 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeTree -- A modular, open-source system for tree detection and orchard localization
Apr 14, 2025



Accurate localization is an important functional requirement for precision orchard management. However, there are few off-the-shelf commercial solutions available to growers. In this paper, we present SeeTree, a modular, open source embedded system for tree trunk detection and orchard localization that is deployable on any vehicle. Building on our prior work on vision-based in-row localization using particle filters, SeeTree includes several new capabilities. First, it provides capacity for full orchard localization including out-of-row headland turning. Second, it includes the flexibility to integrate either visual, GNSS, or wheel odometry in the motion model. During field experiments in a commercial orchard, the system converged to the correct location 99% of the time over 800 trials, even when starting with large uncertainty in the initial particle locations. When turning out of row, the system correctly tracked 99% of the turns (860 trials representing 43 unique row changes). To help support adoption and future research and development, we make our dataset, design files, and source code freely available to the community.
Compact robotic gripper with tandem actuation for selective fruit harvesting
Aug 13, 2024Selective fruit harvesting is a challenging manipulation problem due to occlusions and clutter arising from plant foliage. A harvesting gripper should i) have a small cross-section, to avoid collisions while approaching the fruit; ii) have a soft and compliant grasp to adapt to different fruit geometry and avoid bruising it; and iii) be capable of rigidly holding the fruit tightly enough to counteract detachment forces. Previous work on fruit harvesting has primarily focused on using grippers with a single actuation mode, either suction or fingers. In this paper we present a compact robotic gripper that combines the benefits of both. The gripper first uses an array of compliant suction cups to gently attach to the fruit. After attachment, telescoping cam-driven fingers deploy, sweeping obstacles away before pivoting inwards to provide a secure grip on the fruit for picking. We present and analyze the finger design for both ability to sweep clutter and maintain a tight grasp. Specifically, we use a motorized test bed to measure grasp strength for each actuation mode (suction, fingers, or both). We apply a tensile force at different angles (0{\deg}, 15{\deg}, 30{\deg} and 45{\deg}), and vary the point of contact between the fingers and the fruit. We observed that with both modes the grasp strength is approximately 40 N. We use an apple proxy to test the gripper's ability to obtain a grasp in the presence of occluding apples and leaves, achieving a grasp success rate over 96% (with an ideal controller). Finally, we validate our gripper in a commercial apple orchard.
Uncovering implementable dormant pruning decisions from three different stakeholder perspectives
May 07, 2024



Dormant pruning, or the removal of unproductive portions of a tree while a tree is not actively growing, is an important orchard task to help maintain yield, requiring years to build expertise. Because of long training periods and an increasing labor shortage in agricultural jobs, pruning could benefit from robotic automation. However, to program robots to prune branches, we first need to understand how pruning decisions are made, and what variables in the environment (e.g., branch size and thickness) we need to capture. Working directly with three pruning stakeholders -- horticulturists, growers, and pruners -- we find that each group of human experts approaches pruning decision-making differently. To capture this knowledge, we present three studies and two extracted pruning protocols from field work conducted in Prosser, Washington in January 2022 and 2023. We interviewed six stakeholders (two in each group) and observed pruning across three cultivars -- Bing Cherries, Envy Apples, and Jazz Apples -- and two tree architectures -- Upright Fruiting Offshoot and V-Trellis. Leveraging participant interviews and video data, this analysis uses grounded coding to extract pruning terminology, discover horticultural contexts that influence pruning decisions, and find implementable pruning heuristics for autonomous systems. The results include a validated terminology set, which we offer for use by both pruning stakeholders and roboticists, to communicate general pruning concepts and heuristics. The results also highlight seven pruning heuristics utilizing this terminology set that would be relevant for use by future autonomous robot pruning systems, and characterize three discovered horticultural contexts (i.e., environmental management, crop-load management, and replacement wood) across all three cultivars.
Machine Vision Based Assessment of Fall Color Changes in Apple Trees: Exploring Relationship with Leaf Nitrogen Concentration
Apr 23, 2024



