 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised PCA: A Multiobjective Approach
Nov 10, 2020
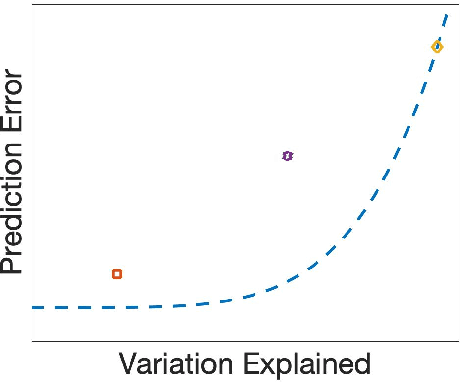
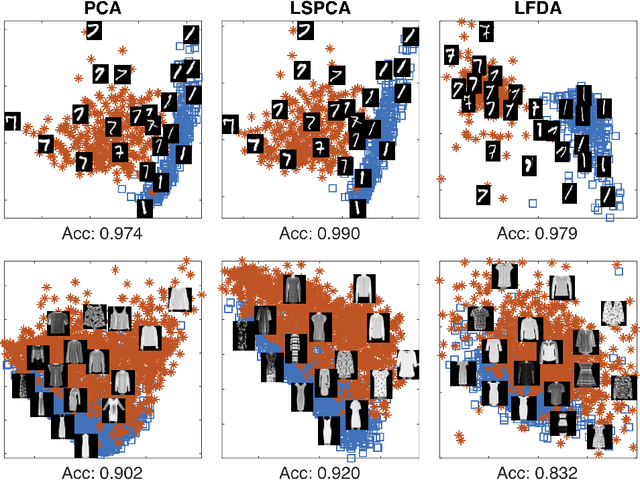
Methods for supervised principal component analysis (SPCA) aim to incorporate label information into principal component analysis (PCA), so that the extracted features are more useful for a prediction task of interest. Prior work on SPCA has focused primarily on optimizing prediction error, and has neglected the value of maximizing variance explained by the extracted features. We propose a new method for SPCA that addresses both of these objectives jointly, and demonstrate empirically that our approach dominates existing approaches, i.e., outperforms them with respect to both prediction error and variation explained. Our approach accommodates arbitrary supervised learning losses and, through a statistical reformulation, provides a novel low-rank extension of generalized linear models.
Consistent Estimation of Identifiable Nonparametric Mixture Models from Grouped Observations
Jun 12, 2020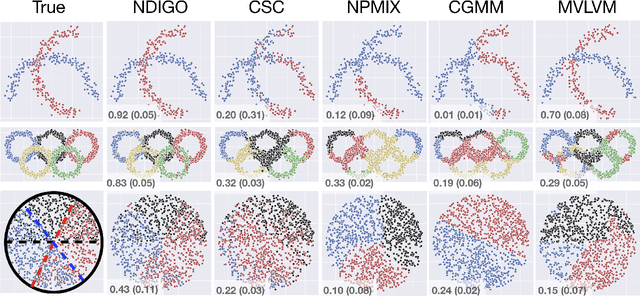


Recent research has established sufficient conditions for finite mixture models to be identifiable from grouped observations. These conditions allow the mixture components to be nonparametric and have substantial (or even total) overlap. This work proposes an algorithm that consistently estimates any identifiable mixture model from grouped observations. Our analysis leverages an oracle inequality for weighted kernel density estimators of the distribution on groups, together with a general result showing that consistent estimation of the distribution on groups implies consistent estimation of mixture components. A practical implementation is provided for paired observations, and the approach is shown to outperform existing methods, especially when mixture components overlap significantly.
