 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Approach for Scheduling in mmWave Networks
Aug 01, 2021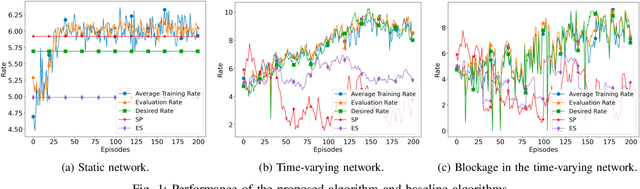
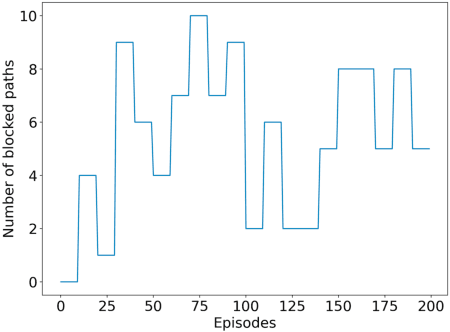
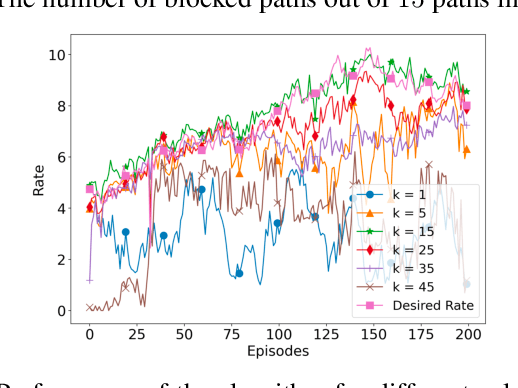
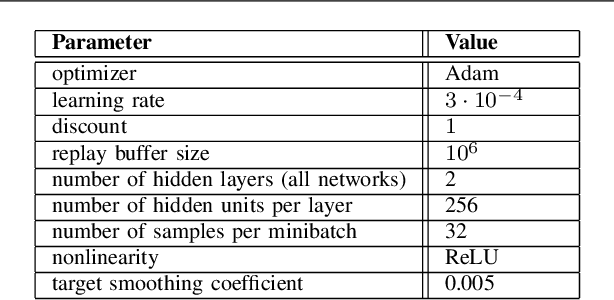
We consider a source that wishes to communicate with a destination at a desired rate, over a mmWave network where links are subject to blockage and nodes to failure (e.g., in a hostile military environment). To achieve resilience to link and node failures, we here explore a state-of-the-art Soft Actor-Critic (SAC) deep reinforcement learning algorithm, that adapts the information flow through the network, without using knowledge of the link capacities or network topology. Numerical evaluations show that our algorithm can achieve the desired rate even in dynamic environments and it is robust against blockage.
Quantizing data for distributed learning
Dec 14, 2020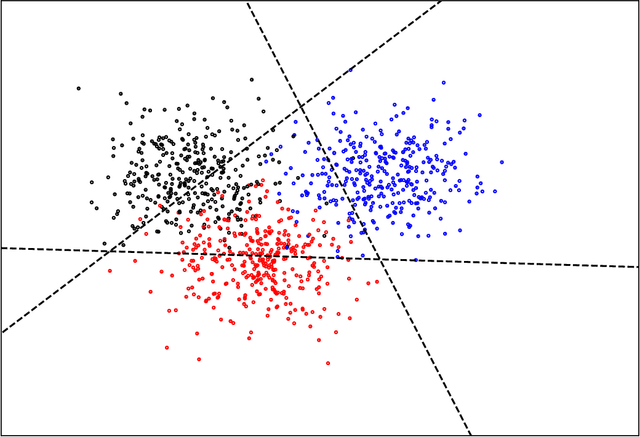
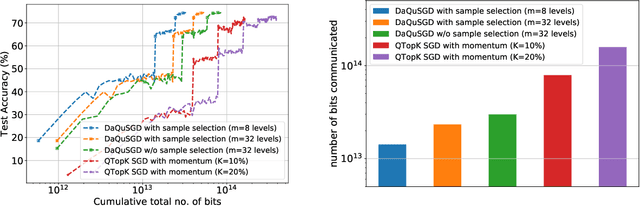
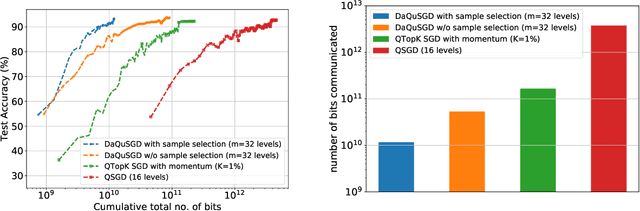
We consider machine learning applications that train a model by leveraging data distributed over a network, where communication constraints can create a performance bottleneck. A number of recent approaches are proposing to overcome this bottleneck through compression of gradient updates. However, as models become larger, so does the size of the gradient updates. In this paper, we propose an alternate approach, that quantizes data instead of gradients, and can support learning over applications where the size of gradient updates is prohibitive. Our approach combines aspects of: (1) sample selection; (2) dataset quantization; and (3) gradient compensation. We analyze the convergence of the proposed approach for smooth convex and non-convex objective functions and show that we can achieve order optimal convergence rates with communication that mostly depends on the data rather than the model (gradient) dimension. We use our proposed algorithm to train ResNet models on the CIFAR-10 and ImageNet datasets, and show that we can achieve an order of magnitude savings over gradient compression methods.
