 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThompson Sampling For Stochastic Bandits with Graph Feedback
Jan 16, 2017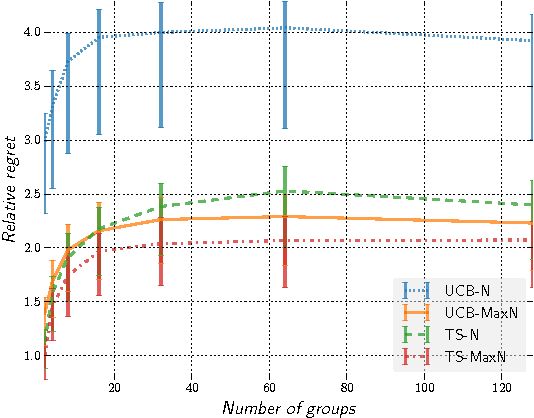
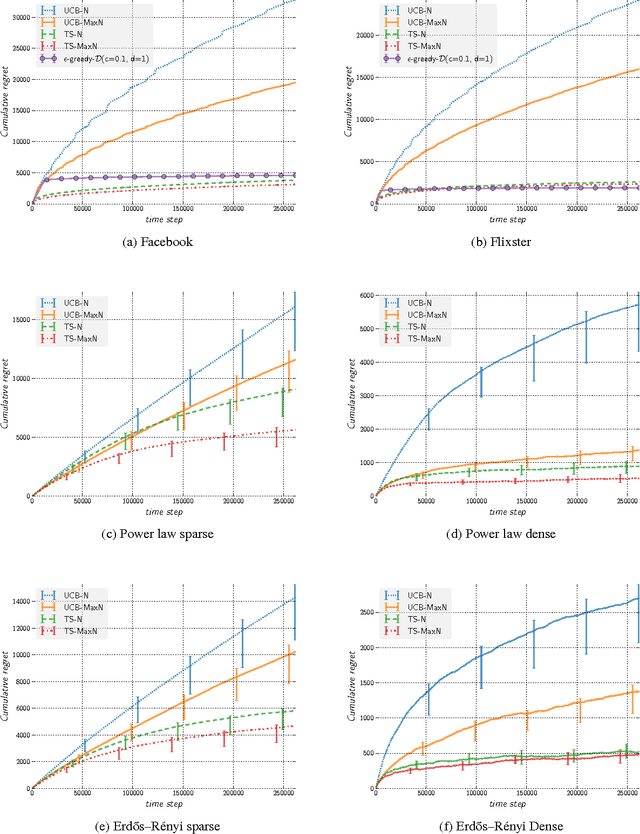
We present a novel extension of Thompson Sampling for stochastic sequential decision problems with graph feedback, even when the graph structure itself is unknown and/or changing. We provide theoretical guarantees on the Bayesian regret of the algorithm, linking its performance to the underlying properties of the graph. Thompson Sampling has the advantage of being applicable without the need to construct complicated upper confidence bounds for different problems. We illustrate its performance through extensive experimental results on real and simulated networks with graph feedback. More specifically, we tested our algorithms on power law, planted partitions and Erdo's-Renyi graphs, as well as on graphs derived from Facebook and Flixster data. These all show that our algorithms clearly outperform related methods that employ upper confidence bounds, even if the latter use more information about the graph.
