 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Networks in Linguistic Theory: Revisiting Pinker and Prince (1988) and the Past Tense Debate
Jul 12, 2018Can advances in NLP help advance cognitive modeling? We examine the role of artificial neural networks, the current state of the art in many common NLP tasks, by returning to a classic case study. In 1986, Rumelhart and McClelland famously introduced a neural architecture that learned to transduce English verb stems to their past tense forms. Shortly thereafter, Pinker & Prince (1988) presented a comprehensive rebuttal of many of Rumelhart and McClelland's claims. Much of the force of their attack centered on the empirical inadequacy of the Rumelhart and McClelland (1986) model. Today, however, that model is severely outmoded. We show that the Encoder-Decoder network architectures used in modern NLP systems obviate most of Pinker and Prince's criticisms without requiring any simplication of the past tense mapping problem. We suggest that the empirical performance of modern networks warrants a re-examination of their utility in linguistic and cognitive modeling.
On the Complexity and Typology of Inflectional Morphological Systems
Jul 08, 2018We quantify the linguistic complexity of different languages' morphological systems. We verify that there is an empirical trade-off between paradigm size and irregularity: a language's inflectional paradigms may be either large in size or highly irregular, but never both. Our methodology measures paradigm irregularity as the entropy of the surface realization of a paradigm -- how hard it is to jointly predict all the surface forms of a paradigm. We estimate this by a variational approximation. Our measurements are taken on large morphological paradigms from 31 typologically diverse languages.
Unsupervised Disambiguation of Syncretism in Inflected Lexicons
Jun 10, 2018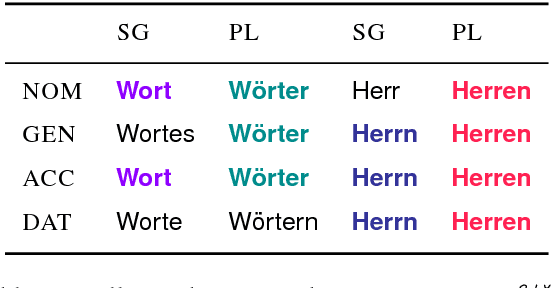
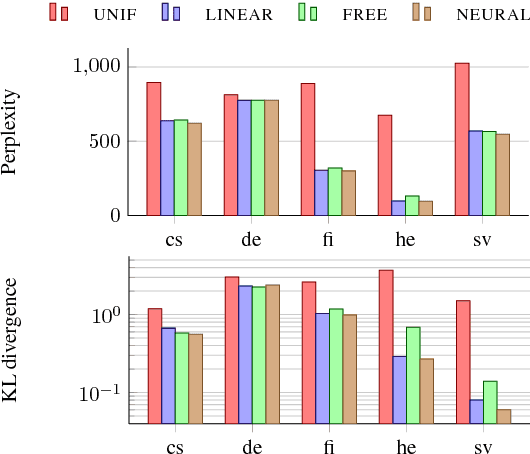
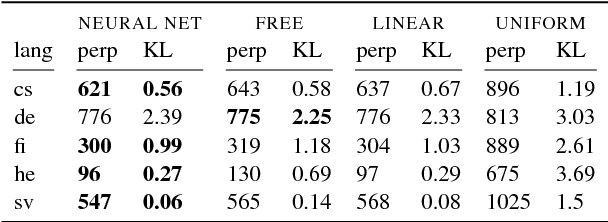
Lexical ambiguity makes it difficult to compute various useful statistics of a corpus. A given word form might represent any of several morphological feature bundles. One can, however, use unsupervised learning (as in EM) to fit a model that probabilistically disambiguates word forms. We present such an approach, which employs a neural network to smoothly model a prior distribution over feature bundles (even rare ones). Although this basic model does not consider a token's context, that very property allows it to operate on a simple list of unigram type counts, partitioning each count among different analyses of that unigram. We discuss evaluation metrics for this novel task and report results on 5 languages.