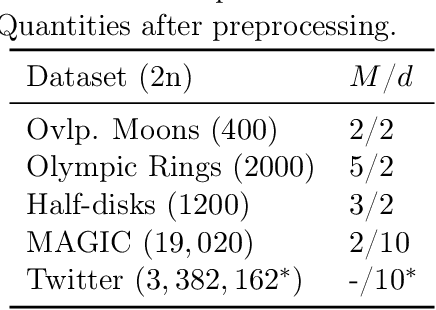
Learning from Label Proportions: A Mutual Contamination Framework
Jun 12, 2020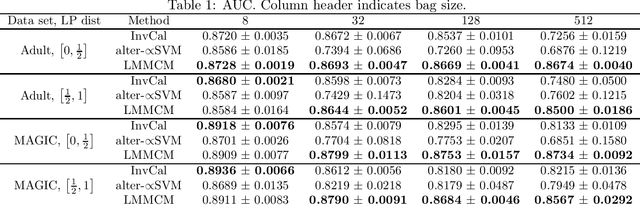
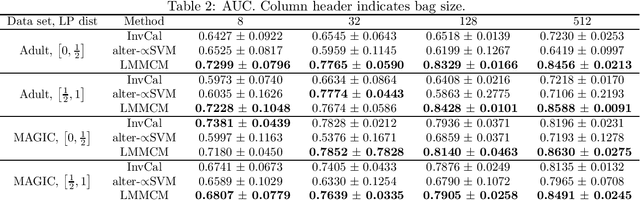
Learning from label proportions (LLP) is a weakly supervised setting for classification in which unlabeled training instances are grouped into bags, and each bag is annotated with the proportion of each class occurring in that bag. Prior work on LLP has yet to establish a consistent learning procedure, nor does there exist a theoretically justified, general purpose training criterion. In this work we address these two issues by posing LLP in terms of mutual contamination models (MCMs), which have recently been applied successfully to study various other weak supervision settings. In the process, we establish several novel technical results for MCMs, including unbiased losses and generalization error bounds under non-iid sampling plans. We also point out the limitations of a common experimental setting for LLP, and propose a new one based on our MCM framework.
Calibrated Surrogate Losses for Adversarially Robust Classification
May 28, 2020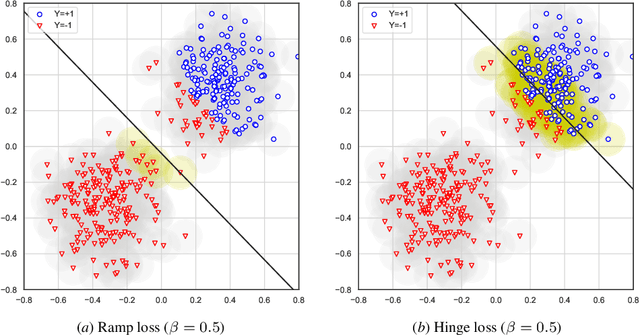
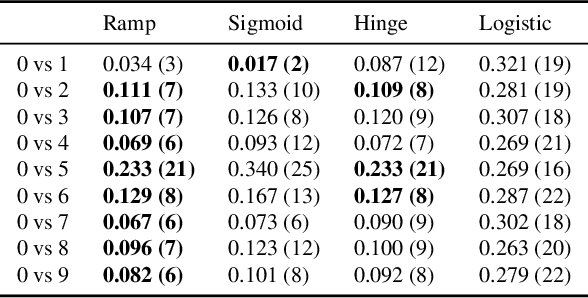
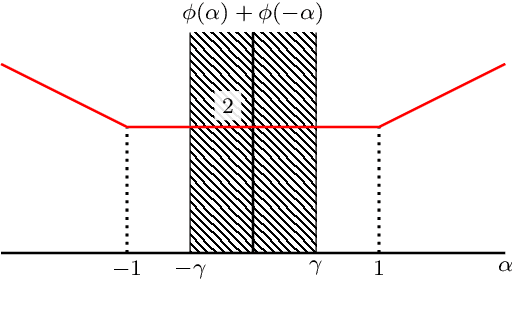
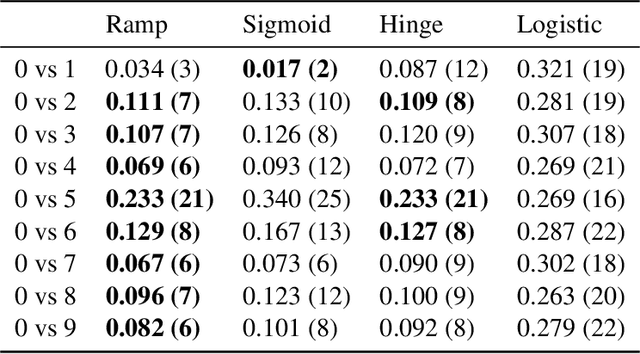
Adversarially robust classification seeks a classifier that is insensitive to adversarial perturbations of test patterns. This problem is often formulated via a minimax objective, where the target loss is the worst-case value of the 0-1 loss subject to a bound on the size of perturbation. Recent work has proposed convex surrogates for the adversarial 0-1 loss, in an effort to make optimization more tractable. In this work, we consider the question of which surrogate losses are calibrated with respect to the adversarial 0-1 loss, meaning that minimization of the former implies minimization of the latter. We show that no convex surrogate loss is calibrated with respect to the adversarial 0-1 loss when restricted to the class of linear models. We further introduce a class of nonconvex losses and offer necessary and sufficient conditions for losses in this class to be calibrated.
