 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Jammer Mitigation and Data Detection for Smart, Distributed, and Multi-Antenna Jammers
Nov 14, 2022


Multi-antenna (MIMO) processing is a promising solution to the problem of jammer mitigation. Existing methods mitigate the jammer based on an estimate of its subspace (or receive statistics) acquired through a dedicated training phase. This strategy has two main drawbacks: (i) it reduces the communication rate since no data can be transmitted during the training phase and (ii) it can be evaded by smart or multi-antenna jammers that are quiet during the training phase or that dynamically change their subspace through time-varying beamforming. To address these drawbacks, we propose Joint jammer Mitigation and data Detection (JMD), a novel paradigm for MIMO jammer mitigation. The core idea is to estimate and remove the jammer interference subspace jointly with detecting the transmit data over multiple time slots. Doing so removes the need for a dedicated and rate-reducing training period while mitigating smart and dynamic multi-antenna jammers. We instantiate our paradigm with SANDMAN, a simple and practical algorithm for multi-user MIMO uplink JMD. Extensive simulations demonstrate the efficacy of JMD, and of SANDMAN in particular, for jammer mitigation.
Bit Error and Block Error Rate Training for ML-Assisted Communication
Oct 25, 2022



Even though machine learning (ML) techniques are being widely used in communications, the question of how to train communication systems has received surprisingly little attention. In this paper, we show that the commonly used binary cross-entropy (BCE) loss is a sensible choice in uncoded systems, e.g., for training ML-assisted data detectors, but may not be optimal in coded systems. We propose new loss functions targeted at minimizing the block error rate and SNR de-weighting, a novel method that trains communication systems for optimal performance over a range of signal-to-noise ratios. The utility of the proposed loss functions as well as of SNR de-weighting is shown through simulations in NVIDIA Sionna.
Mitigating Smart Jammers in Multi-User MIMO
Aug 02, 2022
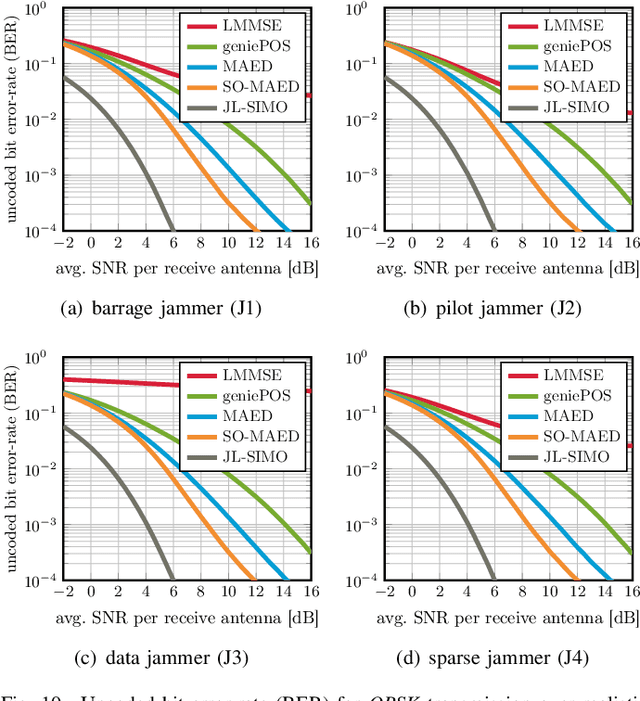
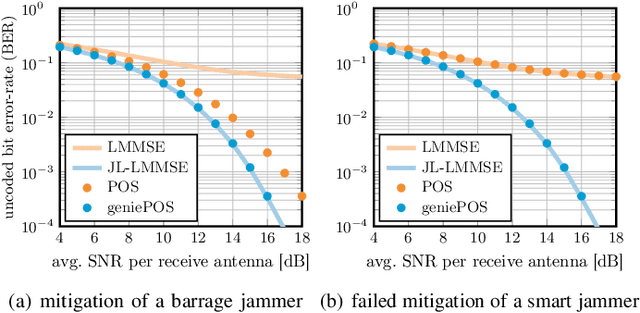
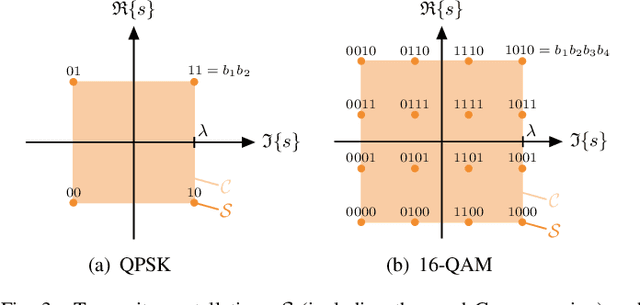
