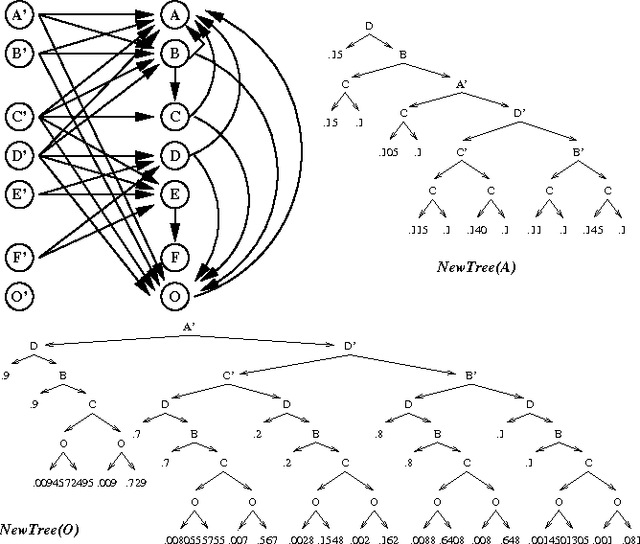
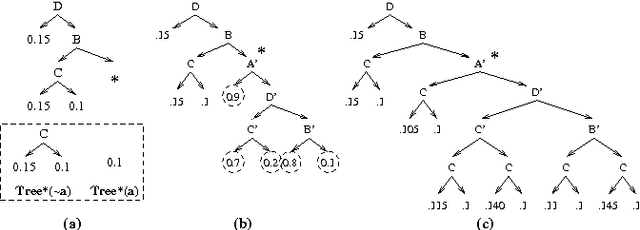
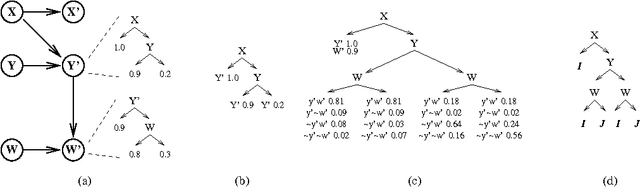
We present an algorithm for arc reversal in Bayesian networks with tree-structured conditional probability tables, and consider some of its advantages, especially for the simulation of dynamic probabilistic networks. In particular, the method allows one to produce CPTs for nodes involved in the reversal that exploit regularities in the conditional distributions. We argue that this approach alleviates some of the overhead associated with arc reversal, plays an important role in evidence integration and can be used to restrict sampling of variables in DPNs. We also provide an algorithm that detects the dynamic irrelevance of state variables in forward simulation. This algorithm exploits the structured CPTs in a reversed network to determine, in a time-independent fashion, the conditions under which a variable does or does not need to be sampled.
Correlated Action Effects in Decision Theoretic Regression
Feb 06, 2013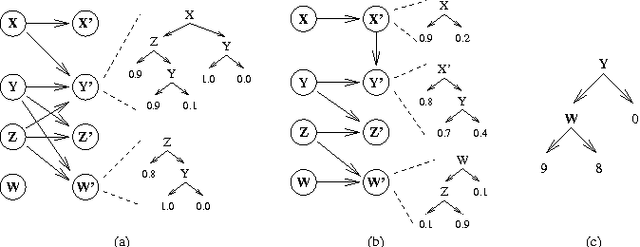

Much recent research in decision theoretic planning has adopted Markov decision processes (MDPs) as the model of choice, and has attempted to make their solution more tractable by exploiting problem structure. One particular algorithm, structured policy construction achieves this by means of a decision theoretic analog of goal regression using action descriptions based on Bayesian networks with tree-structured conditional probability tables. The algorithm as presented is not able to deal with actions with correlated effects. We describe a new decision theoretic regression operator that corrects this weakness. While conceptually straightforward, this extension requires a somewhat more complicated technical approach.