PAC Reinforcement Learning without Real-World Feedback
Oct 25, 2019This work studies reinforcement learning in the Sim-to-Real setting, in which an agent is first trained on a number of simulators before being deployed in the real world, with the aim of decreasing the real-world sample complexity requirement. Using a dynamic model known as a rich observation Markov decision process (ROMDP), we formulate a theoretical framework for Sim-to-Real in the situation where feedback in the real world is not available. We establish real-world sample complexity guarantees that are smaller than what is currently known for directly (i.e., without access to simulators) learning a ROMDP with feedback.
Learning from Multiple Corrupted Sources, with Application to Learning from Label Proportions
Oct 10, 2019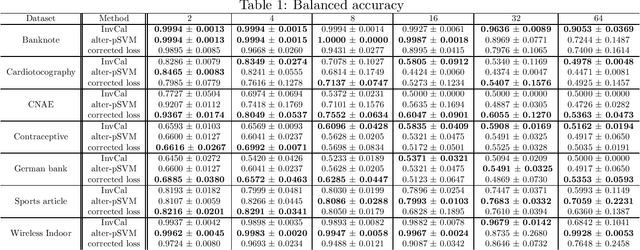
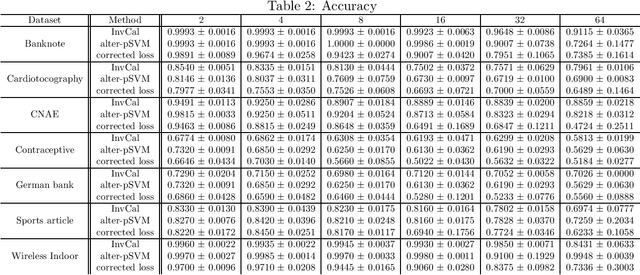
We study binary classification in the setting where the learner is presented with multiple corrupted training samples, with possibly different sample sizes and degrees of corruption, and introduce an approach based on minimizing a weighted combination of corruption-corrected empirical risks. We establish a generalization error bound, and further show that the bound is optimized when the weights are certain interpretable and intuitive functions of the sample sizes and degrees of corruptions. We then apply this setting to the problem of learning with label proportions (LLP), and propose an algorithm that enjoys the most general statistical performance guarantees known for LLP. Experiments demonstrate the utility of our theory.
A Generalization Error Bound for Multi-class Domain Generalization
May 24, 2019
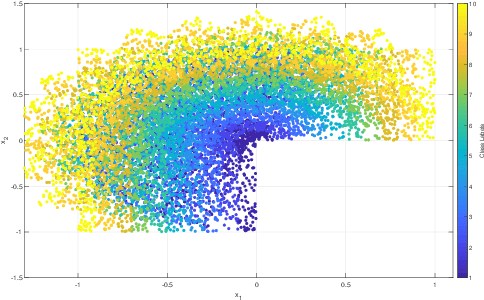
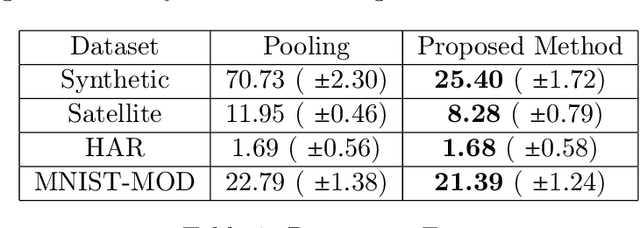

Domain generalization is the problem of assigning labels to an unlabeled data set, given several similar data sets for which labels have been provided. Despite considerable interest in this problem over the last decade, there has been no theoretical analysis in the setting of multi-class classification. In this work, we study a kernel-based learning algorithm and establish a generalization error bound that scales logarithmically in the number of classes, matching state-of-the-art bounds for multi-class classification in the conventional learning setting. We also demonstrate empirically that the proposed algorithm achieves significant performance gains compared to a pooling strategy.
