 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProduct Knowledge Graph Embedding for E-commerce
Nov 28, 2019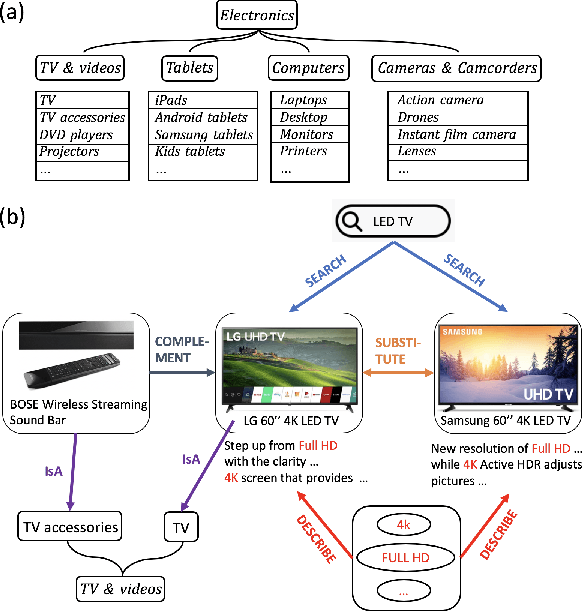
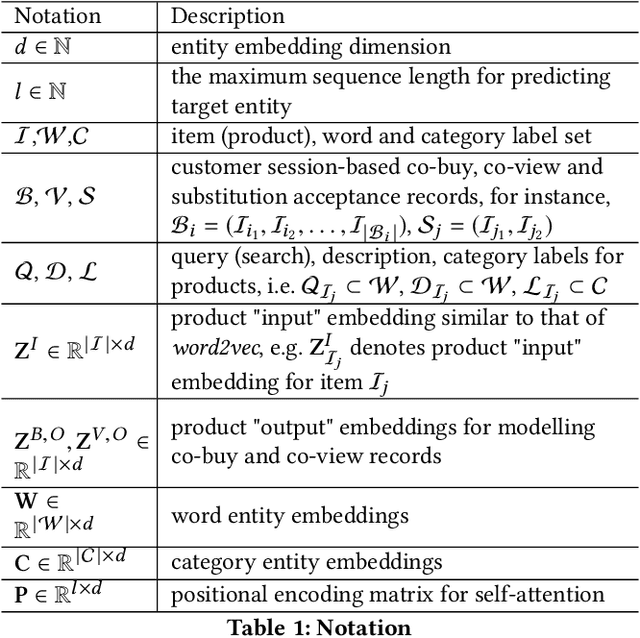
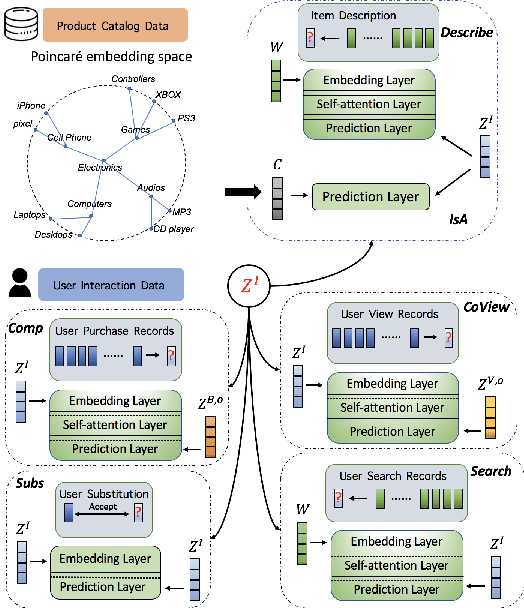

In this paper, we propose a new product knowledge graph (PKG) embedding approach for learning the intrinsic product relations as product knowledge for e-commerce. We define the key entities and summarize the pivotal product relations that are critical for general e-commerce applications including marketing, advertisement, search ranking and recommendation. We first provide a comprehensive comparison between PKG and ordinary knowledge graph (KG) and then illustrate why KG embedding methods are not suitable for PKG learning. We construct a self-attention-enhanced distributed representation learning model for learning PKG embeddings from raw customer activity data in an end-to-end fashion. We design an effective multi-task learning schema to fully leverage the multi-modal e-commerce data. The Poincare embedding is also employed to handle complex entity structures. We use a real-world dataset from grocery.walmart.com to evaluate the performances on knowledge completion, search ranking and recommendation. The proposed approach compares favourably to baselines in knowledge completion and downstream tasks.
Generative Graph Convolutional Network for Growing Graphs
Mar 06, 2019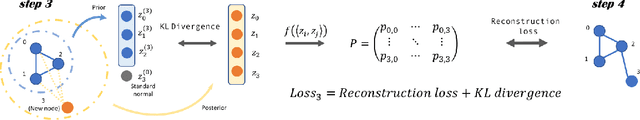
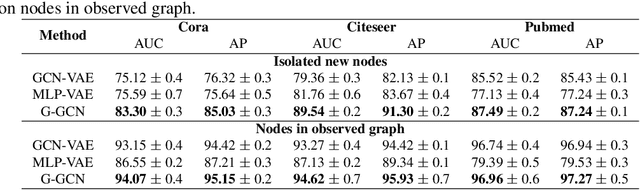
Modeling generative process of growing graphs has wide applications in social networks and recommendation systems, where cold start problem leads to new nodes isolated from existing graph. Despite the emerging literature in learning graph representation and graph generation, most of them can not handle isolated new nodes without nontrivial modifications. The challenge arises due to the fact that learning to generate representations for nodes in observed graph relies heavily on topological features, whereas for new nodes only node attributes are available. Here we propose a unified generative graph convolutional network that learns node representations for all nodes adaptively in a generative model framework, by sampling graph generation sequences constructed from observed graph data. We optimize over a variational lower bound that consists of a graph reconstruction term and an adaptive Kullback-Leibler divergence regularization term. We demonstrate the superior performance of our approach on several benchmark citation network datasets.