Successive Refinement of Privacy
May 24, 2020

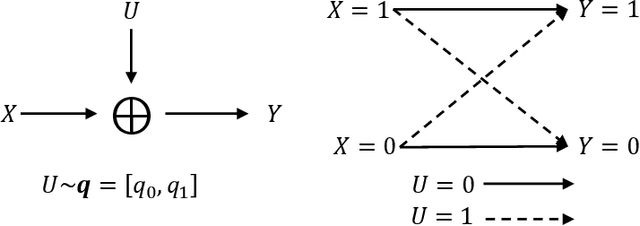
This work examines a novel question: how much randomness is needed to achieve local differential privacy (LDP)? A motivating scenario is providing {\em multiple levels of privacy} to multiple analysts, either for distribution or for heavy-hitter estimation, using the \emph{same} (randomized) output. We call this setting \emph{successive refinement of privacy}, as it provides hierarchical access to the raw data with different privacy levels. For example, the same randomized output could enable one analyst to reconstruct the input, while another can only estimate the distribution subject to LDP requirements. This extends the classical Shannon (wiretap) security setting to local differential privacy. We provide (order-wise) tight characterizations of privacy-utility-randomness trade-offs in several cases for distribution estimation, including the standard LDP setting under a randomness constraint. We also provide a non-trivial privacy mechanism for multi-level privacy. Furthermore, we show that we cannot reuse random keys over time while preserving privacy of each user.
Federated Recommendation System via Differential Privacy
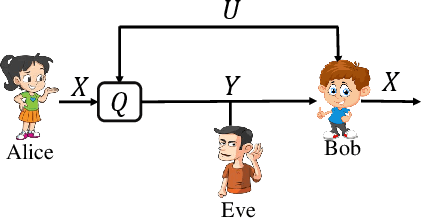
May 16, 2020
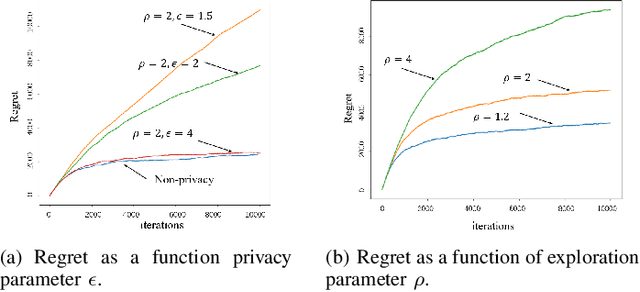
In this paper, we are interested in what we term the federated private bandits framework, that combines differential privacy with multi-agent bandit learning. We explore how differential privacy based Upper Confidence Bound (UCB) methods can be applied to multi-agent environments, and in particular to federated learning environments both in `master-worker' and `fully decentralized' settings. We provide a theoretical analysis on the privacy and regret performance of the proposed methods and explore the tradeoffs between these two.
