 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
Indoor Semantic Segmentation using depth information
Mar 14, 2013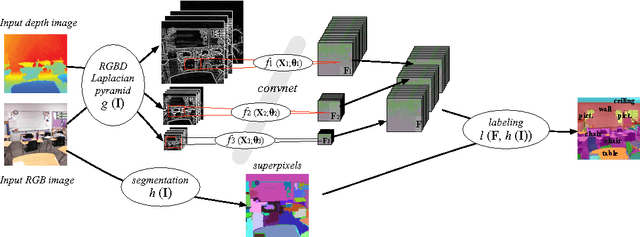
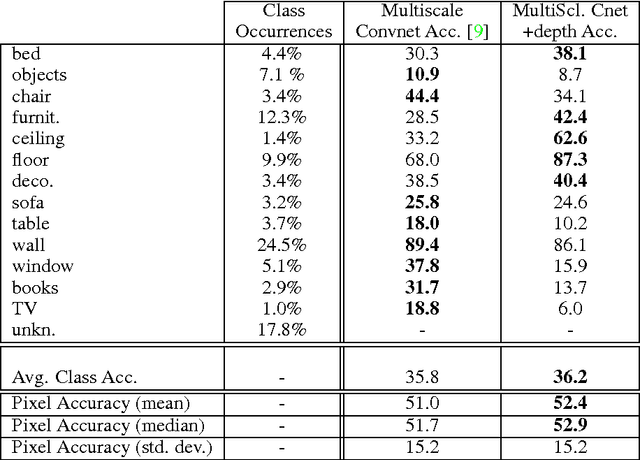


This work addresses multi-class segmentation of indoor scenes with RGB-D inputs. While this area of research has gained much attention recently, most works still rely on hand-crafted features. In contrast, we apply a multiscale convolutional network to learn features directly from the images and the depth information. We obtain state-of-the-art on the NYU-v2 depth dataset with an accuracy of 64.5%. We illustrate the labeling of indoor scenes in videos sequences that could be processed in real-time using appropriate hardware such as an FPGA.
Causal graph-based video segmentation
Jan 08, 2013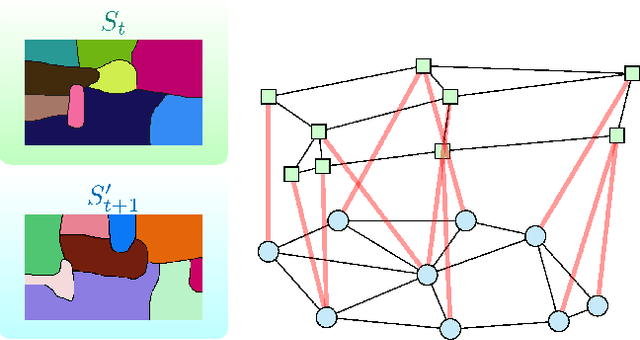
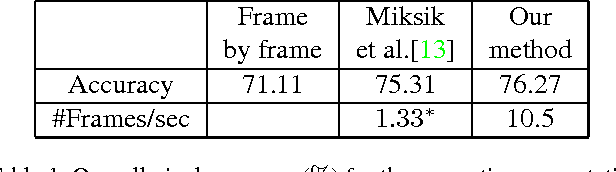


Numerous approaches in image processing and computer vision are making use of super-pixels as a pre-processing step. Among the different methods producing such over-segmentation of an image, the graph-based approach of Felzenszwalb and Huttenlocher is broadly employed. One of its interesting properties is that the regions are computed in a greedy manner in quasi-linear time. The algorithm may be trivially extended to video segmentation by considering a video as a 3D volume, however, this can not be the case for causal segmentation, when subsequent frames are unknown. We propose an efficient video segmentation approach that computes temporally consistent pixels in a causal manner, filling the need for causal and real time applications.
Scene Parsing with Multiscale Feature Learning, Purity Trees, and Optimal Covers
Jul 13, 2012Scene parsing, or semantic segmentation, consists in labeling each pixel in an image with the category of the object it belongs to. It is a challenging task that involves the simultaneous detection, segmentation and recognition of all the objects in the image. The scene parsing method proposed here starts by computing a tree of segments from a graph of pixel dissimilarities. Simultaneously, a set of dense feature vectors is computed which encodes regions of multiple sizes centered on each pixel. The feature extractor is a multiscale convolutional network trained from raw pixels. The feature vectors associated with the segments covered by each node in the tree are aggregated and fed to a classifier which produces an estimate of the distribution of object categories contained in the segment. A subset of tree nodes that cover the image are then selected so as to maximize the average "purity" of the class distributions, hence maximizing the overall likelihood that each segment will contain a single object. The convolutional network feature extractor is trained end-to-end from raw pixels, alleviating the need for engineered features. After training, the system is parameter free. The system yields record accuracies on the Stanford Background Dataset (8 classes), the Sift Flow Dataset (33 classes) and the Barcelona Dataset (170 classes) while being an order of magnitude faster than competing approaches, producing a 320 \times 240 image labeling in less than 1 second.