Hierarchical Solution of Markov Decision Processes using Macro-actions
Jan 30, 2013

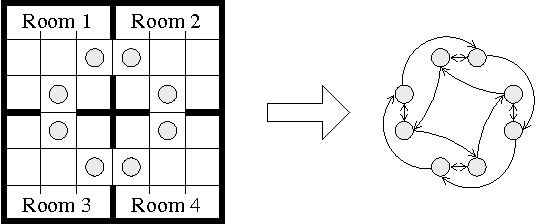
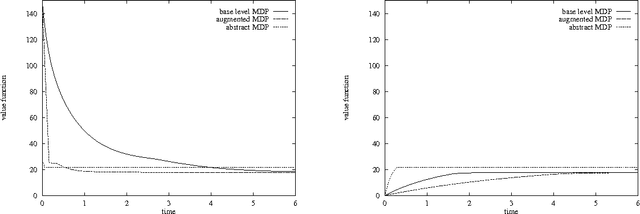
We investigate the use of temporally abstract actions, or macro-actions, in the solution of Markov decision processes. Unlike current models that combine both primitive actions and macro-actions and leave the state space unchanged, we propose a hierarchical model (using an abstract MDP) that works with macro-actions only, and that significantly reduces the size of the state space. This is achieved by treating macroactions as local policies that act in certain regions of state space, and by restricting states in the abstract MDP to those at the boundaries of regions. The abstract MDP approximates the original and can be solved more efficiently. We discuss several ways in which macro-actions can be generated to ensure good solution quality. Finally, we consider ways in which macro-actions can be reused to solve multiple, related MDPs; and we show that this can justify the computational overhead of macro-action generation.
SPUDD: Stochastic Planning using Decision Diagrams
Jan 23, 2013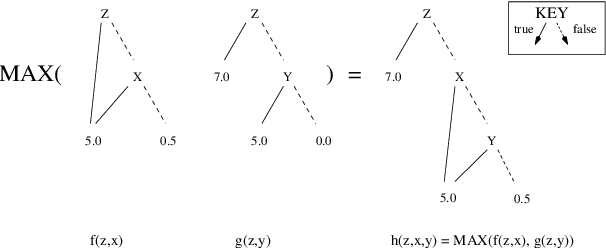
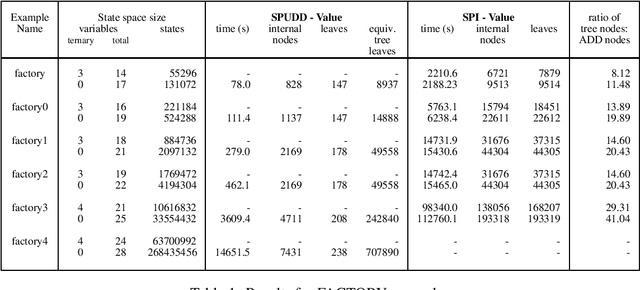
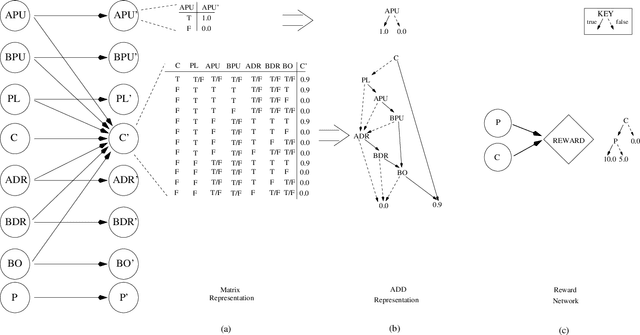

Markov decisions processes (MDPs) are becoming increasing popular as models of decision theoretic planning. While traditional dynamic programming methods perform well for problems with small state spaces, structured methods are needed for large problems. We propose and examine a value iteration algorithm for MDPs that uses algebraic decision diagrams(ADDs) to represent value functions and policies. An MDP is represented using Bayesian networks and ADDs and dynamic programming is applied directly to these ADDs. We demonstrate our method on large MDPs (up to 63 million states) and show that significant gains can be had when compared to tree-structured representations (with up to a thirty-fold reduction in the number of nodes required to represent optimal value functions).
