 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Compression-Precision Paradox: A Hybrid Architecture for Clinical EEG Report Generation with Guaranteed Measurement Accuracy
Feb 11, 2026Automated EEG monitoring requires clinician-level precision for seizure detection and reporting. Clinical EEG recordings exceed LLM context windows, requiring extreme compression (400:1+ ratios) that destroys fine-grained temporal precision. A 0.5 Hz error distinguishes absence epilepsy from Lennox-Gastaut syndrome. LLMs lack inherent time-series comprehension and rely on statistical associations from compressed representations. This dual limitation causes systems to hallucinate clinically incorrect measurement values. We separate measurement extraction from text generation. Our hybrid architecture computes exact clinical values via signal processing before compression, employs a cross-modal bridge for EEG-to-language translation, and uses parameter-efficient fine-tuning with constrained decoding around frozen slots. Multirate sampling maintains long-range context while preserving event-level precision. Evaluation on TUH and CHB-MIT datasets achieves 60% fewer false alarms, 50% faster detection, and sub-clinical measurement precision. This is the first system guaranteeing clinical measurement accuracy in automated EEG reports.
SemanticForge: Repository-Level Code Generation through Semantic Knowledge Graphs and Constraint Satisfaction
Nov 10, 2025Large language models (LLMs) have transformed software development by enabling automated code generation, yet they frequently suffer from systematic errors that limit practical deployment. We identify two critical failure modes: \textit{logical hallucination} (incorrect control/data-flow reasoning) and \textit{schematic hallucination} (type mismatches, signature violations, and architectural inconsistencies). These errors stem from the absence of explicit, queryable representations of repository-wide semantics. This paper presents \textbf{SemanticForge}, which introduces four fundamental algorithmic advances for semantically-aware code generation: (1) a novel automatic reconciliation algorithm for dual static-dynamic knowledge graphs, unifying compile-time and runtime program semantics; (2) a neural approach that learns to generate structured graph queries from natural language, achieving 73\% precision versus 51\% for traditional retrieval; (3) a novel beam search algorithm with integrated SMT solving, enabling real-time constraint verification during generation rather than post-hoc validation; and (4) an incremental maintenance algorithm that updates knowledge graphs in $O(|ΔR| \cdot \log n)$ time while maintaining semantic equivalence.
Malware Knowledge Graph Generation
Feb 10, 2021
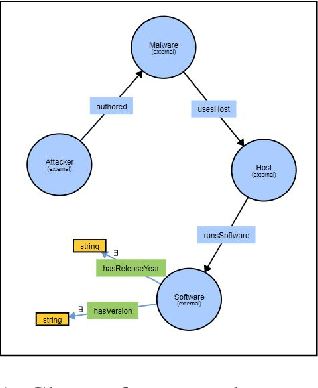
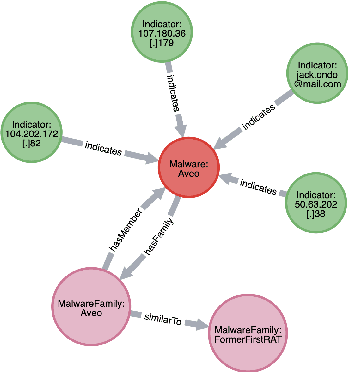
Cyber threat and attack intelligence information are available in non-standard format from heterogeneous sources. Comprehending them and utilizing them for threat intelligence extraction requires engaging security experts. Knowledge graphs enable converting this unstructured information from heterogeneous sources into a structured representation of data and factual knowledge for several downstream tasks such as predicting missing information and future threat trends. Existing large-scale knowledge graphs mainly focus on general classes of entities and relationships between them. Open-source knowledge graphs for the security domain do not exist. To fill this gap, we've built \textsf{TINKER} - a knowledge graph for threat intelligence (\textbf{T}hreat \textbf{IN}telligence \textbf{K}nowl\textbf{E}dge g\textbf{R}aph). \textsf{TINKER} is generated using RDF triples describing entities and relations from tokenized unstructured natural language text from 83 threat reports published between 2006-2021. We built \textsf{TINKER} using classes and properties defined by open-source malware ontology and using hand-annotated RDF triples. We also discuss ongoing research and challenges faced while creating \textsf{TINKER}.