Simple Regret Minimization for Contextual Bandits
Oct 17, 2018

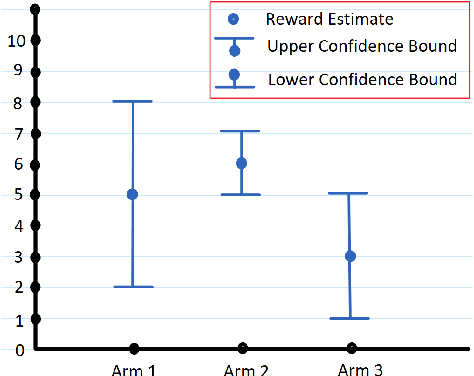
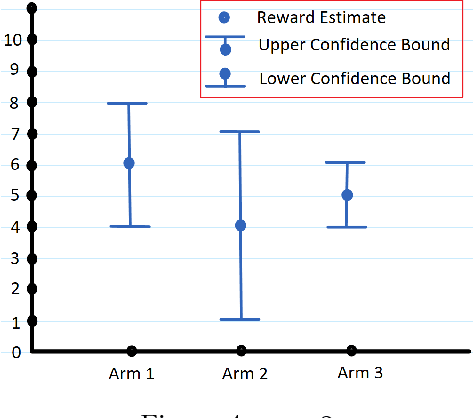
There are two variants of the classical multi-armed bandit (MAB) problem that have received considerable attention from machine learning researchers in recent years: contextual bandits and simple regret minimization. Contextual bandits are a sub-class of MABs where, at every time step, the learner has access to side information that is predictive of the best arm. Simple regret minimization assumes that the learner only incurs regret after a pure exploration phase. In this work, we study simple regret minimization for contextual bandits. Motivated by applications where the learner has separate training and autonomous modes, we assume that, the learner experiences a pure exploration phase, where feedback is received after every action but no regret is incurred, followed by a pure exploitation phase in which regret is incurred but there is no feedback. We present the Contextual-Gap algorithm and establish performance guarantees on the simple regret, i.e., the regret during the pure exploitation phase. Our experiments examine a novel application to adaptive sensor selection for magnetic field estimation in interplanetary spacecraft, and demonstrate considerable improvement over algorithms designed to minimize the cumulative regret.
A Generalized Neyman-Pearson Criterion for Optimal Domain Adaptation
Oct 03, 2018In the problem domain adaptation for binary classification, the learner is presented with labeled examples from a source domain, and must correctly classify unlabeled examples from a target domain, which may differ from the source. Previous work on this problem has assumed that the performance measure of interest is the expected value of some loss function. We introduce a new Neyman-Pearson-like criterion and argue that, for this optimality criterion, stronger domain adaptation results are possible than what has previously been established. In particular, we study a class of domain adaptation problems that generalizes both the covariate shift assumption and a model for feature-dependent label noise, and establish optimal classification on the target domain despite not having access to labelled data from this domain.
Nonparametric Preference Completion
Apr 10, 2018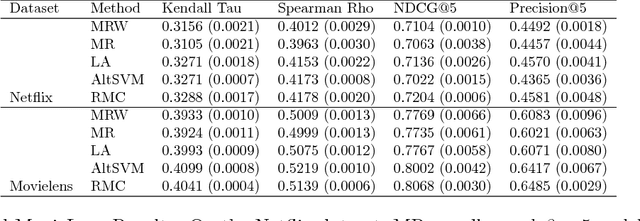
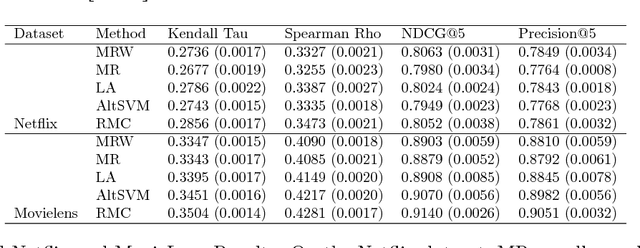

We consider the task of collaborative preference completion: given a pool of items, a pool of users and a partially observed item-user rating matrix, the goal is to recover the \emph{personalized ranking} of each user over all of the items. Our approach is nonparametric: we assume that each item $i$ and each user $u$ have unobserved features $x_i$ and $y_u$, and that the associated rating is given by $g_u(f(x_i,y_u))$ where $f$ is Lipschitz and $g_u$ is a monotonic transformation that depends on the user. We propose a $k$-nearest neighbors-like algorithm and prove that it is consistent. To the best of our knowledge, this is the first consistency result for the collaborative preference completion problem in a nonparametric setting. Finally, we demonstrate the performance of our algorithm with experiments on the Netflix and Movielens datasets.