Apple trees being deciduous trees, shed leaves each year which is preceded by the change in color of leaves from green to yellow (also known as senescence) during the fall season. The rate and timing of color change are affected by the number of factors including nitrogen (N) deficiencies. The green color of leaves is highly dependent on the chlorophyll content, which in turn depends on the nitrogen concentration in the leaves. The assessment of the leaf color can give vital information on the nutrient status of the tree. The use of a machine vision based system to capture and quantify these timings and changes in leaf color can be a great tool for that purpose. \par This study is based on data collected during the fall of 2021 and 2023 at a commercial orchard using a ground-based stereo-vision sensor for five weeks. The point cloud obtained from the sensor was segmented to get just the tree in the foreground. The study involved the segmentation of the trees in a natural background using point cloud data and quantification of the color using a custom-defined metric, \textit{yellowness index}, varying from $-1$ to $+1$ ($-1$ being completely green and $+1$ being completely yellow), which gives the proportion of yellow leaves on a tree. The performance of K-means based algorithm and gradient boosting algorithm were compared for \textit{yellowness index} calculation. The segmentation method proposed in the study was able to estimate the \textit{yellowness index} on the trees with $R^2 = 0.72$. The results showed that the metric was able to capture the gradual color transition from green to yellow over the study duration. It was also observed that the trees with lower nitrogen showed the color transition to yellow earlier than the trees with higher nitrogen. The onset of color transition during both years aligned with the $29^{th}$ week post-full bloom.
The Grasp Reset Mechanism: An Automated Apparatus for Conducting Grasping Trials
Feb 28, 2024



Advancing robotic grasping and manipulation requires the ability to test algorithms and/or train learning models on large numbers of grasps. Towards the goal of more advanced grasping, we present the Grasp Reset Mechanism (GRM), a fully automated apparatus for conducting large-scale grasping trials. The GRM automates the process of resetting a grasping environment, repeatably placing an object in a fixed location and controllable 1-D orientation. It also collects data and swaps between multiple objects enabling robust dataset collection with no human intervention. We also present a standardized state machine interface for control, which allows for integration of most manipulators with minimal effort. In addition to the physical design and corresponding software, we include a dataset of 1,020 grasps. The grasps were created with a Kinova Gen3 robot arm and Robotiq 2F-85 Adaptive Gripper to enable training of learning models and to demonstrate the capabilities of the GRM. The dataset includes ranges of grasps conducted across four objects and a variety of orientations. Manipulator states, object pose, video, and grasp success data are provided for every trial.
The Door and Drawer Reset Mechanisms: Automated Mechanisms for Testing and Data Collection
Feb 26, 2024



Robotic manipulation in human environments is a challenging problem for researchers and industry alike. In particular, opening doors/drawers can be challenging for robots, as the size, shape, actuation and required force is variable. Because of this, it can be difficult to collect large real-world datasets and to benchmark different control algorithms on the same hardware. In this paper we present two automated testbeds, the Door Reset Mechanism (DORM) and Drawer Reset Mechanism (DWRM), for the purpose of real world testing and data collection. These devices are low-cost, are sensorized, operate with customized variable resistance, and come with open source software. Additionally, we provide a dataset of over 600 grasps using the DORM and DWRM. We use this dataset to highlight how much variability can exist even with the same trial on the same hardware. This data can also serve as a source for real-world noise in simulation environments.
A real-time, hardware agnostic framework for close-up branch reconstruction using RGB data
Sep 20, 2023



Creating accurate 3D models of tree topology is an important task for tree pruning. The 3D model is used to decide which branches to prune and then to execute the pruning cuts. Previous methods for creating 3D tree models have typically relied on point clouds, which are often computationally expensive to process and can suffer from data defects, especially with thin branches. In this paper, we propose a method for actively scanning along a primary tree branch, detecting secondary branches to be pruned, and reconstructing their 3D geometry using just an RGB camera mounted on a robot arm. We experimentally validate that our setup is able to produce primary branch models with 4-5 mm accuracy and secondary branch models with 15 degrees orientation accuracy with respect to the ground truth model. Our framework is real-time and can run up to 10 cm/s with no loss in model accuracy or ability to detect secondary branches.
Optimization-Based Mechanical Perception for Peduncle Localization During Robotic Fruit Harvest
Sep 27, 2022

