 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoment Multicalibration for Uncertainty Estimation
Aug 18, 2020We show how to achieve the notion of "multicalibration" from H\'ebert-Johnson et al. [2018] not just for means, but also for variances and other higher moments. Informally, it means that we can find regression functions which, given a data point, can make point predictions not just for the expectation of its label, but for higher moments of its label distribution as well-and those predictions match the true distribution quantities when averaged not just over the population as a whole, but also when averaged over an enormous number of finely defined subgroups. It yields a principled way to estimate the uncertainty of predictions on many different subgroups-and to diagnose potential sources of unfairness in the predictive power of features across subgroups. As an application, we show that our moment estimates can be used to derive marginal prediction intervals that are simultaneously valid as averaged over all of the (sufficiently large) subgroups for which moment multicalibration has been obtained.
Fair Prediction with Endogenous Behavior
Feb 18, 2020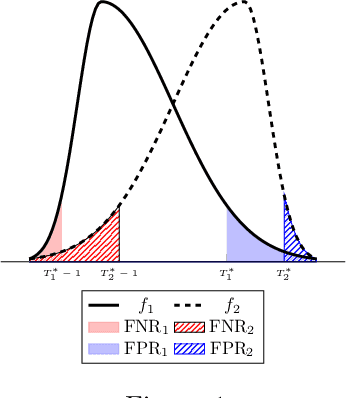
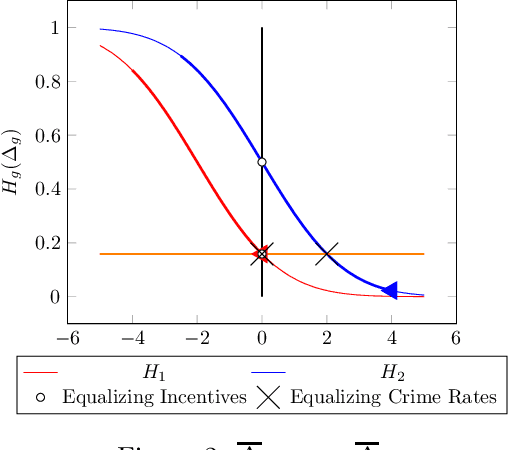
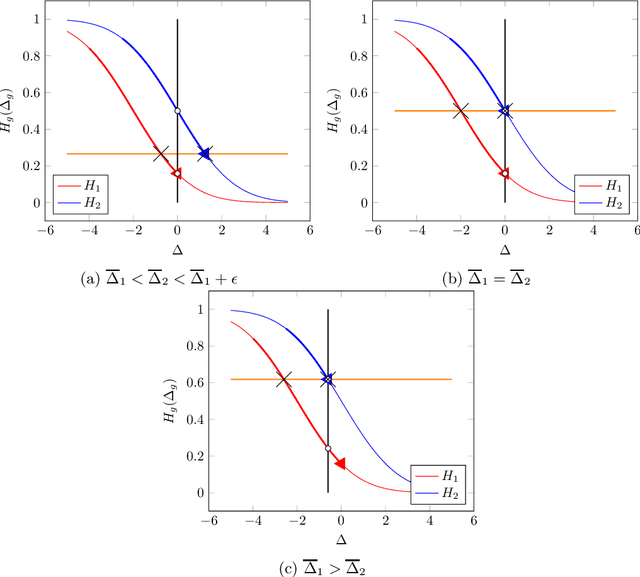
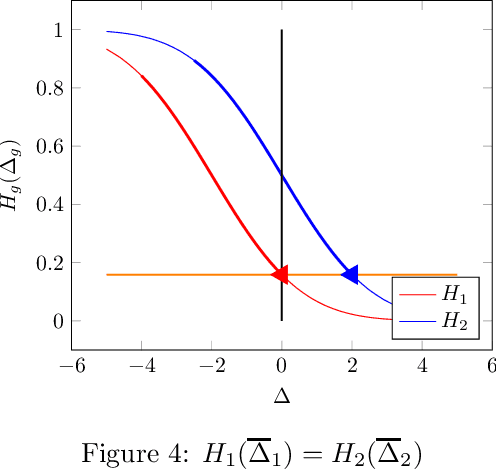
There is increasing regulatory interest in whether machine learning algorithms deployed in consequential domains (e.g. in criminal justice) treat different demographic groups "fairly." However, there are several proposed notions of fairness, typically mutually incompatible. Using criminal justice as an example, we study a model in which society chooses an incarceration rule. Agents of different demographic groups differ in their outside options (e.g. opportunity for legal employment) and decide whether to commit crimes. We show that equalizing type I and type II errors across groups is consistent with the goal of minimizing the overall crime rate; other popular notions of fairness are not.
