 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyper-Hue and EMAP on Hyperspectral Images for Supervised Layer Decomposition of Old Master Drawings
May 28, 2018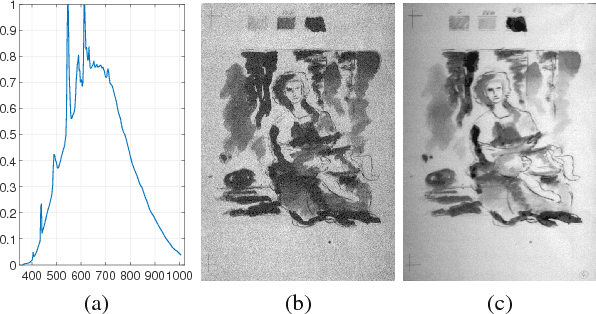



Old master drawings were mostly created step by step in several layers using different materials. To art historians and restorers, examination of these layers brings various insights into the artistic work process and helps to answer questions about the object, its attribution and its authenticity. However, these layers typically overlap and are oftentimes difficult to differentiate with the unaided eye. For example, a common layer combination is red chalk under ink. In this work, we propose an image processing pipeline that operates on hyperspectral images to separate such layers. Using this pipeline, we show that hyperspectral images enable better layer separation than RGB images, and that spectral focus stacking aids the layer separation. In particular, we propose to use two descriptors in hyperspectral historical document analysis, namely hyper-hue and extended multi-attribute profile (EMAP). Our comparative results with other features underline the efficacy of the three proposed improvements.
Adaptive Quantile Sparse Image (AQuaSI) Prior for Inverse Imaging Problems
Apr 06, 2018



Inverse problems play a central role for many classical computer vision and image processing tasks. A key challenge in solving an inverse problem is to find an appropriate prior to convert an ill-posed problem into a well-posed task. Many of the existing priors, like total variation, are based on ad-hoc assumptions that have difficulties to represent the actual distribution of natural images. In this work, we propose the Adaptive Quantile Sparse Image (AQuaSI) prior. It is based on a quantile filter, can be used as a joint filter on guidance data, and be readily plugged into a wide range of numerical optimization algorithms. We demonstrate the efficacy of the proposed prior in joint RGB/depth upsampling, on RGB/NIR image restoration, and in a comparison with related regularization by denoising approaches.
FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces
Mar 24, 2018

With recent advances in computer vision and graphics, it is now possible to generate videos with extremely realistic synthetic faces, even in real time. Countless applications are possible, some of which raise a legitimate alarm, calling for reliable detectors of fake videos. In fact, distinguishing between original and manipulated video can be a challenge for humans and computers alike, especially when the videos are compressed or have low resolution, as it often happens on social networks. Research on the detection of face manipulations has been seriously hampered by the lack of adequate datasets. To this end, we introduce a novel face manipulation dataset of about half a million edited images (from over 1000 videos). The manipulations have been generated with a state-of-the-art face editing approach. It exceeds all existing video manipulation datasets by at least an order of magnitude. Using our new dataset, we introduce benchmarks for classical image forensic tasks, including classification and segmentation, considering videos compressed at various quality levels. In addition, we introduce a benchmark evaluation for creating indistinguishable forgeries with known ground truth; for instance with generative refinement models.