Wireless systems must be resilient to jamming attacks. Existing mitigation methods based on multi-antenna processing require knowledge of the jammer's transmit characteristics that may be difficult to acquire, especially for smart jammers that evade mitigation by transmitting only at specific instants. We propose a novel method to mitigate smart jamming attacks on the massive multi-user multiple-input multiple-output (MU-MIMO) uplink which does not require the jammer to be active at any specific instant. By formulating an optimization problem that unifies jammer estimation and mitigation, channel estimation, and data detection, we exploit that a jammer cannot change its subspace within a coherence interval. Theoretical results for our problem formulation show that its solution is guaranteed to recover the users' data symbols under certain conditions. We develop two efficient iterative algorithms for approximately solving the proposed problem formulation: MAED, a parameter-free algorithm which uses forward-backward splitting with a box symbol prior, and SO-MAED, which replaces the prior of MAED with soft-output symbol estimates that exploit the discrete transmit constellation and which uses deep unfolding to optimize algorithm parameters. We use simulations to demonstrate that the proposed algorithms effectively mitigate a wide range of smart jammers without a priori knowledge about the attack type.
Beam Alignment for the Cell-Free mmWave Massive MU-MIMO Uplink
Jul 20, 2022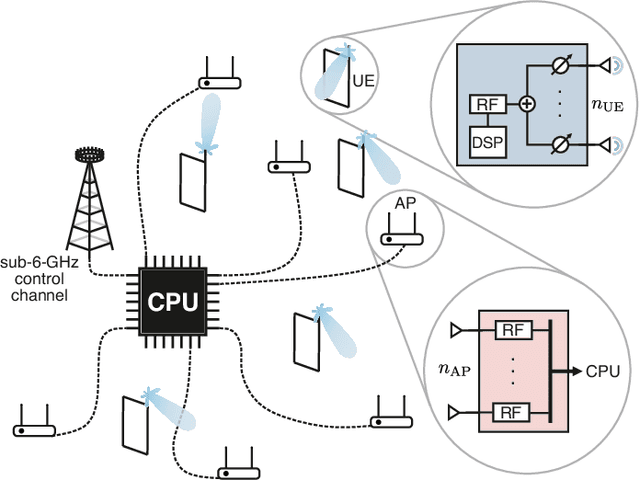
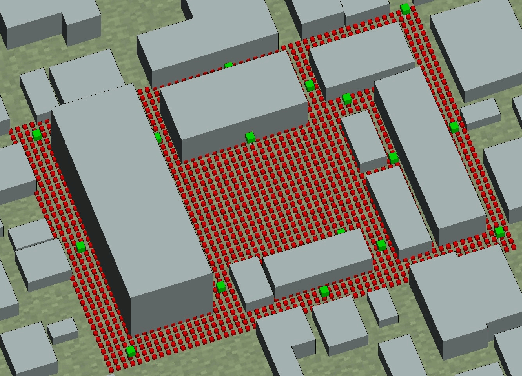
Millimeter-wave (mmWave) cell-free massive multi-user (MU) multiple-input multiple-output (MIMO) systems combine the large bandwidths available at mmWave frequencies with the improved coverage of cell-free systems. However, to combat the high path loss at mmWave frequencies, user equipments (UEs) must form beams in meaningful directions, i.e., to a nearby access point (AP). At the same time, multiple UEs should avoid transmitting to the same AP to reduce MU interference. We propose an interference-aware method for beam alignment (BA) in the cell-free mmWave massive MU-MIMO uplink. In the considered scenario, the APs perform full digital receive beamforming while the UEs perform analog transmit beamforming. We evaluate our method using realistic mmWave channels from a commercial ray-tracer, showing the superiority of the proposed method over omnidirectional transmission as well as over methods that do not take MU interference into account.