Metric-Free Individual Fairness in Online Learning
Feb 17, 2020
We study an online learning problem subject to the constraint of individual fairness, which requires that similar individuals are treated similarly. Unlike prior work on individual fairness, we do not assume the similarity measure among individuals is known, nor do we assume that such measure takes a certain parametric form. Instead, we leverage the existence of an auditor who detects fairness violations without enunciating the quantitative measure. In each round, the auditor examines the learner's decisions and attempts to identify a pair of individuals that are treated unfairly by the learner. We provide a general reduction framework that reduces online classification in our model to standard online classification, which allows us to leverage existing online learning algorithms to achieve sub-linear regret and number of fairness violations. Surprisingly, in the stochastic setting where the data are drawn independently from a distribution, we are also able to establish PAC-style fairness and accuracy generalization guarantees (Yona and Rothblum [2018]), despite only having access to a very restricted form of fairness feedback. Our fairness generalization bound qualitatively matches the uniform convergence bound of Yona and Rothblum [2018], while also providing a meaningful accuracy generalization guarantee. Our results resolve an open question by Gillen et al. [2018] by showing that online learning under an unknown individual fairness constraint is possible even without assuming a strong parametric form of the underlying similarity measure.
A New Analysis of Differential Privacy's Generalization Guarantees
Sep 09, 2019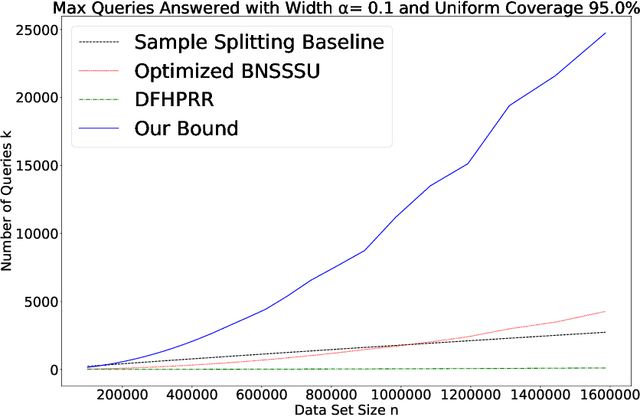
We give a new proof of the "transfer theorem" underlying adaptive data analysis: that any mechanism for answering adaptively chosen statistical queries that is differentially private and sample-accurate is also accurate out-of-sample. Our new proof is elementary and gives structural insights that we expect will be useful elsewhere. We show: 1) that differential privacy ensures that the expectation of any query on the posterior distribution on datasets induced by the transcript of the interaction is close to its true value on the data distribution, and 2) sample accuracy on its own ensures that any query answer produced by the mechanism is close to its posterior expectation with high probability. This second claim follows from a thought experiment in which we imagine that the dataset is resampled from the posterior distribution after the mechanism has committed to its answers. The transfer theorem then follows by summing these two bounds, and in particular, avoids the "monitor argument" used to derive high probability bounds in prior work. An upshot of our new proof technique is that the concrete bounds we obtain are substantially better than the best previously known bounds, even though the improvements are in the constants, rather than the asymptotics (which are known to be tight). As we show, our new bounds outperform the naive "sample-splitting" baseline at dramatically smaller dataset sizes compared to the previous state of the art, bringing techniques from this literature closer to practicality.