GMM-Based Synthetic Samples for Classification of Hyperspectral Images With Limited Training Data
Dec 13, 2017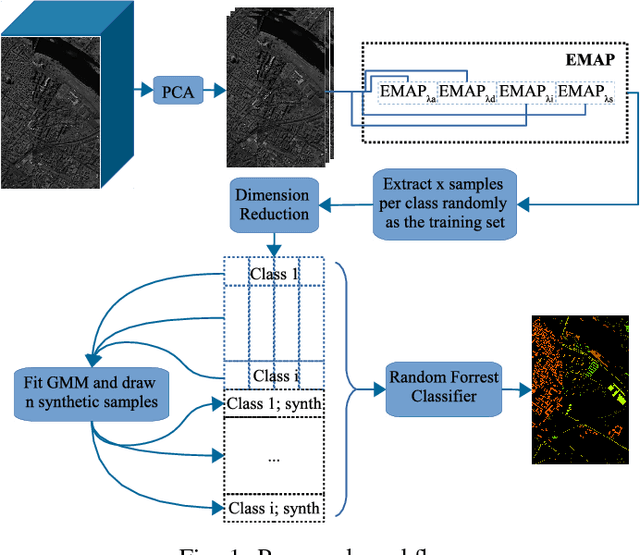
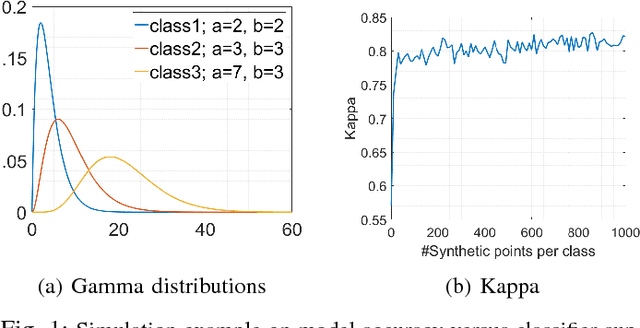
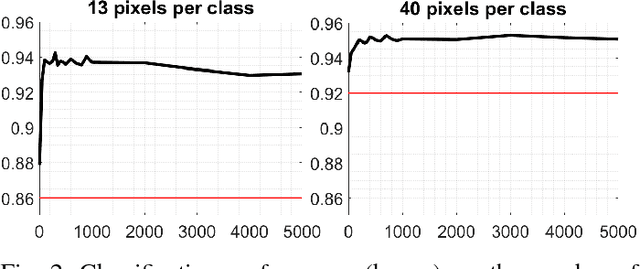
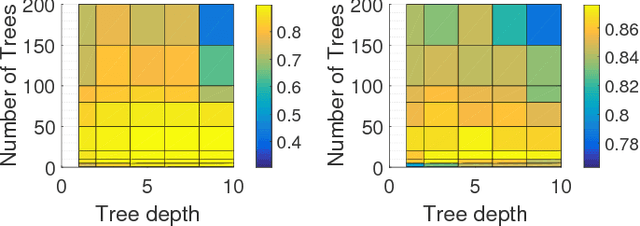
The amount of training data that is required to train a classifier scales with the dimensionality of the feature data. In hyperspectral remote sensing, feature data can potentially become very high dimensional. However, the amount of training data is oftentimes limited. Thus, one of the core challenges in hyperspectral remote sensing is how to perform multi-class classification using only relatively few training data points. In this work, we address this issue by enriching the feature matrix with synthetically generated sample points. This synthetic data is sampled from a GMM fitted to each class of the limited training data. Although, the true distribution of features may not be perfectly modeled by the fitted GMM, we demonstrate that a moderate augmentation by these synthetic samples can effectively replace a part of the missing training samples. We show the efficacy of the proposed approach on two hyperspectral datasets. The median gain in classification performance is $5\%$. It is also encouraging that this performance gain is remarkably stable for large variations in the number of added samples, which makes it much easier to apply this method to real-world applications.
Image Registration for the Alignment of Digitized Historical Documents
Dec 12, 2017

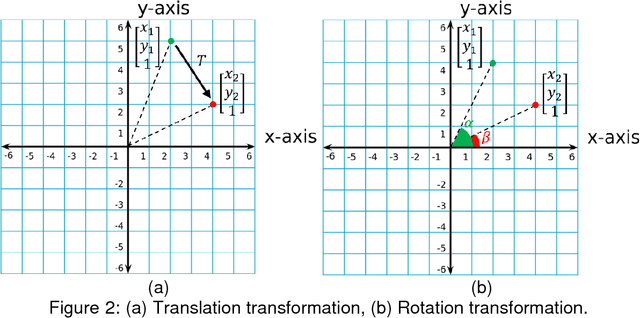

In this work, we conducted a survey on different registration algorithms and investigated their suitability for hyperspectral historical image registration applications. After the evaluation of different algorithms, we choose an intensity based registration algorithm with a curved transformation model. For the transformation model, we select cubic B-splines since they should be capable to cope with all non-rigid deformations in our hyperspectral images. From a number of similarity measures, we found that residual complexity and localized mutual information are well suited for the task at hand. In our evaluation, both measures show an acceptable performance in handling all difficulties, e.g., capture range, non-stationary and spatially varying intensity distortions or multi-modality that occur in our application.