On the Diachronic Stability of Irregularity in Inflectional Morphology
Apr 23, 2018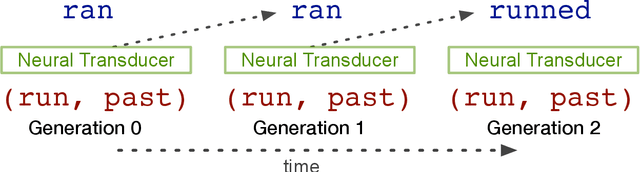
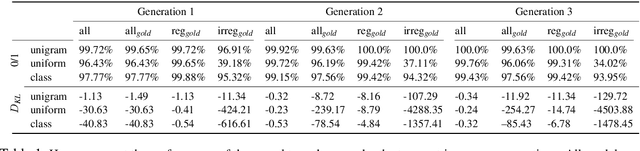
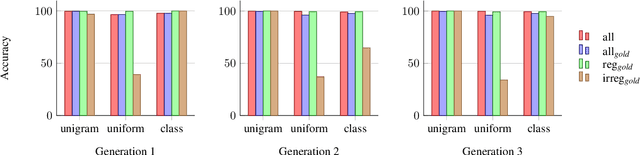
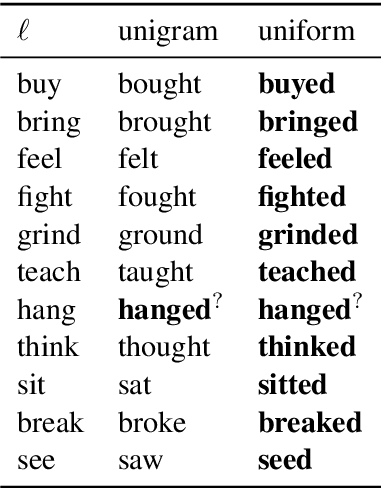
Many languages' inflectional morphological systems are replete with irregulars, i.e., words that do not seem to follow standard inflectional rules. In this work, we quantitatively investigate the conditions under which irregulars can survive in a language over the course of time. Using recurrent neural networks to simulate language learners, we test the diachronic relation between frequency of words and their irregularity.
Paradigm Completion for Derivational Morphology
Aug 30, 2017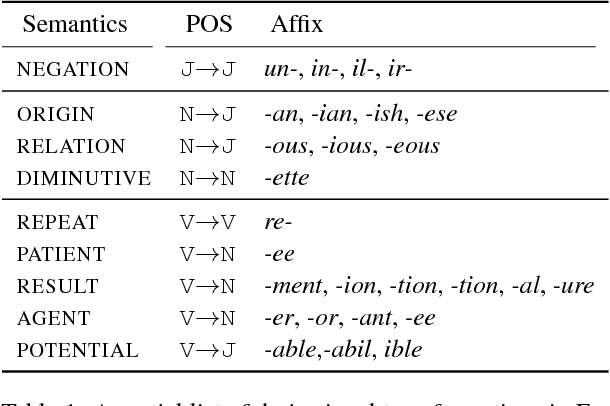
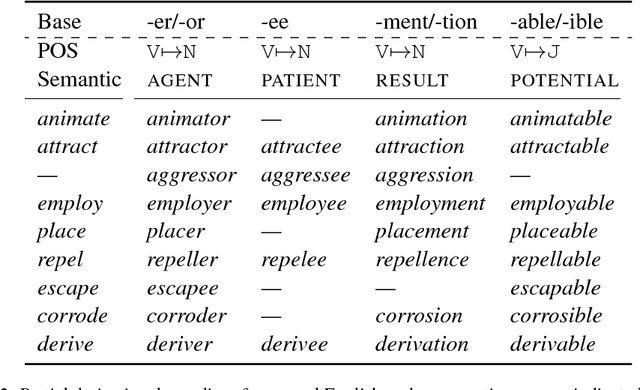
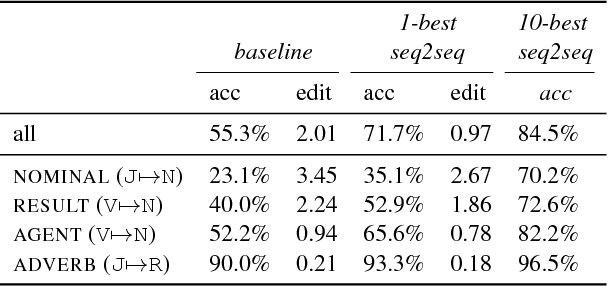
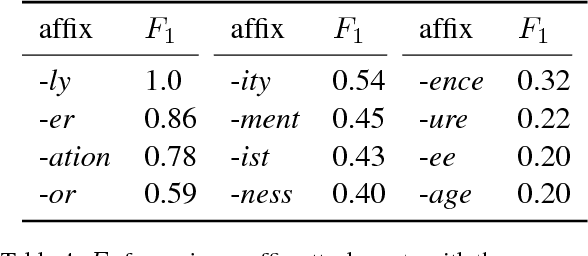
The generation of complex derived word forms has been an overlooked problem in NLP; we fill this gap by applying neural sequence-to-sequence models to the task. We overview the theoretical motivation for a paradigmatic treatment of derivational morphology, and introduce the task of derivational paradigm completion as a parallel to inflectional paradigm completion. State-of-the-art neural models, adapted from the inflection task, are able to learn a range of derivation patterns, and outperform a non-neural baseline by 16.4%. However, due to semantic, historical, and lexical considerations involved in derivational morphology, future work will be needed to achieve performance parity with inflection-generating systems.