An Optimization-Based User Scheduling Framework for mmWave Massive MU-MIMO Systems
Jun 23, 2022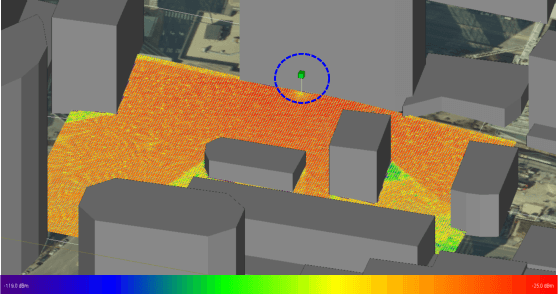
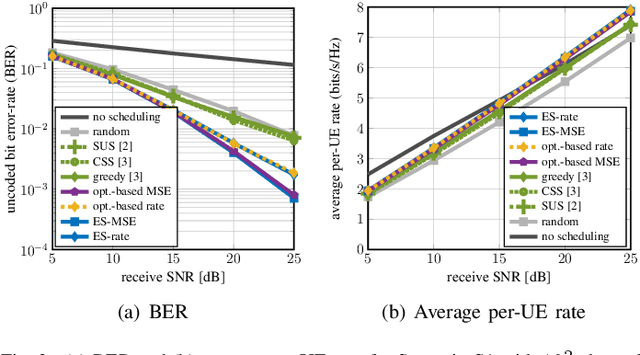
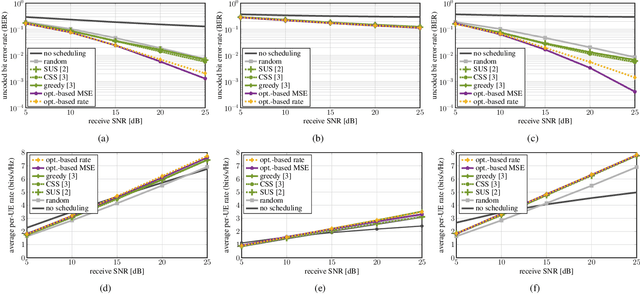
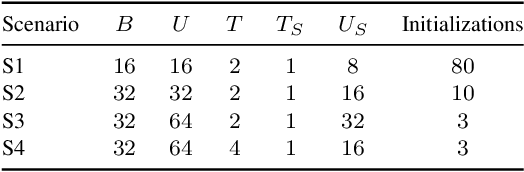
We propose a novel user equipment (UE) scheduling framework for millimeter-wave (mmWave) massive multiuser (MU) multiple-input multiple-output (MIMO) wireless systems. Our framework determines (sub)sets of UEs that should transmit simultaneously in a given time slot by approximately solving a nonconvex optimization problem using forward-backward splitting. Our UE scheduling framework is flexible in the sense that it (i) supports a variety of cost functions, including post-equalization mean square error and sum rate, and (ii) enables precise control over the minimum and maximum number of resources the UEs should occupy. We demonstrate the efficacy of our framework using realistic mmWave channel vectors generated with a commercial ray-tracer. We show that our UE scheduler outperforms a range of existing scheduling methods and closely approaches the performance of an exhaustive search.