Achieving Privacy in the Adversarial Multi-Armed Bandit
Jan 16, 2017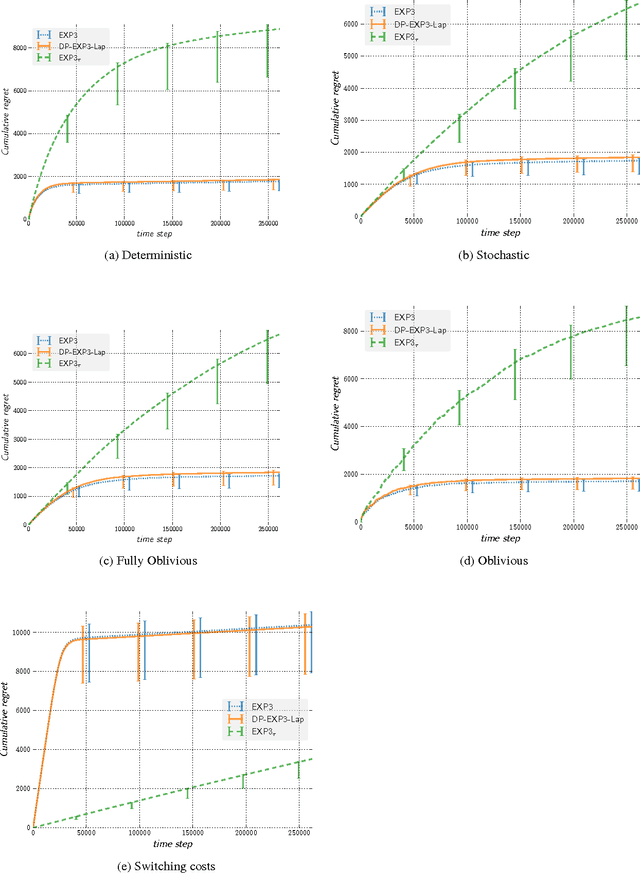
In this paper, we improve the previously best known regret bound to achieve $\epsilon$-differential privacy in oblivious adversarial bandits from $\mathcal{O}{(T^{2/3}/\epsilon)}$ to $\mathcal{O}{(\sqrt{T} \ln T /\epsilon)}$. This is achieved by combining a Laplace Mechanism with EXP3. We show that though EXP3 is already differentially private, it leaks a linear amount of information in $T$. However, we can improve this privacy by relying on its intrinsic exponential mechanism for selecting actions. This allows us to reach $\mathcal{O}{(\sqrt{\ln T})}$-DP, with a regret of $\mathcal{O}{(T^{2/3})}$ that holds against an adaptive adversary, an improvement from the best known of $\mathcal{O}{(T^{3/4})}$. This is done by using an algorithm that run EXP3 in a mini-batch loop. Finally, we run experiments that clearly demonstrate the validity of our theoretical analysis.
Bayesian Differential Privacy through Posterior Sampling
Dec 23, 2016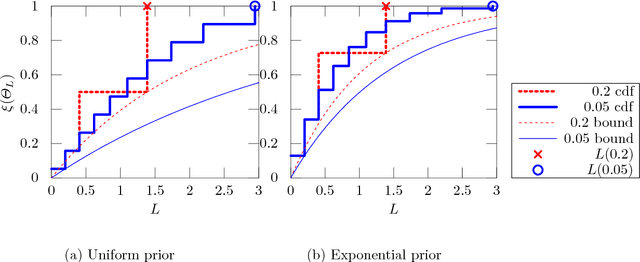
Differential privacy formalises privacy-preserving mechanisms that provide access to a database. We pose the question of whether Bayesian inference itself can be used directly to provide private access to data, with no modification. The answer is affirmative: under certain conditions on the prior, sampling from the posterior distribution can be used to achieve a desired level of privacy and utility. To do so, we generalise differential privacy to arbitrary dataset metrics, outcome spaces and distribution families. This allows us to also deal with non-i.i.d or non-tabular datasets. We prove bounds on the sensitivity of the posterior to the data, which gives a measure of robustness. We also show how to use posterior sampling to provide differentially private responses to queries, within a decision-theoretic framework. Finally, we provide bounds on the utility and on the distinguishability of datasets. The latter are complemented by a novel use of Le Cam's method to obtain lower bounds. All our general results hold for arbitrary database metrics, including those for the common definition of differential privacy. For specific choices of the metric, we give a number of examples satisfying our assumptions.
On the Differential Privacy of Bayesian Inference
Dec 22, 2015
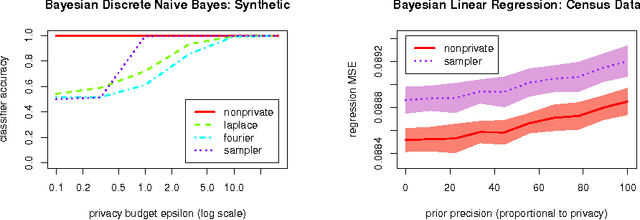
We study how to communicate findings of Bayesian inference to third parties, while preserving the strong guarantee of differential privacy. Our main contributions are four different algorithms for private Bayesian inference on proba-bilistic graphical models. These include two mechanisms for adding noise to the Bayesian updates, either directly to the posterior parameters, or to their Fourier transform so as to preserve update consistency. We also utilise a recently introduced posterior sampling mechanism, for which we prove bounds for the specific but general case of discrete Bayesian networks; and we introduce a maximum-a-posteriori private mechanism. Our analysis includes utility and privacy bounds, with a novel focus on the influence of graph structure on privacy. Worked examples and experiments with Bayesian na{\"i}ve Bayes and Bayesian linear regression illustrate the application of our mechanisms.