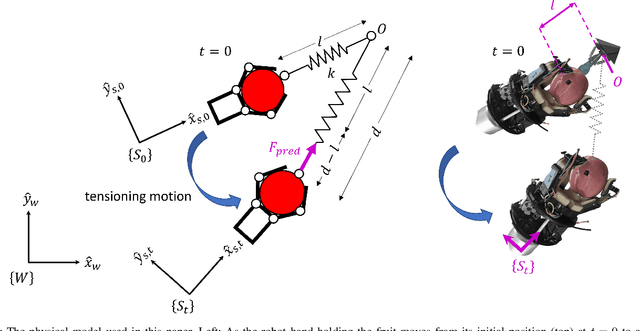
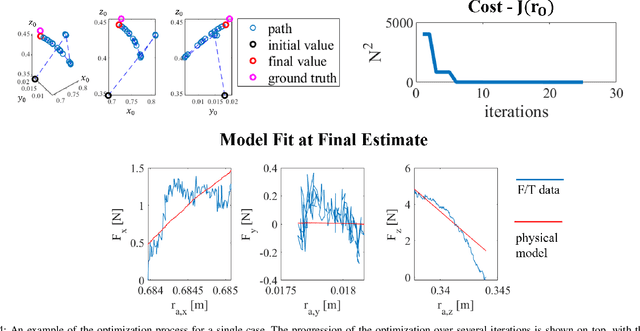
Rising global food demand and harsh working conditions make fruit harvest an important domain to automate. Peduncle localization is an important step for any automated fruit harvesting system, since fruit separation techniques are highly sensitive to peduncle location. Most work on peduncle localization has focused on computer vision, but peduncles can be difficult to visually access due to the cluttered nature of agricultural environments. Our work proposes an alternative method which relies on mechanical -- rather than visual -- perception to localize the peduncle. To estimate the location of this important plant feature, we fit wrench measurements from a wrist force/torque sensor to a physical model of the fruit-plant system, treating the fruit's attachment point as a parameter to be tuned. This method is performed inline as part of the fruit picking procedure. Using our orchard proxy for evaluation, we demonstrate that the technique is able to localize the peduncle within a median distance of 3.8 cm and median orientation error of 16.8 degrees.
Measuring a Robot Hand's Graspable Region using Power and Precision Grasps
Apr 27, 2022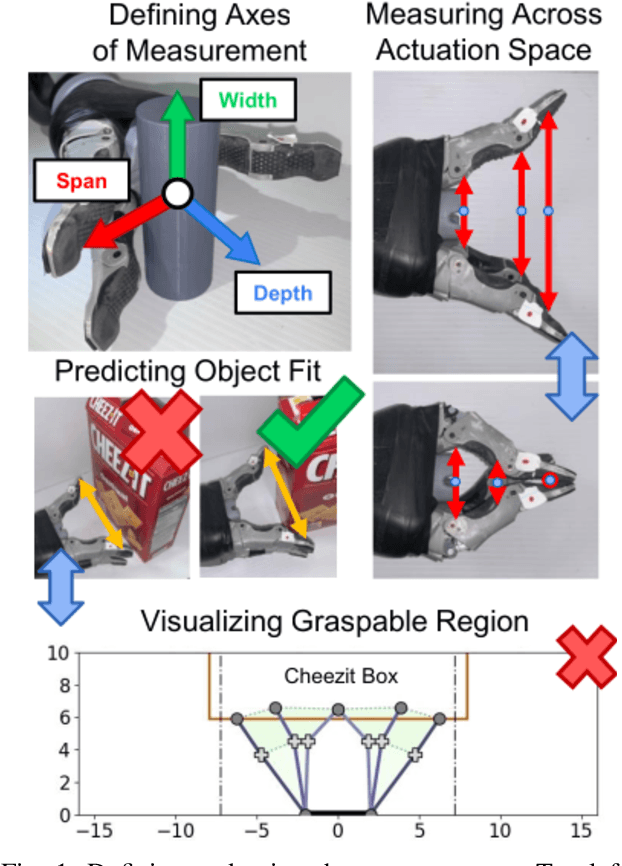
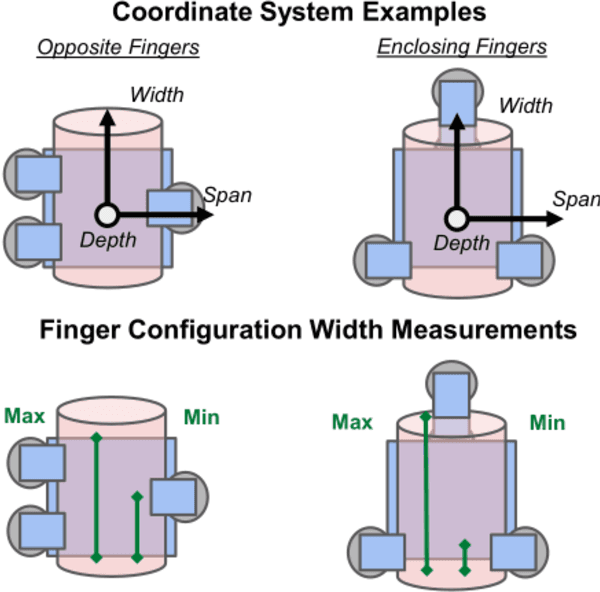
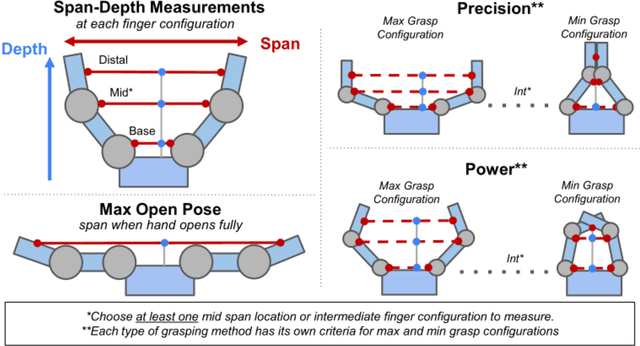
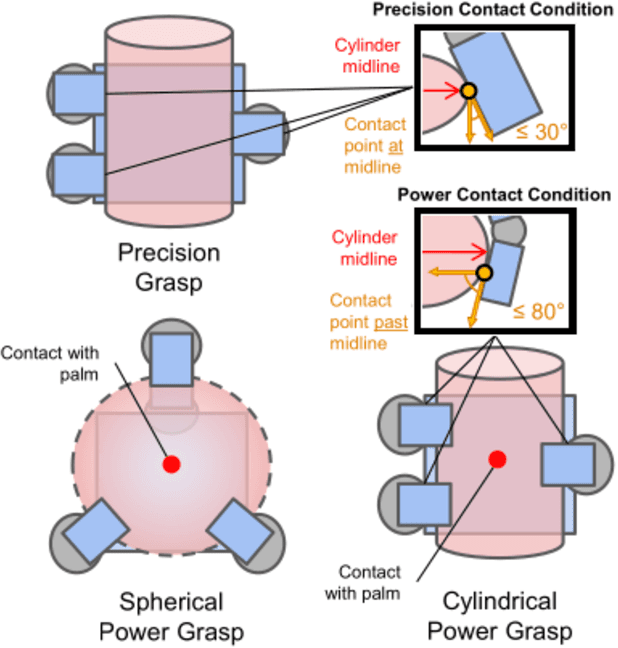
The variety of robotic hand designs and actuation schemes makes it difficult to measure a hand's graspable volume. For end-users, this lack of standardized measurements makes it challenging to determine a priori if a robot hand is the right size for grasping an object. We propose a practical hand measurement standard, based on precision and power grasps, that is applicable to a wide variety of robot hand designs. The resulting measurements can be used to both determine if an object will fit in the hand and characterize the size of an object with respect to the hand. Our measurement procedure uses a functional approach, based on grasping a hypothetical cylinder, that allows the measurer choose the exact hand orientation and finger configurations that are used for the measurements. This ensures that the measurements are functionally comparable while relying on the human to determine the finger configurations that best match the intended grasp. We demonstrate using our measurement standard with three commercial robot hand designs and objects from the YCB data set.
Optical flow-based branch segmentation for complex orchard environments
Feb 26, 2022



Machine vision is a critical subsystem for enabling robots to be able to perform a variety of tasks in orchard environments. However, orchards are highly visually complex environments, and computer vision algorithms operating in them must be able to contend with variable lighting conditions and background noise. Past work on enabling deep learning algorithms to operate in these environments has typically required large amounts of hand-labeled data to train a deep neural network or physically controlling the conditions under which the environment is perceived. In this paper, we train a neural network system in simulation only using simulated RGB data and optical flow. This resulting neural network is able to perform foreground segmentation of branches in a busy orchard environment without additional real-world training or using any special setup or equipment beyond a standard camera. Our results show that our system is highly accurate and, when compared to a network using manually labeled RGBD data, achieves significantly more consistent and robust performance across environments that differ from the training set.