A Center in Your Neighborhood: Fairness in Facility Location
Aug 30, 2019
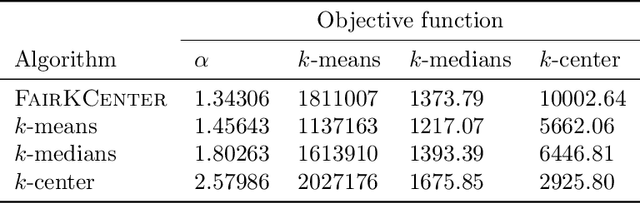
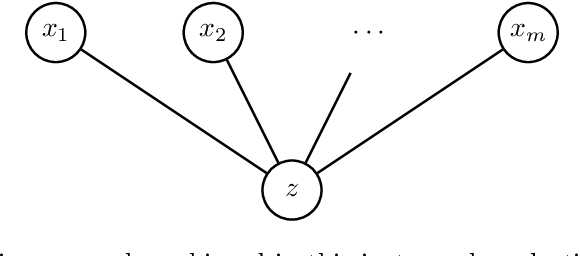
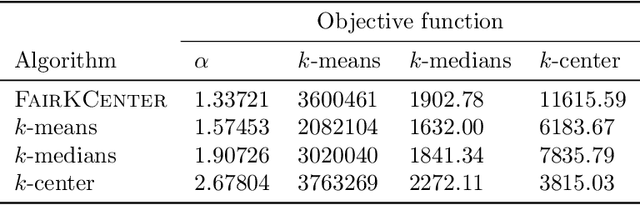
When selecting locations for a set of facilities, standard clustering algorithms may place unfair burden on some individuals and neighborhoods. We formulate a fairness concept that takes local population densities into account. In particular, given $k$ facilities to locate and a population of size $n$, we define the "neighborhood radius" of an individual $i$ as the minimum radius of a ball centered at $i$ that contains at least $n/k$ individuals. Our objective is to ensure that each individual has a facility within at most a small constant factor of her neighborhood radius. We present several theoretical results: We show that optimizing this factor is NP-hard; we give an approximation algorithm that guarantees a factor of at most 2 in all metric spaces; and we prove matching lower bounds in some metric spaces. We apply a variant of this algorithm to real-world address data, showing that it is quite different from standard clustering algorithms and outperforms them on our objective function and balances the load between facilities more evenly.
Eliciting and Enforcing Subjective Individual Fairness
May 25, 2019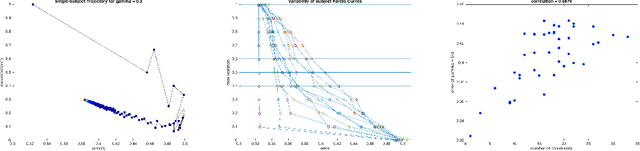
We revisit the notion of individual fairness first proposed by Dwork et al. [2012], which asks that "similar individuals should be treated similarly". A primary difficulty with this definition is that it assumes a completely specified fairness metric for the task at hand. In contrast, we consider a framework for fairness elicitation, in which fairness is indirectly specified only via a sample of pairs of individuals who should be treated (approximately) equally on the task. We make no assumption that these pairs are consistent with any metric. We provide a provably convergent oracle-efficient algorithm for minimizing error subject to the fairness constraints, and prove generalization theorems for both accuracy and fairness. Since the constrained pairs could be elicited either from a panel of judges, or from particular individuals, our framework provides a means for algorithmically enforcing subjective notions of fairness. We report on preliminary findings of a behavioral study of subjective fairness using human-subject fairness constraints elicited on the COMPAS criminal recidivism dataset.
Quantifying the Burden of Exploration and the Unfairness of Free Riding
Oct 20, 2018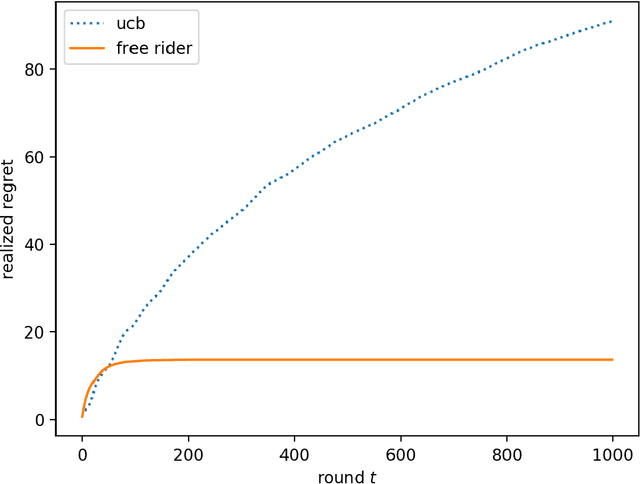
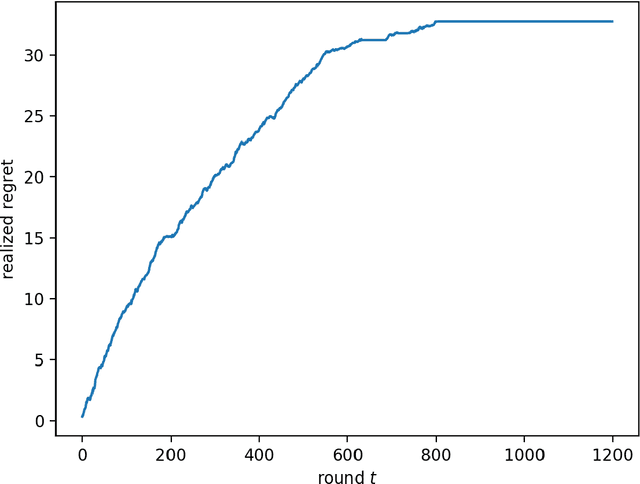
We consider the multi-armed bandit setting with a twist. Rather than having just one decision maker deciding which arm to pull in each round, we have $n$ different decision makers (agents). In the simple stochastic setting we show that one of the agents (called the free rider), who has access to the history of other agents playing some zero regret algorithm can achieve just $O(1)$ regret, as opposed to the regret lower bound of $\Omega (\log T)$ when one decision maker is playing in isolation. In the linear contextual setting, we show that if the other agents play a particular, popular zero regret algorithm (UCB), then the free rider can again achieve $O(1)$ regret. In order to prove this result, we give a deterministic lower bound on the number of times each suboptimal arm must be pulled in UCB. In contrast, we show that the free-rider cannot beat the standard single-player regret bounds in certain partial information settings.
