 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning for the Imputation of Public Opinion Data with Large Language Models
Jun 08, 2026Large language models have been widely evaluated as simulators of individual survey responses. In practice, however, fully unobserved responses are rare; the dominant problem is partial non-response. Imputation aims to restore the overall structure of a survey dataset by filling in these missing values. It has its own well-defined evaluation criteria and differs fundamentally from prediction. We propose to impute missing survey data through in-context learning (ICL). We systematically evaluate ICL design choices across different missingness mechanisms (MCAR, MAR, MNAR) on 150 opinion variables spanning 15 waves of the American Trends Panel. Compared to well-established statistical methods for data imputation like MICE PMM, our ICL approach consistently reduces absolute error across all missingness mechanisms, with the largest gains under non-random missingness (MNAR). Notably, the best-performing specification (gpt-oss-120b with 100 in-context examples) achieves near-nominal aggregate coverage (approaching the 95% level) with confidence intervals two to five times narrower than MICE PMM. We publish a Python package with an sklearn-like API to enable easy deployment of our method using local and proprietary LLMs.
QSTN: A Modular Framework for Robust Questionnaire Inference with Large Language Models
Dec 09, 2025We introduce QSTN, an open-source Python framework for systematically generating responses from questionnaire-style prompts to support in-silico surveys and annotation tasks with large language models (LLMs). QSTN enables robust evaluation of questionnaire presentation, prompt perturbations, and response generation methods. Our extensive evaluation ($>40 $ million survey responses) shows that question structure and response generation methods have a significant impact on the alignment of generated survey responses with human answers, and can be obtained for a fraction of the compute cost. In addition, we offer a no-code user interface that allows researchers to set up robust experiments with LLMs without coding knowledge. We hope that QSTN will support the reproducibility and reliability of LLM-based research in the future.
Prompt Perturbations Reveal Human-Like Biases in LLM Survey Responses
Jul 09, 2025Large Language Models (LLMs) are increasingly used as proxies for human subjects in social science surveys, but their reliability and susceptibility to known response biases are poorly understood. This paper investigates the response robustness of LLMs in normative survey contexts -- we test nine diverse LLMs on questions from the World Values Survey (WVS), applying a comprehensive set of 11 perturbations to both question phrasing and answer option structure, resulting in over 167,000 simulated interviews. In doing so, we not only reveal LLMs' vulnerabilities to perturbations but also reveal that all tested models exhibit a consistent \textit{recency bias} varying in intensity, disproportionately favoring the last-presented answer option. While larger models are generally more robust, all models remain sensitive to semantic variations like paraphrasing and to combined perturbations. By applying a set of perturbations, we reveal that LLMs partially align with survey response biases identified in humans. This underscores the critical importance of prompt design and robustness testing when using LLMs to generate synthetic survey data.
Extracting Affect Aggregates from Longitudinal Social Media Data with Temporal Adapters for Large Language Models
Sep 26, 2024This paper proposes temporally aligned Large Language Models (LLMs) as a tool for longitudinal analysis of social media data. We fine-tune Temporal Adapters for Llama 3 8B on full timelines from a panel of British Twitter users, and extract longitudinal aggregates of emotions and attitudes with established questionnaires. We validate our estimates against representative British survey data and find strong positive, significant correlations for several collective emotions. The obtained estimates are robust across multiple training seeds and prompt formulations, and in line with collective emotions extracted using a traditional classification model trained on labeled data. To the best of our knowledge, this is the first work to extend the analysis of affect in LLMs to a longitudinal setting through Temporal Adapters. Our work enables new approaches towards the longitudinal analysis of social media data.
The FairCeptron: A Framework for Measuring Human Perceptions of Algorithmic Fairness
Feb 08, 2021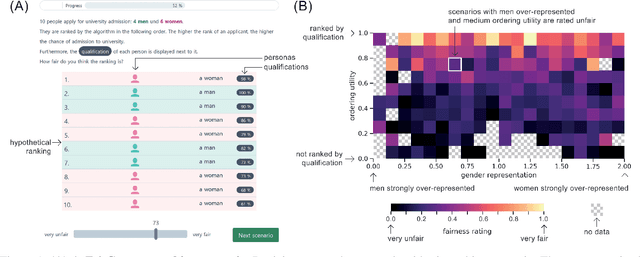
Measures of algorithmic fairness often do not account for human perceptions of fairness that can substantially vary between different sociodemographics and stakeholders. The FairCeptron framework is an approach for studying perceptions of fairness in algorithmic decision making such as in ranking or classification. It supports (i) studying human perceptions of fairness and (ii) comparing these human perceptions with measures of algorithmic fairness. The framework includes fairness scenario generation, fairness perception elicitation and fairness perception analysis. We demonstrate the FairCeptron framework by applying it to a hypothetical university admission context where we collect human perceptions of fairness in the presence of minorities. An implementation of the FairCeptron framework is openly available, and it can easily be adapted to study perceptions of algorithmic fairness in other application contexts. We hope our work paves the way towards elevating the role of studies of human fairness perceptions in the process of designing algorithmic decision making systems.