On Distributed Quantization for Classification
Nov 01, 2019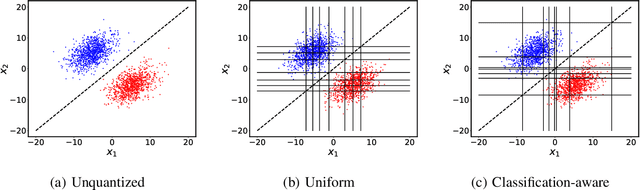
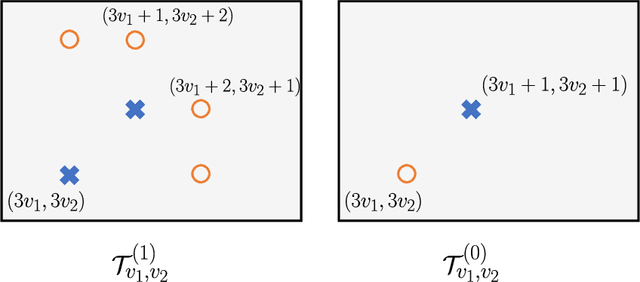
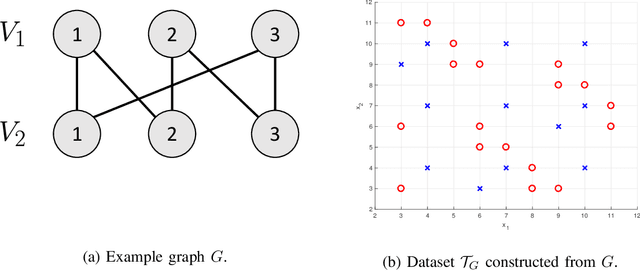
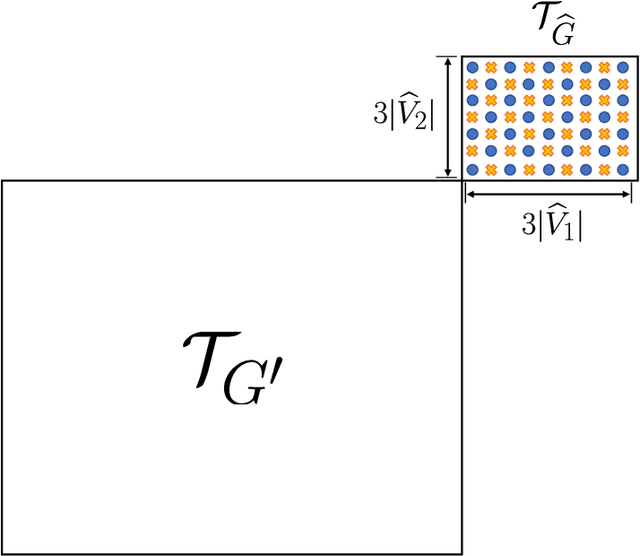
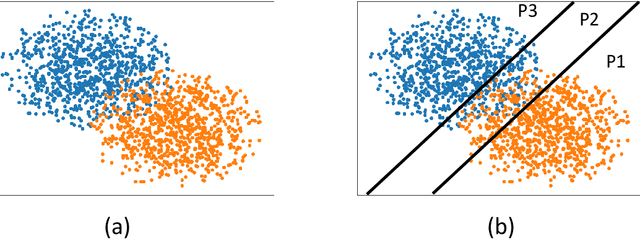
We consider the problem of distributed feature quantization, where the goal is to enable a pretrained classifier at a central node to carry out its classification on features that are gathered from distributed nodes through communication constrained channels. We propose the design of distributed quantization schemes specifically tailored to the classification task: unlike quantization schemes that help the central node reconstruct the original signal as accurately as possible, our focus is not reconstruction accuracy, but instead correct classification. Our work does not make any apriori distributional assumptions on the data, but instead uses training data for the quantizer design. Our main contributions include: we prove NP-hardness of finding optimal quantizers in the general case; we design an optimal scheme for a special case; we propose quantization algorithms, that leverage discrete neural representations and training data, and can be designed in polynomial-time for any number of features, any number of classes, and arbitrary division of features across the distributed nodes. We find that tailoring the quantizers to the classification task can offer significant savings: as compared to alternatives, we can achieve more than a factor of two reduction in terms of the number of bits communicated, for the same classification accuracy.
Regret vs. Bandwidth Trade-off for Recommendation Systems
Oct 15, 2018
We consider recommendation systems that need to operate under wireless bandwidth constraints, measured as number of broadcast transmissions, and demonstrate a (tight for some instances) tradeoff between regret and bandwidth for two scenarios: the case of multi-armed bandit with context, and the case where there is a latent structure in the message space that we can exploit to reduce the learning phase.