Mitigating Smart Jammers in MU-MIMO via Joint Channel Estimation and Data Detection
Jan 21, 2022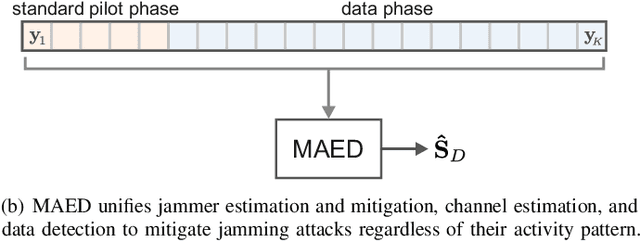
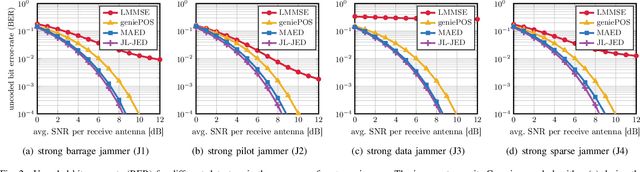
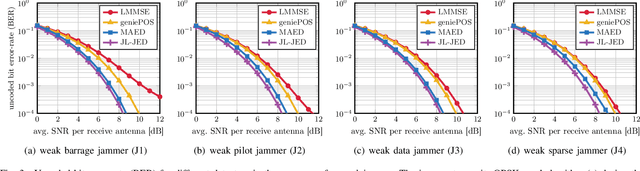
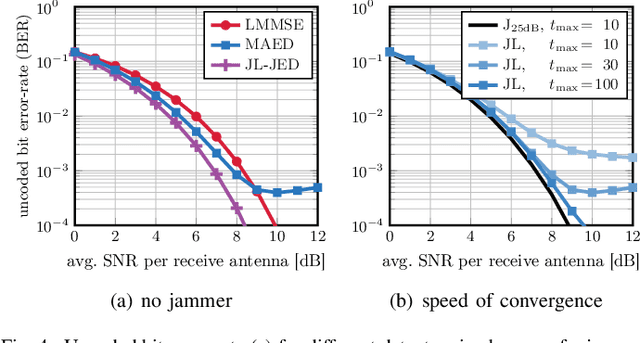
Wireless systems must be resilient to jamming attacks. Existing mitigation methods require knowledge of the jammer's transmit characteristics. However, this knowledge may be difficult to acquire, especially for smart jammers that attack only specific instants during transmission in order to evade mitigation. We propose a novel method that mitigates attacks by smart jammers on massive multi-user multiple-input multiple-output (MU-MIMO) basestations (BSs). Our approach builds on recent progress in joint channel estimation and data detection (JED) and exploits the fact that a jammer cannot change its subspace within a coherence interval. Our method, called MAED (short for MitigAtion, Estimation, and Detection), uses a novel problem formulation that combines jammer estimation and mitigation, channel estimation, and data detection, instead of separating these tasks. We solve the problem approximately with an efficient iterative algorithm. Our results show that MAED effectively mitigates a wide range of smart jamming attacks without having any a priori knowledge about the attack type.
Soft-Output Joint Channel Estimation and Data Detection using Deep Unfolding
Dec 01, 2021
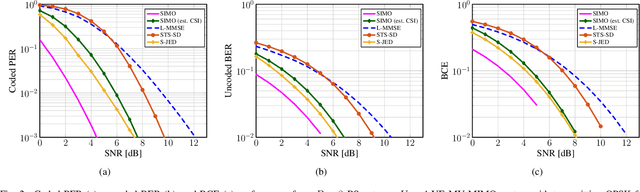
We propose a novel soft-output joint channel estimation and data detection (JED) algorithm for multiuser (MU) multiple-input multiple-output (MIMO) wireless communication systems. Our algorithm approximately solves a maximum a-posteriori JED optimization problem using deep unfolding and generates soft-output information for the transmitted bits in every iteration. The parameters of the unfolded algorithm are computed by a hyper-network that is trained with a binary cross entropy (BCE) loss. We evaluate the performance of our algorithm in a coded MU-MIMO system with 8 basestation antennas and 4 user equipments and compare it to state-of-the-art algorithms separate channel estimation from soft-output data detection. Our results demonstrate that our JED algorithm outperforms such data detectors with as few as 10 iterations.