Online Learning with an Unknown Fairness Metric
Sep 18, 2018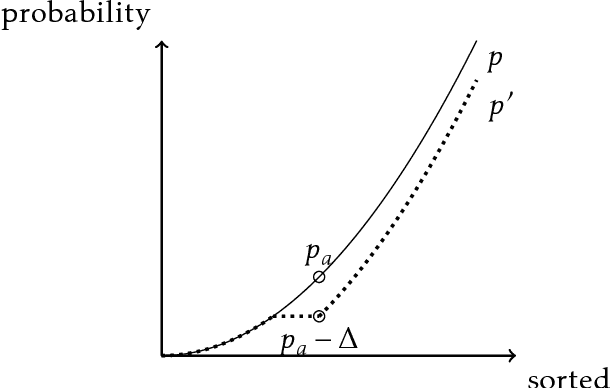
We consider the problem of online learning in the linear contextual bandits setting, but in which there are also strong individual fairness constraints governed by an unknown similarity metric. These constraints demand that we select similar actions or individuals with approximately equal probability (arXiv:1104.3913), which may be at odds with optimizing reward, thus modeling settings where profit and social policy are in tension. We assume we learn about an unknown Mahalanobis similarity metric from only weak feedback that identifies fairness violations, but does not quantify their extent. This is intended to represent the interventions of a regulator who "knows unfairness when he sees it" but nevertheless cannot enunciate a quantitative fairness metric over individuals. Our main result is an algorithm in the adversarial context setting that has a number of fairness violations that depends only logarithmically on $T$, while obtaining an optimal $O(\sqrt{T})$ regret bound to the best fair policy.
Fair Algorithms for Learning in Allocation Problems
Aug 30, 2018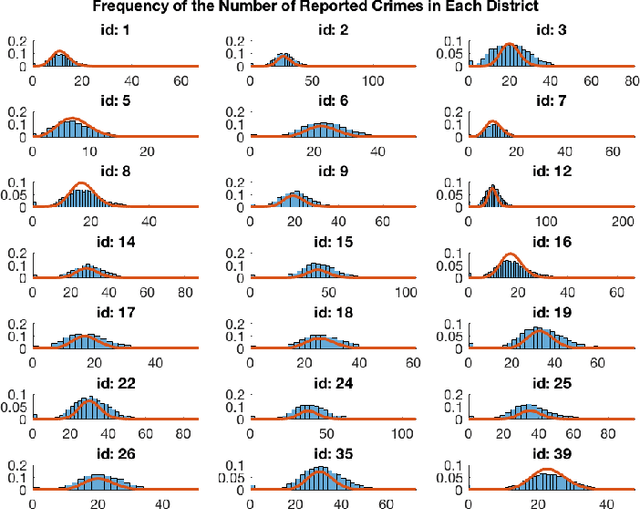
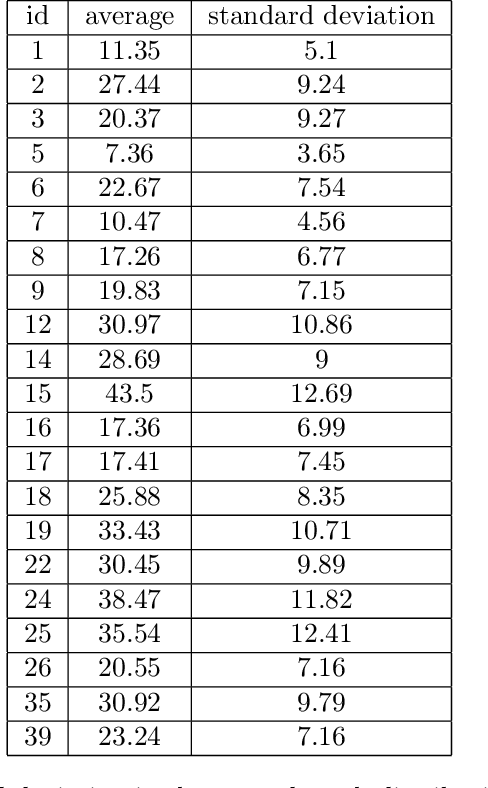
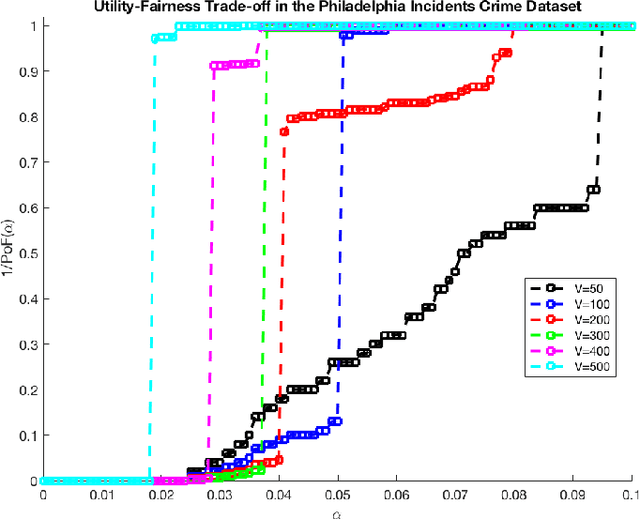
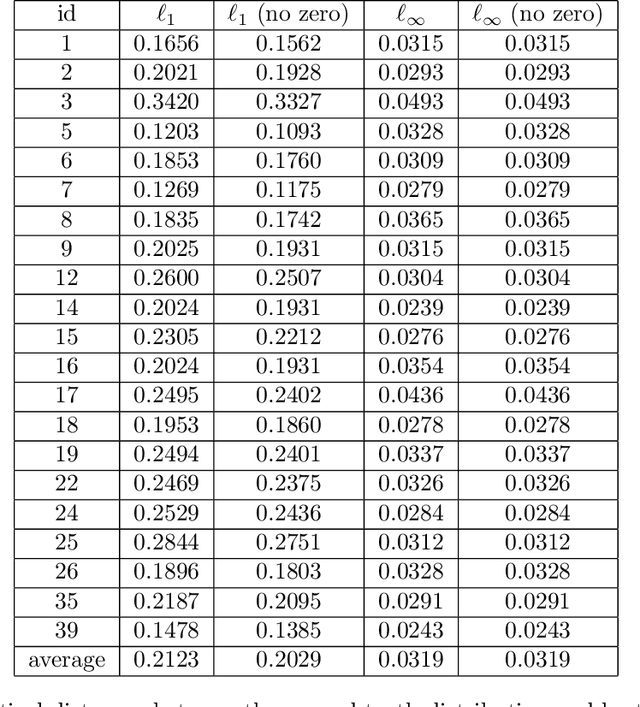
Settings such as lending and policing can be modeled by a centralized agent allocating a resource (loans or police officers) amongst several groups, in order to maximize some objective (loans given that are repaid or criminals that are apprehended). Often in such problems fairness is also a concern. A natural notion of fairness, based on general principles of equality of opportunity, asks that conditional on an individual being a candidate for the resource, the probability of actually receiving it is approximately independent of the individual's group. In lending this means that equally creditworthy individuals in different racial groups have roughly equal chances of receiving a loan. In policing it means that two individuals committing the same crime in different districts would have roughly equal chances of being arrested. We formalize this fairness notion for allocation problems and investigate its algorithmic consequences. Our main technical results include an efficient learning algorithm that converges to an optimal fair allocation even when the frequency of candidates (creditworthy individuals or criminals) in each group is unknown. The algorithm operates in a censored feedback model in which only the number of candidates who received the resource in a given allocation can be observed, rather than the true number of candidates. This models the fact that we do not learn the creditworthiness of individuals we do not give loans to nor learn about crimes committed if the police presence in a district is low. As an application of our framework, we consider the predictive policing problem. The learning algorithm is trained on arrest data gathered from its own deployments on previous days, resulting in a potential feedback loop that our algorithm provably overcomes. We empirically investigate the performance of our algorithm on the Philadelphia Crime Incidents dataset.