 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy the noise model matters: A performance gap in learned regularization
Oct 14, 2025This article addresses the challenge of learning effective regularizers for linear inverse problems. We analyze and compare several types of learned variational regularization against the theoretical benchmark of the optimal affine reconstruction, i.e. the best possible affine linear map for minimizing the mean squared error. It is known that this optimal reconstruction can be achieved using Tikhonov regularization, but this requires precise knowledge of the noise covariance to properly weight the data fidelity term. However, in many practical applications, noise statistics are unknown. We therefore investigate the performance of regularization methods learned without access to this noise information, focusing on Tikhonov, Lavrentiev, and quadratic regularization. Our theoretical analysis and numerical experiments demonstrate that for non-white noise, a performance gap emerges between these methods and the optimal affine reconstruction. Furthermore, we show that these different types of regularization yield distinct results, highlighting that the choice of regularizer structure is critical when the noise model is not explicitly learned. Our findings underscore the significant value of accurately modeling or co-learning noise statistics in data-driven regularization.
Learning Variational Models with Unrolling and Bilevel Optimization
Sep 27, 2022

In this paper we consider the problem learning of variational models in the context of supervised learning via risk minimization. Our goal is to provide a deeper understanding of the two approaches of learning of variational models via bilevel optimization and via algorithm unrolling. The former considers the variational model as a lower level optimization problem below the risk minimization problem, while the latter replaces the lower level optimization problem by an algorithm that solves said problem approximately. Both approaches are used in practice, but, unrolling is much simpler from a computational point of view. To analyze and compare the two approaches, we consider a simple toy model, and compute all risks and the respective estimators explicitly. We show that unrolling can be better than the bilevel optimization approach, but also that the performance of unrolling can depend significantly on further parameters, sometimes in unexpected ways: While the stepsize of the unrolled algorithm matters a lot, the number of unrolled iterations only matters if the number is even or odd, and these two cases are notably different.
Primal-dual residual networks
Jun 15, 2018



In this work, we propose a deep neural network architecture motivated by primal-dual splitting methods from convex optimization. We show theoretically that there exists a close relation between the derived architecture and residual networks, and further investigate this connection in numerical experiments. Moreover, we demonstrate how our approach can be used to unroll optimization algorithms for certain problems with hard constraints. Using the example of speech dequantization, we show that our method can outperform classical splitting methods when both are applied to the same task.
A Sinkhorn-Newton method for entropic optimal transport
Feb 09, 2018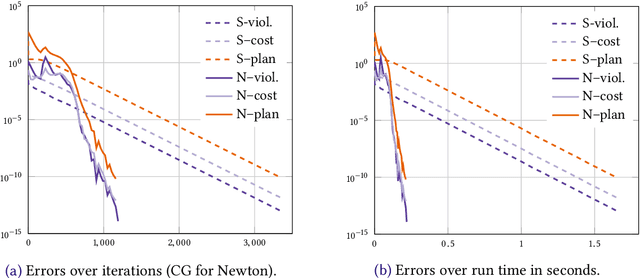
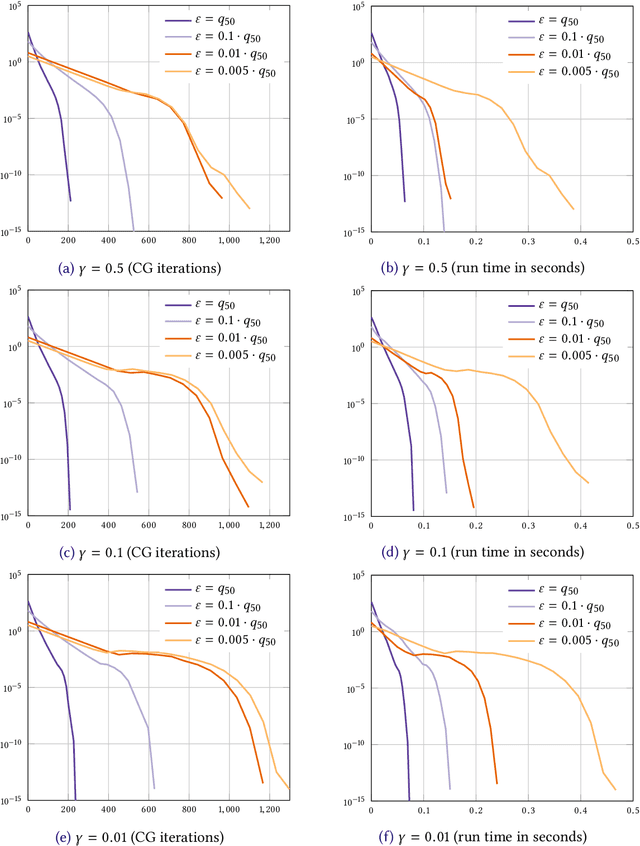
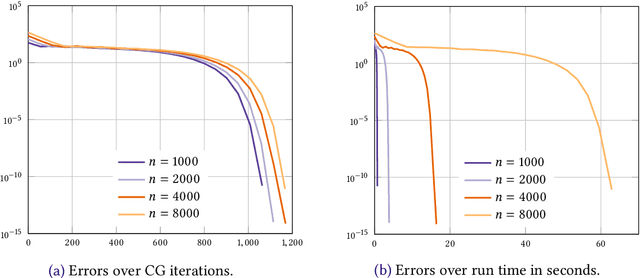
We consider the entropic regularization of discretized optimal transport and propose to solve its optimality conditions via a logarithmic Newton iteration. We show a quadratic convergence rate and validate numerically that the method compares favorably with the more commonly used Sinkhorn--Knopp algorithm for small regularization strength. We further investigate numerically the robustness of the proposed method with respect to parameters such as the mesh size of the discretization.