Algorithms for Differentially Private Multi-Armed Bandits
Nov 27, 2015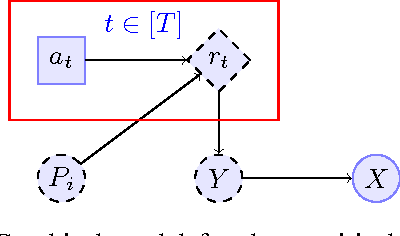
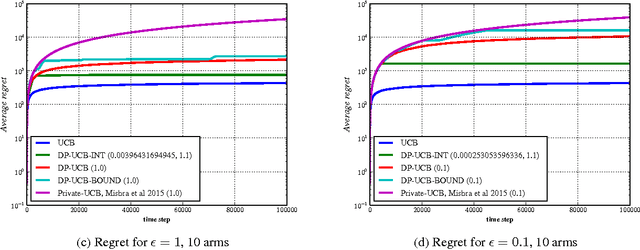
We present differentially private algorithms for the stochastic Multi-Armed Bandit (MAB) problem. This is a problem for applications such as adaptive clinical trials, experiment design, and user-targeted advertising where private information is connected to individual rewards. Our major contribution is to show that there exist $(\epsilon, \delta)$ differentially private variants of Upper Confidence Bound algorithms which have optimal regret, $O(\epsilon^{-1} + \log T)$. This is a significant improvement over previous results, which only achieve poly-log regret $O(\epsilon^{-2} \log^{2} T)$, because of our use of a novel interval-based mechanism. We also substantially improve the bounds of previous family of algorithms which use a continual release mechanism. Experiments clearly validate our theoretical bounds.
Generalised Entropy MDPs and Minimax Regret
Dec 10, 2014Bayesian methods suffer from the problem of how to specify prior beliefs. One interesting idea is to consider worst-case priors. This requires solving a stochastic zero-sum game. In this paper, we extend well-known results from bandit theory in order to discover minimax-Bayes policies and discuss when they are practical.
Personalized News Recommendation with Context Trees
Nov 03, 2014
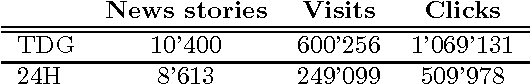
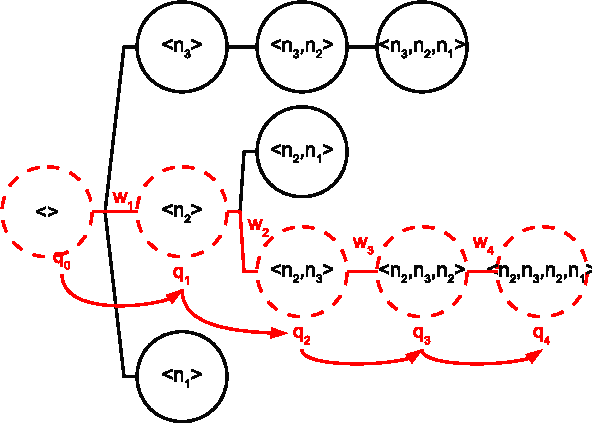
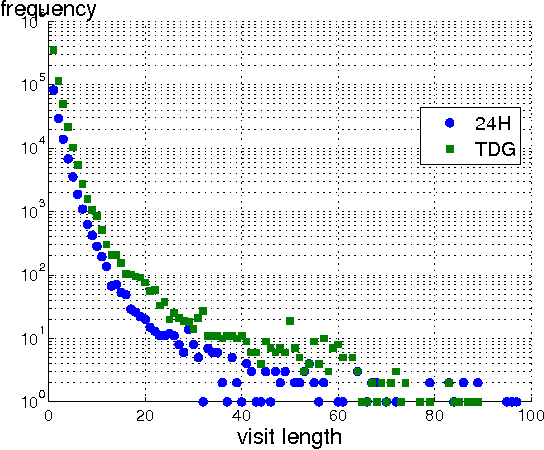
The profusion of online news articles makes it difficult to find interesting articles, a problem that can be assuaged by using a recommender system to bring the most relevant news stories to readers. However, news recommendation is challenging because the most relevant articles are often new content seen by few users. In addition, they are subject to trends and preference changes over time, and in many cases we do not have sufficient information to profile the reader. In this paper, we introduce a class of news recommendation systems based on context trees. They can provide high-quality news recommendation to anonymous visitors based on present browsing behaviour. We show that context-tree recommender systems provide good prediction accuracy and recommendation novelty, and they are sufficiently flexible to capture the unique properties of news articles.
