 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTag: A Stable Fiducial Marker System
Jul 19, 2017

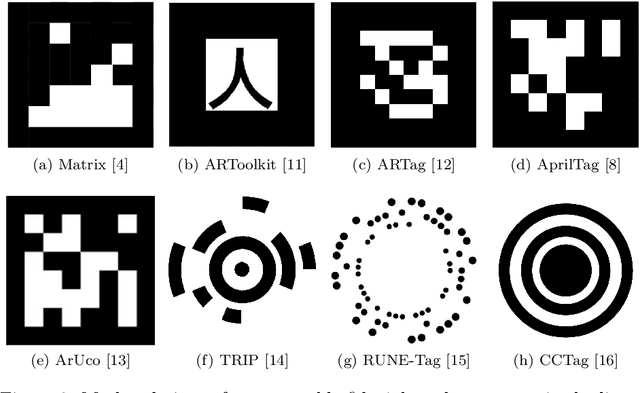

In this paper, we propose STag, a fiducial marker system that provides stable pose estimation. The outer square border of the marker is used for detection and pose estimation. This is followed by a novel pose refinement step using the inner circular border. The refined pose is more stable and robust across viewing conditions compared to the state of the art. In addition, the lexicographic generation algorithm is adapted for fiducial markers, and libraries with various sizes are created. This makes the system suitable for applications that require many unique markers, or few unique markers with high occlusion resistance. The edge segment-based detection algorithm is of low complexity, and returns few false candidates. These features are demonstrated with experiments on real images, including comparisons with the state of the art fiducial marker systems.
Lens Distortion Rectification using Triangulation based Interpolation
Jul 03, 2017

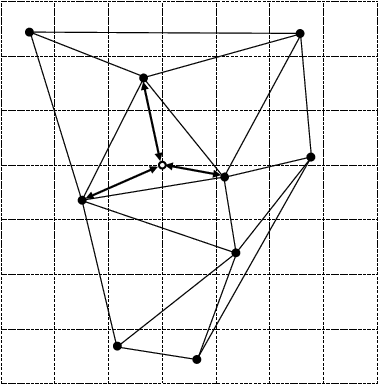

Nonlinear lens distortion rectification is a common first step in image processing applications where the assumption of a linear camera model is essential. For rectifying the lens distortion, forward distortion model needs to be known. However, many self-calibration methods estimate the inverse distortion model. In the literature, the inverse of the estimated model is approximated for image rectification, which introduces additional error to the system. We propose a novel distortion rectification method that uses the inverse distortion model directly. The method starts by mapping the distorted pixels to the rectified image using the inverse distortion model. The resulting set of points with subpixel locations are triangulated. The pixel values of the rectified image are linearly interpolated based on this triangulation. The method is applicable to all camera calibration methods that estimate the inverse distortion model and performs well across a large range of parameters.
Greedy Search for Descriptive Spatial Face Features
Jul 03, 2017
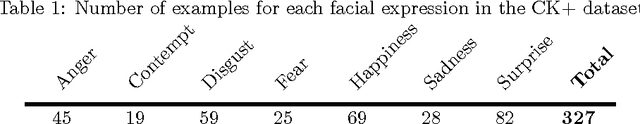

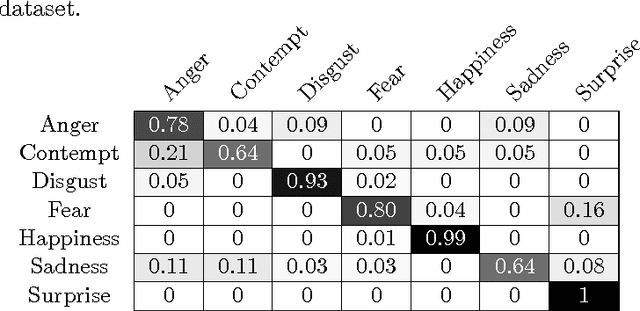
Facial expression recognition methods use a combination of geometric and appearance-based features. Spatial features are derived from displacements of facial landmarks, and carry geometric information. These features are either selected based on prior knowledge, or dimension-reduced from a large pool. In this study, we produce a large number of potential spatial features using two combinations of facial landmarks. Among these, we search for a descriptive subset of features using sequential forward selection. The chosen feature subset is used to classify facial expressions in the extended Cohn-Kanade dataset (CK+), and delivered 88.7% recognition accuracy without using any appearance-based features.