Hybrid Jammer Mitigation for All-Digital mmWave Massive MU-MIMO
Nov 25, 2021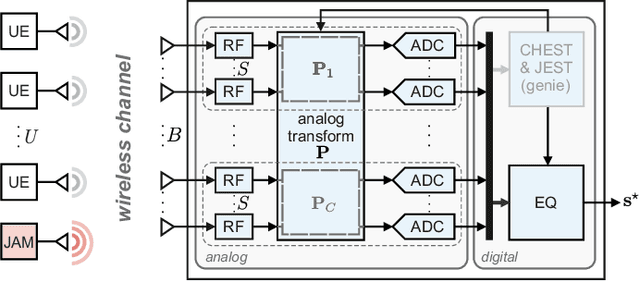
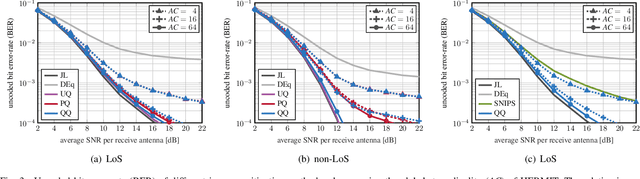
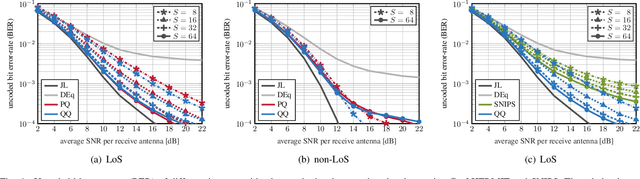
Low-resolution analog-to-digital converters (ADCs) simplify the design of millimeter-wave (mmWave) massive multi-user multiple-input multiple-output (MU-MIMO) basestations, but increase vulnerability to jamming attacks. As a remedy, we propose HERMIT (short for Hybrid jammER MITigation), a method that combines a hardware-friendly adaptive analog transform with a corresponding digital equalizer: The analog transform removes most of the jammer's energy prior to data conversion; the digital equalizer suppresses jammer residues while detecting the legitimate transmit data. We provide theoretical results that establish the optimal analog transform as a function of the user equipments' and the jammer's channels. Using simulations with mmWave channel models, we demonstrate the superiority of HERMIT compared both to purely digital jammer mitigation as well as to a recent hybrid method that mitigates jammer interference with a nonadaptive analog transform.
Joint Channel Estimation and Data Detection in Cell-Free Massive MU-MIMO Systems
Oct 29, 2021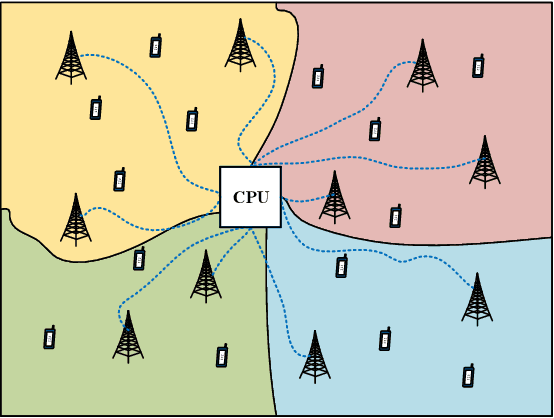
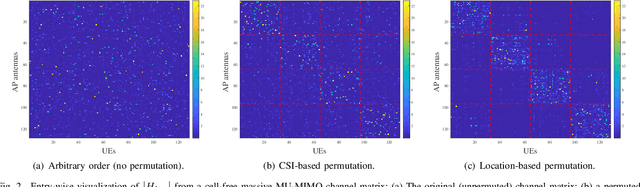
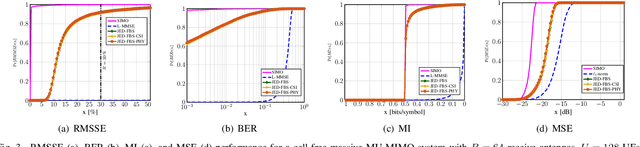
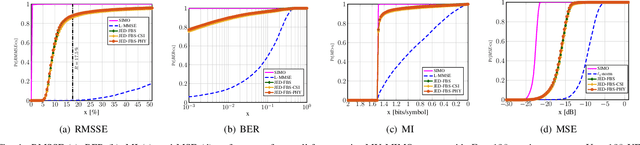
We propose a joint channel estimation and data detection (JED) algorithm for densely-populated cell-free massive multiuser (MU) multiple-input multiple-output (MIMO) systems, which reduces the channel training overhead caused by the presence of hundreds of simultaneously transmitting user equipments (UEs). Our algorithm iteratively solves a relaxed version of a maximum a-posteriori JED problem and simultaneously exploits the sparsity of cell-free massive MU-MIMO channels as well as the boundedness of QAM constellations. In order to improve the performance and convergence of the algorithm, we propose methods that permute the access point and UE indices to form so-called virtual cells, which leads to better initial solutions. We assess the performance of our algorithm in terms of root-mean-squared-symbol error, bit error rate, and mutual information, and we demonstrate that JED significantly reduces the pilot overhead compared to orthogonal training, which enables reliable communication with short packets to a large number of UEs.