Probabilistic inverse reinforcement learning in unknown environments
Aug 09, 2014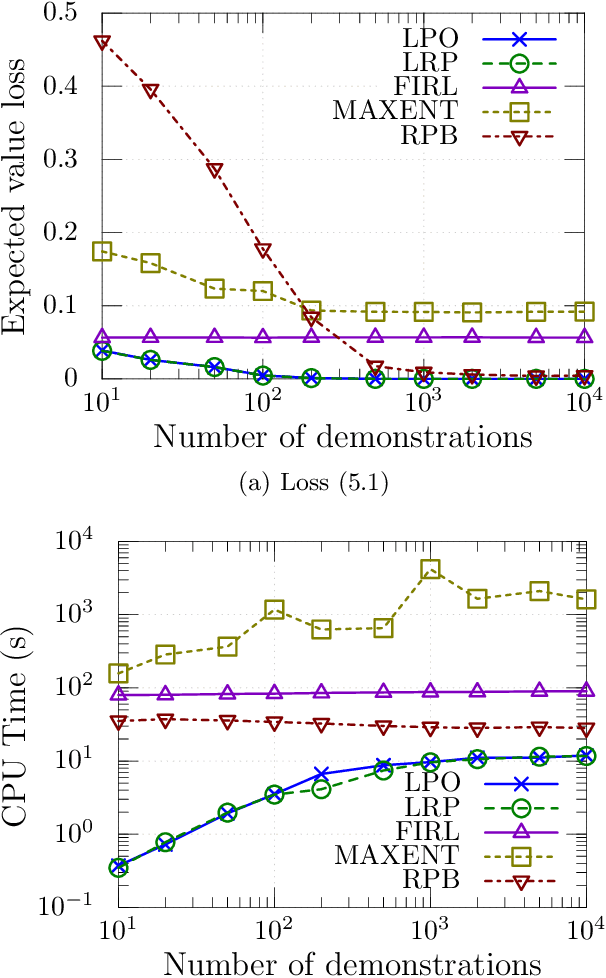
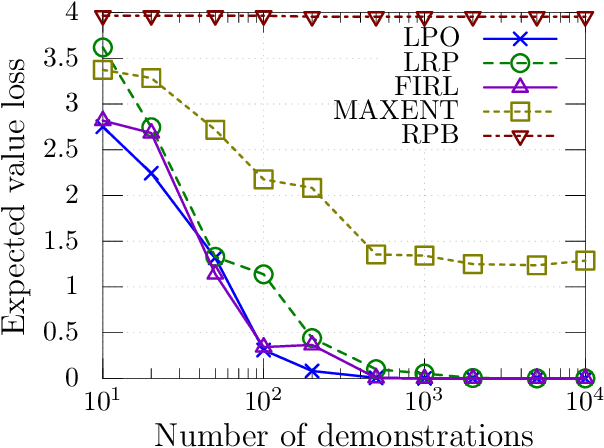
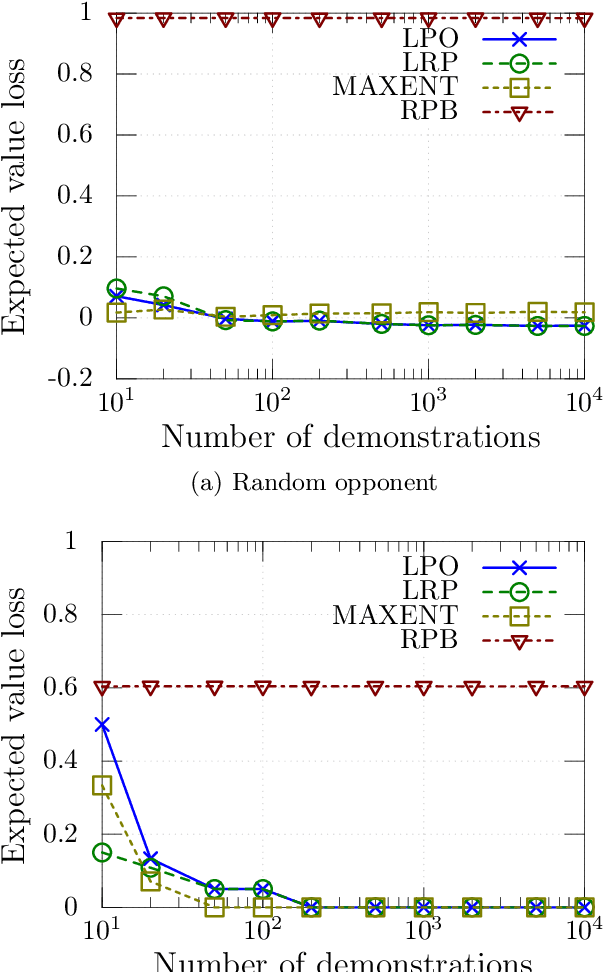
We consider the problem of learning by demonstration from agents acting in unknown stochastic Markov environments or games. Our aim is to estimate agent preferences in order to construct improved policies for the same task that the agents are trying to solve. To do so, we extend previous probabilistic approaches for inverse reinforcement learning in known MDPs to the case of unknown dynamics or opponents. We do this by deriving two simplified probabilistic models of the demonstrator's policy and utility. For tractability, we use maximum a posteriori estimation rather than full Bayesian inference. Under a flat prior, this results in a convex optimisation problem. We find that the resulting algorithms are highly competitive against a variety of other methods for inverse reinforcement learning that do have knowledge of the dynamics.