Continuous Value Function Approximation for Sequential Bidding Policies
Jan 23, 2013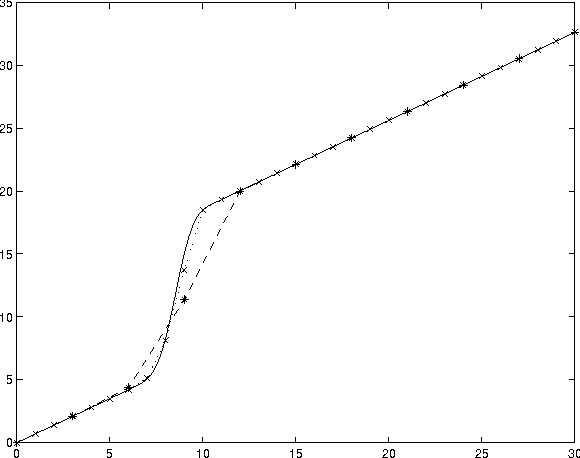

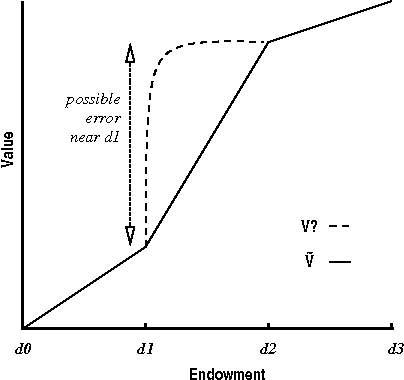
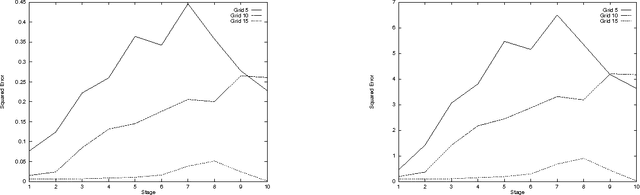
Market-based mechanisms such as auctions are being studied as an appropriate means for resource allocation in distributed and mulitagent decision problems. When agents value resources in combination rather than in isolation, they must often deliberate about appropriate bidding strategies for a sequence of auctions offering resources of interest. We briefly describe a discrete dynamic programming model for constructing appropriate bidding policies for resources exhibiting both complementarities and substitutability. We then introduce a continuous approximation of this model, assuming that money (or the numeraire good) is infinitely divisible. Though this has the potential to reduce the computational cost of computing policies, value functions in the transformed problem do not have a convenient closed form representation. We develop {em grid-based} approximation for such value functions, representing value functions using piecewise linear approximations. We show that these methods can offer significant computational savings with relatively small cost in solution quality.
Reasoning With Conditional Ceteris Paribus Preference Statem
Jan 23, 2013
In many domains it is desirable to assess the preferences of users in a qualitative rather than quantitative way. Such representations of qualitative preference orderings form an importnat component of automated decision tools. We propose a graphical representation of preferences that reflects conditional dependence and independence of preference statements under a ceteris paribus (all else being equal) interpretation. Such a representation is ofetn compact and arguably natural. We describe several search algorithms for dominance testing based on this representation; these algorithms are quite effective, especially in specific network topologies, such as chain-and tree- structured networks, as well as polytrees.