CoNLL-SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection in 52 Languages
Jul 04, 2017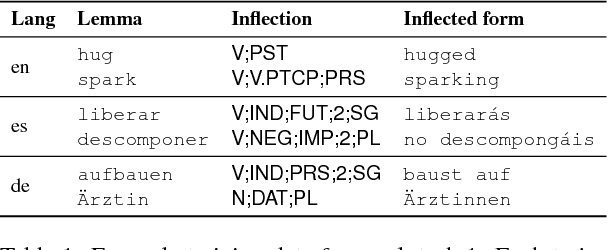
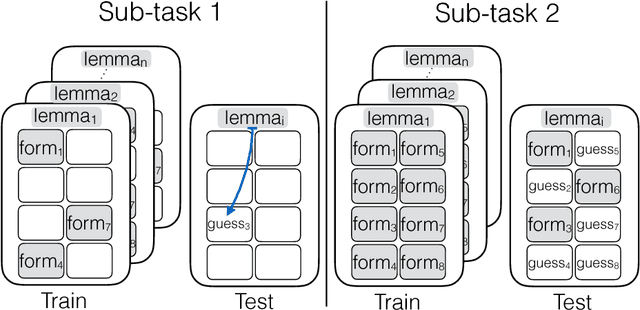
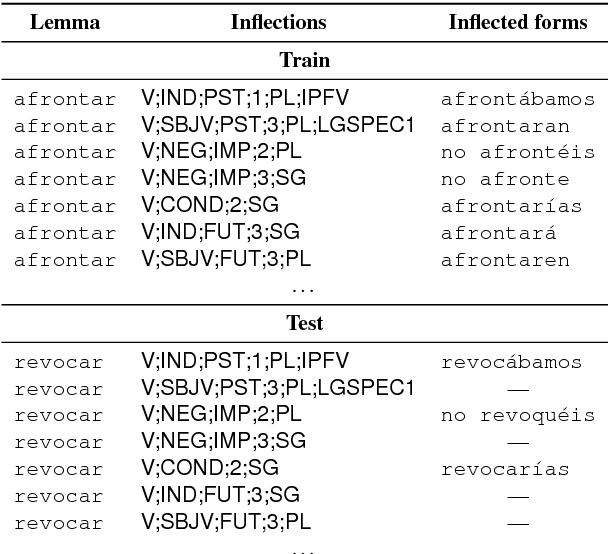
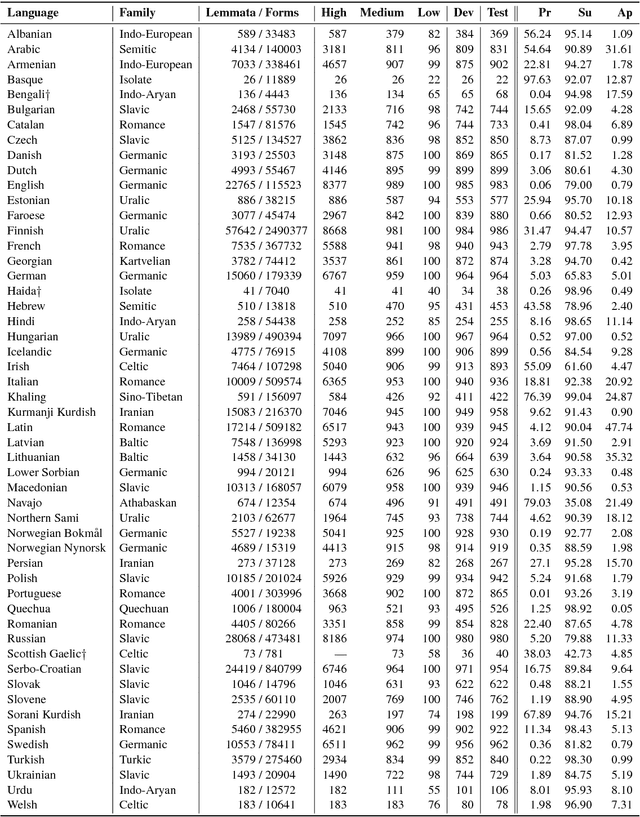
The CoNLL-SIGMORPHON 2017 shared task on supervised morphological generation required systems to be trained and tested in each of 52 typologically diverse languages. In sub-task 1, submitted systems were asked to predict a specific inflected form of a given lemma. In sub-task 2, systems were given a lemma and some of its specific inflected forms, and asked to complete the inflectional paradigm by predicting all of the remaining inflected forms. Both sub-tasks included high, medium, and low-resource conditions. Sub-task 1 received 24 system submissions, while sub-task 2 received 3 system submissions. Following the success of neural sequence-to-sequence models in the SIGMORPHON 2016 shared task, all but one of the submissions included a neural component. The results show that high performance can be achieved with small training datasets, so long as models have appropriate inductive bias or make use of additional unlabeled data or synthetic data. However, different biasing and data augmentation resulted in disjoint sets of inflected forms being predicted correctly, suggesting that there is room for future improvement.