Cover Tree Bayesian Reinforcement Learning
May 02, 2014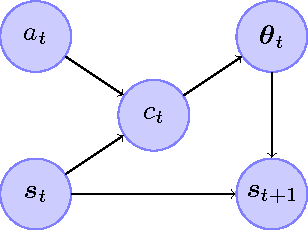
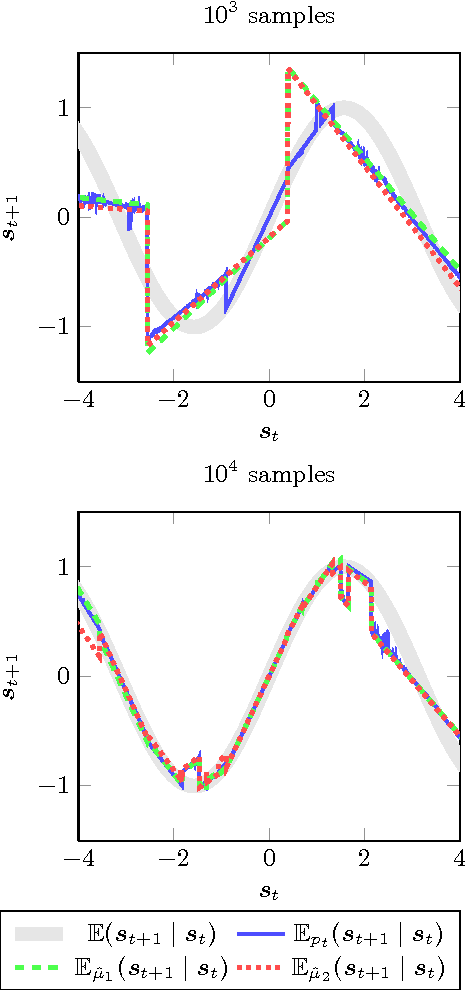
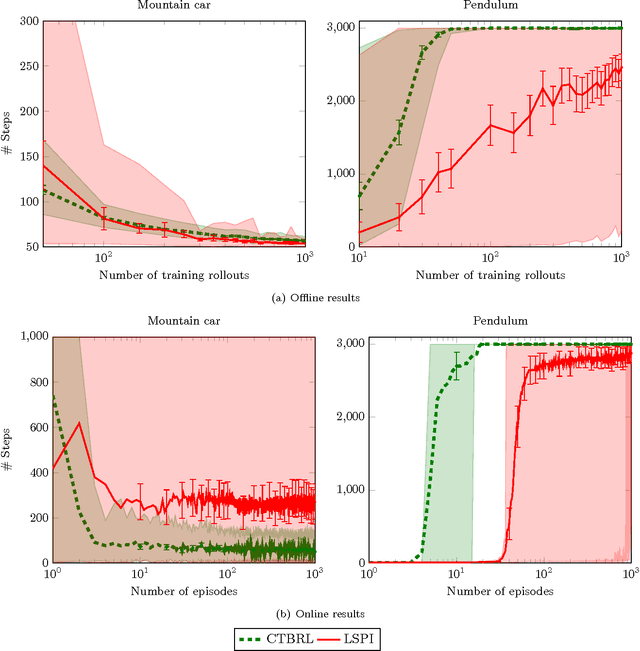
This paper proposes an online tree-based Bayesian approach for reinforcement learning. For inference, we employ a generalised context tree model. This defines a distribution on multivariate Gaussian piecewise-linear models, which can be updated in closed form. The tree structure itself is constructed using the cover tree method, which remains efficient in high dimensional spaces. We combine the model with Thompson sampling and approximate dynamic programming to obtain effective exploration policies in unknown environments. The flexibility and computational simplicity of the model render it suitable for many reinforcement learning problems in continuous state spaces. We demonstrate this in an experimental comparison with least squares policy iteration.