Value-Directed Belief State Approximation for POMDPs
Jan 16, 2013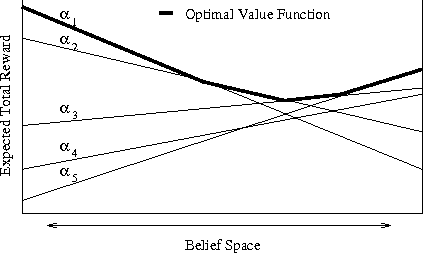
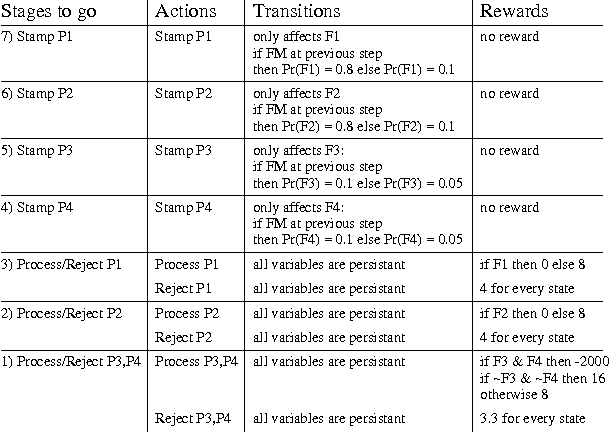
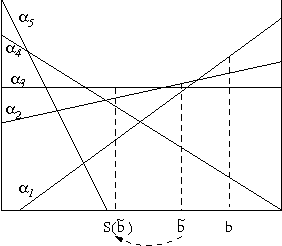
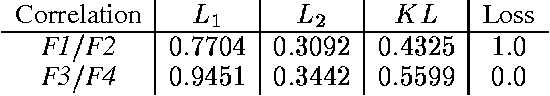
We consider the problem belief-state monitoring for the purposes of implementing a policy for a partially-observable Markov decision process (POMDP), specifically how one might approximate the belief state. Other schemes for belief-state approximation (e.g., based on minimixing a measures such as KL-diveregence between the true and estimated state) are not necessarily appropriate for POMDPs. Instead we propose a framework for analyzing value-directed approximation schemes, where approximation quality is determined by the expected error in utility rather than by the error in the belief state itself. We propose heuristic methods for finding good projection schemes for belief state estimation - exhibiting anytime characteristics - given a POMDP value fucntion. We also describe several algorithms for constructing bounds on the error in decision quality (expected utility) associated with acting in accordance with a given belief state approximation.
Approximately Optimal Monitoring of Plan Preconditions
Jan 16, 2013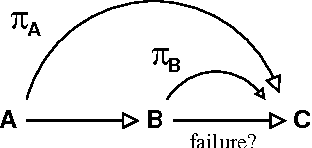
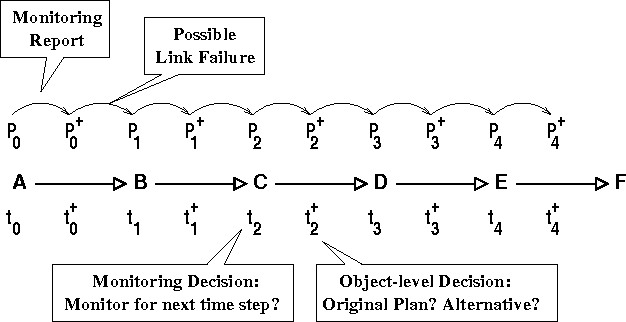
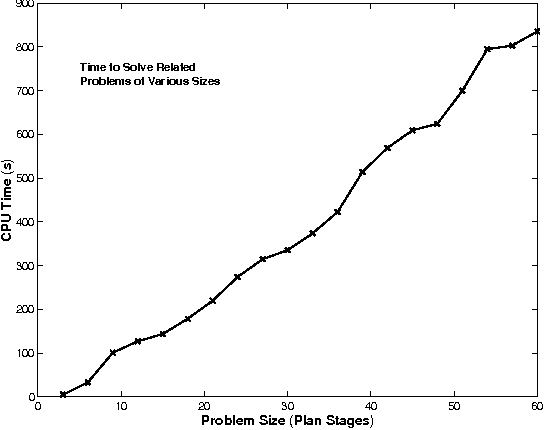
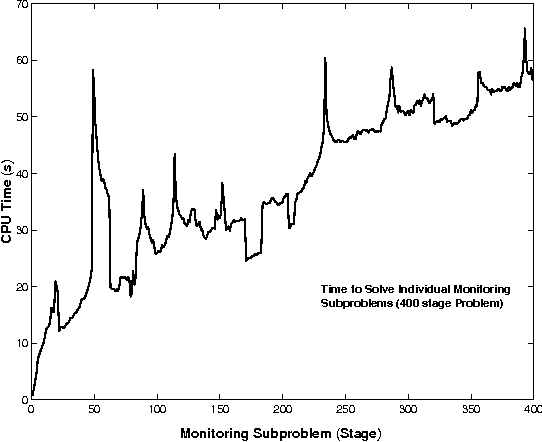
