 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPPD: Adaptive and Precise Pupil Boundary Detection using Entropy of Contour Gradients
Aug 09, 2018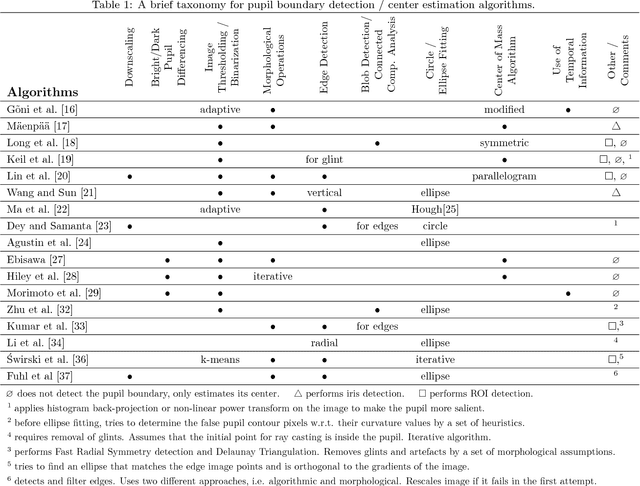
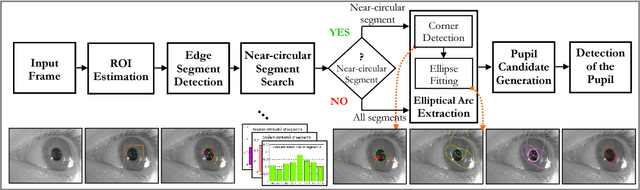
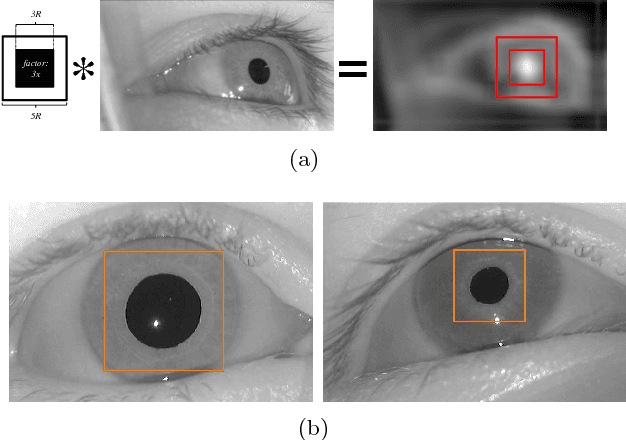
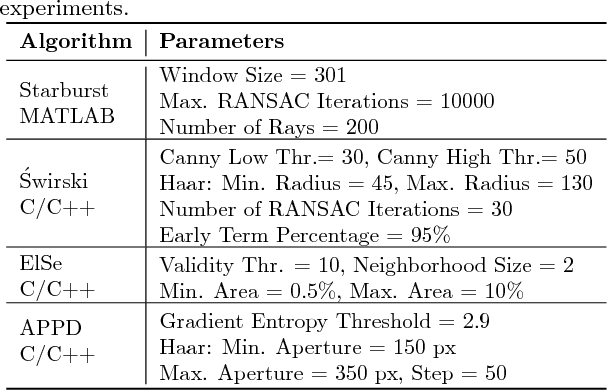
Eye tracking spreads through a vast area of applications from ophthalmology, assistive technologies to gaming and virtual reality. Precisely detecting the pupil's contour and center is the very first step in many of these tasks, hence needs to be performed accurately. Although detection of pupil is a simple problem when it is entirely visible; occlusions and oblique view angles complicate the solution. In this study, we propose APPD, an adaptive and precise pupil boundary detection method that is able to infer whether entire pupil is in clearly visible by a heuristic that estimates the shape of a contour in a computationally efficient way. Thus, a faster detection is performed with the assumption of no occlusions. If the heuristic fails, a more comprehensive search among extracted image features is executed to maintain accuracy. Furthermore, the algorithm can find out if there is no pupil as an helpful information for many applications. We provide a dataset containing 3904 high resolution eye images collected from 12 subjects and perform an extensive set of experiments to obtain quantitative results in terms of accuracy, localization and timing. The proposed method outperforms three other state of the art algorithms and has an average execution time $\sim$5 ms in single-thread on a standard laptop computer for 720p images.
STag: A Stable Fiducial Marker System
Jul 19, 2017


In this paper, we propose STag, a fiducial marker system that provides stable pose estimation. The outer square border of the marker is used for detection and pose estimation. This is followed by a novel pose refinement step using the inner circular border. The refined pose is more stable and robust across viewing conditions compared to the state of the art. In addition, the lexicographic generation algorithm is adapted for fiducial markers, and libraries with various sizes are created. This makes the system suitable for applications that require many unique markers, or few unique markers with high occlusion resistance. The edge segment-based detection algorithm is of low complexity, and returns few false candidates. These features are demonstrated with experiments on real images, including comparisons with the state of the art fiducial marker systems.
Lens Distortion Rectification using Triangulation based Interpolation
Jul 03, 2017


Nonlinear lens distortion rectification is a common first step in image processing applications where the assumption of a linear camera model is essential. For rectifying the lens distortion, forward distortion model needs to be known. However, many self-calibration methods estimate the inverse distortion model. In the literature, the inverse of the estimated model is approximated for image rectification, which introduces additional error to the system. We propose a novel distortion rectification method that uses the inverse distortion model directly. The method starts by mapping the distorted pixels to the rectified image using the inverse distortion model. The resulting set of points with subpixel locations are triangulated. The pixel values of the rectified image are linearly interpolated based on this triangulation. The method is applicable to all camera calibration methods that estimate the inverse distortion model and performs well across a large range of parameters.
Greedy Search for Descriptive Spatial Face Features
Jul 03, 2017
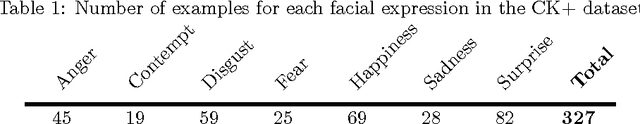

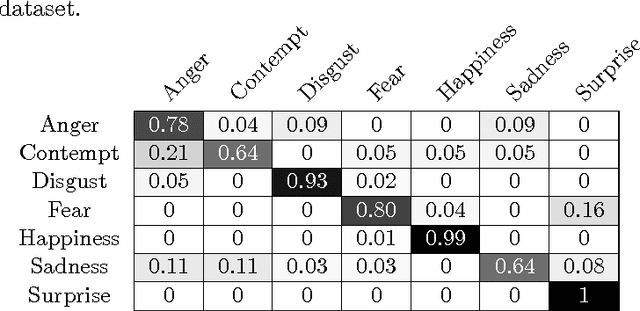
Facial expression recognition methods use a combination of geometric and appearance-based features. Spatial features are derived from displacements of facial landmarks, and carry geometric information. These features are either selected based on prior knowledge, or dimension-reduced from a large pool. In this study, we produce a large number of potential spatial features using two combinations of facial landmarks. Among these, we search for a descriptive subset of features using sequential forward selection. The chosen feature subset is used to classify facial expressions in the extended Cohn-Kanade dataset (CK+), and delivered 88.7% recognition accuracy without using any appearance-based features.