 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein-Aligned Localisation for VLM-Based Distributional OOD Detection in Medical Imaging
May 06, 2026Zero-shot anomaly localisation via vision-language models (VLMs) offers a compelling approach for rare pathology detection, yet its performance is fundamentally limited by the absence of healthy anatomical context. We reformulate zero-shot localisation as a comparative inference problem in which anomalies are identified through structured comparison against reference distributions of normal anatomy. We introduce WALDO, a training-free framework grounded in optimal transport theory that enables comparative reasoning through: (i) entropy-weighted Sliced Wasserstein distances for anatomically-aware reference selection from DINOv2 patch distributions, (ii) Goldilocks zone sampling exploiting the non-monotonic relationship between reference similarity and localisation accuracy, and (iii) self-consistency aggregation via weighted non-maximum suppression. We theoretically analyse the Goldilocks effect through distributional divergence, and show that references with moderate similarity minimize a bias-variance trade-off in comparative visual reasoning. On the NOVA brain MRI benchmark, WALDO with Qwen2.5-VL-72B achieves $43.5_{\pm1.6}\%$ mAP@30 (95\% CI: [40.4, 46.7]), representing a 19\% relative improvement over zero-shot baselines. Cross-model evaluation shows consistent gains: GPT-4o achieves $32.0_{\pm6.5}\%$ and Qwen3-VL-32B achieves $32.0_{\pm6.6}\%$ mAP@30. Paired McNemar tests confirm statistical significance ($p<0.01$). Source code is available at https://github.com/bkainz/WALDO_MICCAI26_demo .
LocBAM: Advancing 3D Patch-Based Image Segmentation by Integrating Location Contex
Jan 21, 2026Patch-based methods are widely used in 3D medical image segmentation to address memory constraints in processing high-resolution volumetric data. However, these approaches often neglect the patch's location within the global volume, which can limit segmentation performance when anatomical context is important. In this paper, we investigate the role of location context in patch-based 3D segmentation and propose a novel attention mechanism, LocBAM, that explicitly processes spatial information. Experiments on BTCV, AMOS22, and KiTS23 demonstrate that incorporating location context stabilizes training and improves segmentation performance, particularly under low patch-to-volume coverage where global context is missing. Furthermore, LocBAM consistently outperforms classical coordinate encoding via CoordConv. Code is publicly available at https://github.com/compai-lab/2026-ISBI-hooft
Attribute Regularized Soft Introspective VAE: Towards Cardiac Attribute Regularization Through MRI Domains
Jul 24, 2023



Deep generative models have emerged as influential instruments for data generation and manipulation. Enhancing the controllability of these models by selectively modifying data attributes has been a recent focus. Variational Autoencoders (VAEs) have shown promise in capturing hidden attributes but often produce blurry reconstructions. Controlling these attributes through different imaging domains is difficult in medical imaging. Recently, Soft Introspective VAE leverage the benefits of both VAEs and Generative Adversarial Networks (GANs), which have demonstrated impressive image synthesis capabilities, by incorporating an adversarial loss into VAE training. In this work, we propose the Attributed Soft Introspective VAE (Attri-SIVAE) by incorporating an attribute regularized loss, into the Soft-Intro VAE framework. We evaluate experimentally the proposed method on cardiac MRI data from different domains, such as various scanner vendors and acquisition centers. The proposed method achieves similar performance in terms of reconstruction and regularization compared to the state-of-the-art Attributed regularized VAE but additionally also succeeds in keeping the same regularization level when tested on a different dataset, unlike the compared method.
Confidence-aware Levenberg-Marquardt optimization for joint motion estimation and super-resolution
Sep 06, 2016
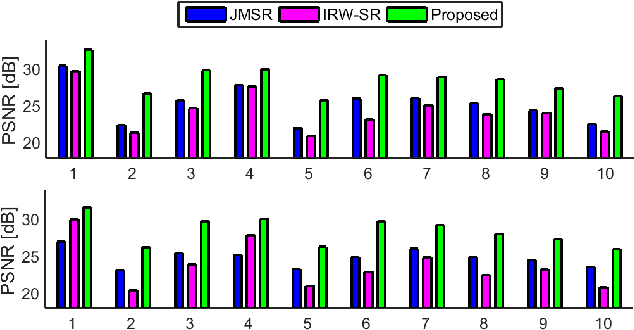

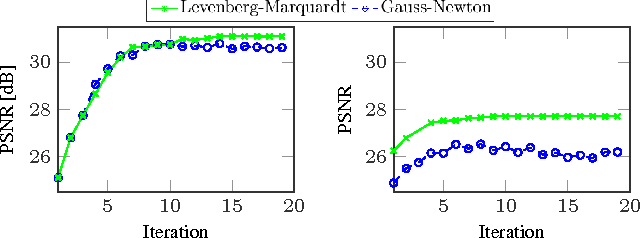
Motion estimation across low-resolution frames and the reconstruction of high-resolution images are two coupled subproblems of multi-frame super-resolution. This paper introduces a new joint optimization approach for motion estimation and image reconstruction to address this interdependence. Our method is formulated via non-linear least squares optimization and combines two principles of robust super-resolution. First, to enhance the robustness of the joint estimation, we propose a confidence-aware energy minimization framework augmented with sparse regularization. Second, we develop a tailor-made Levenberg-Marquardt iteration scheme to jointly estimate motion parameters and the high-resolution image along with the corresponding model confidence parameters. Our experiments on simulated and real images confirm that the proposed approach outperforms decoupled motion estimation and image reconstruction as well as related state-of-the-art joint estimation algorithms.
* accepted for ICIP 2016