Sketch Layer Separation in Multi-Spectral Historical Document Images
Dec 10, 2017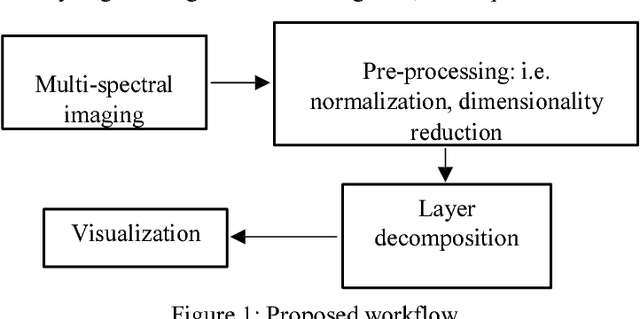



High-resolution imaging has delivered new prospects for detecting the material composition and structure of cultural treasures. Despite the various techniques for analysis, a significant diagnostic gap remained in the range of available research capabilities for works on paper. Old master drawings were mostly composed in a multi-step manner with various materials. This resulted in the overlapping of different layers which made the subjacent strata difficult to differentiate. The separation of stratified layers using imaging methods could provide insights into the artistic work processes and help answer questions about the object, its attribution, or in identifying forgeries. The pattern recognition procedure was tested with mock replicas to achieve the separation and the capability of displaying concealed red chalk under ink. In contrast to RGB-sensor based imaging, the multi- or hyperspectral technology allows accurate layer separation by recording the characteristic signatures of the material's reflectance. The risk of damage to the artworks as a result of the examination can be reduced by using combinations of defined spectra for lightning and image capturing. By guaranteeing the maximum level of readability, our results suggest that the technique can be applied to a broader range of objects and assist in diagnostic research into cultural treasures in the future.
Benchmarking Super-Resolution Algorithms on Real Data
Sep 08, 2017Over the past decades, various super-resolution (SR) techniques have been developed to enhance the spatial resolution of digital images. Despite the great number of methodical contributions, there is still a lack of comparative validations of SR under practical conditions, as capturing real ground truth data is a challenging task. Therefore, current studies are either evaluated 1) on simulated data or 2) on real data without a pixel-wise ground truth. To facilitate comprehensive studies, this paper introduces the publicly available Super-Resolution Erlangen (SupER) database that includes real low-resolution