Feature Learning for Neural-Network-Based Positioning with Channel State Information
Oct 28, 2021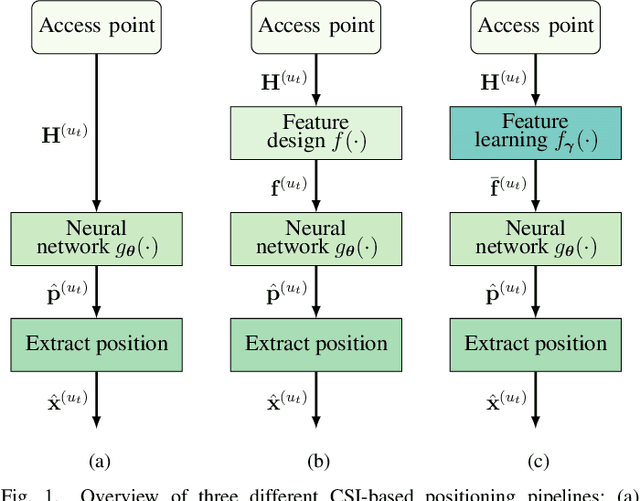
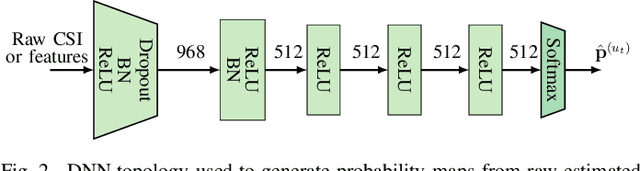
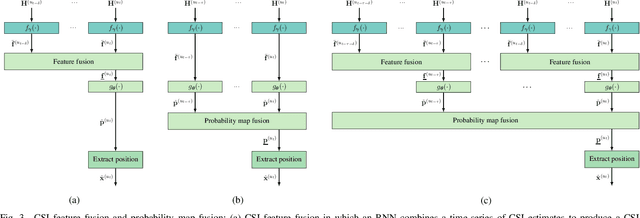
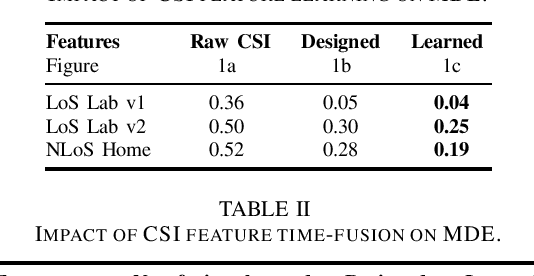
Recent channel state information (CSI)-based positioning pipelines rely on deep neural networks (DNNs) in order to learn a mapping from estimated CSI to position. Since real-world communication transceivers suffer from hardware impairments, CSI-based positioning systems typically rely on features that are designed by hand. In this paper, we propose a CSI-based positioning pipeline that directly takes raw CSI measurements and learns features using a structured DNN in order to generate probability maps describing the likelihood of the transmitter being at pre-defined grid points. To further improve the positioning accuracy of moving user equipments, we propose to fuse a time-series of learned CSI features or a time-series of probability maps. To demonstrate the efficacy of our methods, we perform experiments with real-world indoor line-of-sight (LoS) and non-LoS channel measurements. We show that CSI feature learning and time-series fusion can reduce the mean distance error by up to 2.5$\boldsymbol\times$ compared to the state-of-the-art.