Monitoring plan preconditions can allow for replanning when a precondition fails, generally far in advance of the point in the plan where the precondition is relevant. However, monitoring is generally costly, and some precondition failures have a very small impact on plan quality. We formulate a model for optimal precondition monitoring, using partially-observable Markov decisions processes, and describe methods for solving this model efficitively, though approximately. Specifically, we show that the single-precondition monitoring problem is generally tractable, and the multiple-precondition monitoring policies can be efficitively approximated using single-precondition soultions.
Value-Directed Sampling Methods for POMDPs
Jan 10, 2013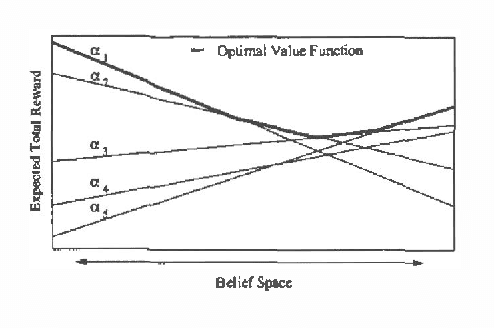
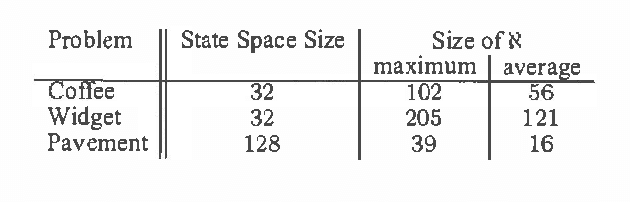
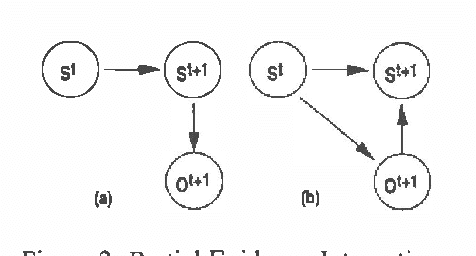
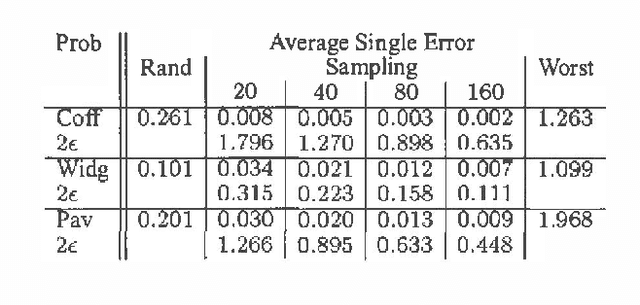
We consider the problem of approximate belief-state monitoring using particle filtering for the purposes of implementing a policy for a partially-observable Markov decision process (POMDP). While particle filtering has become a widely-used tool in AI for monitoring dynamical systems, rather scant attention has been paid to their use in the context of decision making. Assuming the existence of a value function, we derive error bounds on decision quality associated with filtering using importance sampling. We also describe an adaptive procedure that can be used to dynamically determine the number of samples required to meet specific error bounds. Empirical evidence is offered supporting this technique as a profitable means of directing sampling effort where it is needed to distinguish policies.