images along with high-resolution ground truth data. Our database comprises image sequences with more than 20k images captured from 14 scenes under various types of motions and photometric conditions. The datasets cover four spatial resolution levels using camera hardware binning. With this database, we benchmark 15 single-image and multi-frame SR algorithms. Our experiments quantitatively analyze SR accuracy and robustness under realistic conditions including independent object and camera motion or photometric variations.
An Evaluation of Popular Copy-Move Forgery Detection Approaches
Nov 26, 2012
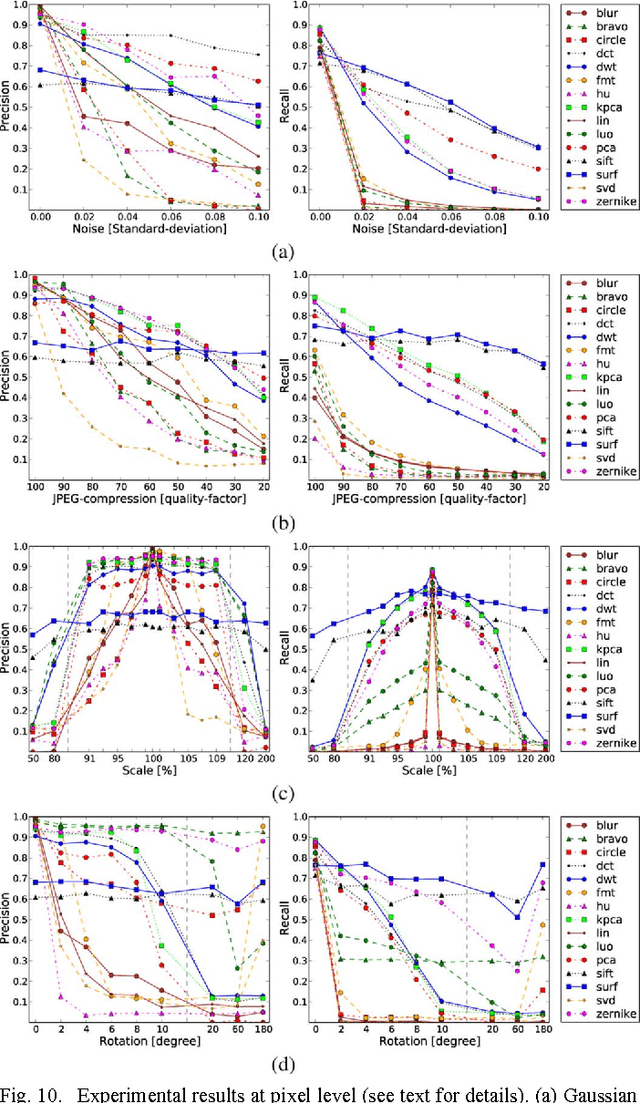
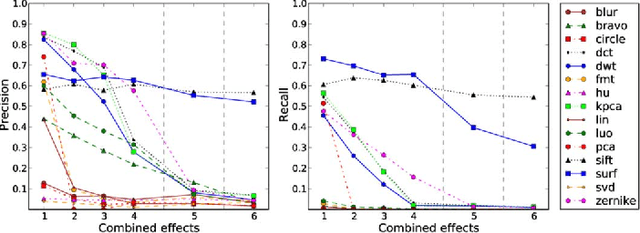
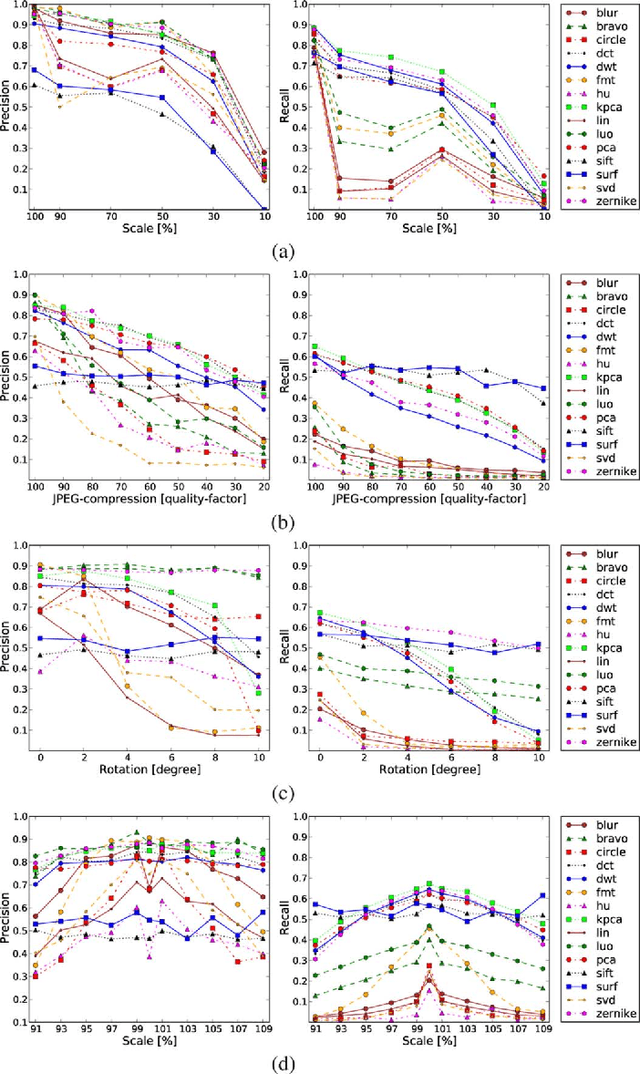
A copy-move forgery is created by copying and pasting content within the same image, and potentially post-processing it. In recent years, the detection of copy-move forgeries has become one of the most actively researched topics in blind image forensics. A considerable number of different algorithms have been proposed focusing on different types of postprocessed copies. In this paper, we aim to answer which copy-move forgery detection algorithms and processing steps (e.g., matching, filtering, outlier detection, affine transformation estimation) perform best in various postprocessing scenarios. The focus of our analysis is to evaluate the performance of previously proposed feature sets. We achieve this by casting existing algorithms in a common pipeline. In this paper, we examined the 15 most prominent feature sets. We analyzed the detection performance on a per-image basis and on a per-pixel basis. We created a challenging real-world copy-move dataset, and a software framework for systematic image manipulation. Experiments show, that the keypoint-based features SIFT and SURF, as well as the block-based DCT, DWT, KPCA, PCA and Zernike features perform very well. These feature sets exhibit the best robustness against various noise sources and downsampling, while reliably identifying the copied regions.
* Main paper: 14 pages, supplemental material: 12 pages, main paper appeared in IEEE Transaction on Information Forensics and Security