ABC Reinforcement Learning
Jun 28, 2013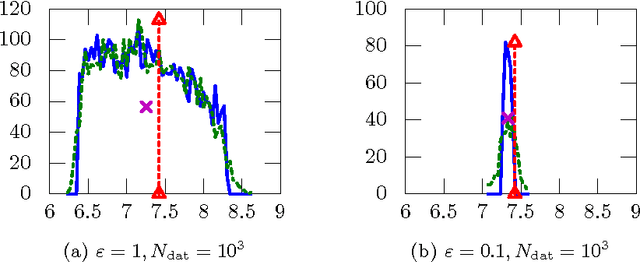
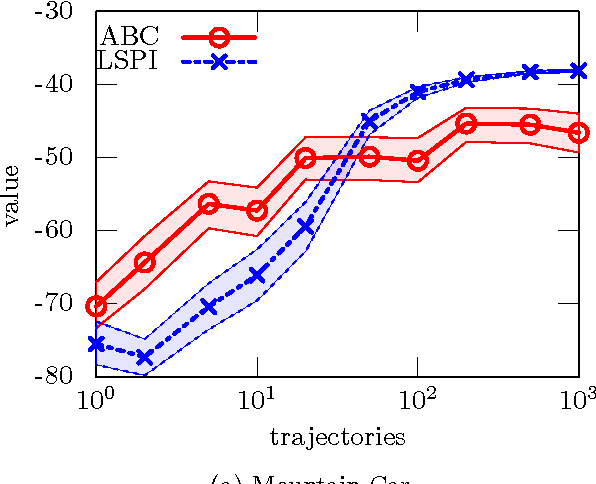
This paper introduces a simple, general framework for likelihood-free Bayesian reinforcement learning, through Approximate Bayesian Computation (ABC). The main advantage is that we only require a prior distribution on a class of simulators (generative models). This is useful in domains where an analytical probabilistic model of the underlying process is too complex to formulate, but where detailed simulation models are available. ABC-RL allows the use of any Bayesian reinforcement learning technique, even in this case. In addition, it can be seen as an extension of rollout algorithms to the case where we do not know what the correct model to draw rollouts from is. We experimentally demonstrate the potential of this approach in a comparison with LSPI. Finally, we introduce a theorem showing that ABC is a sound methodology in principle, even when non-sufficient statistics are used.