 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction of Voxels with Position- and Angle-Dependent Weightings
Oct 27, 2020

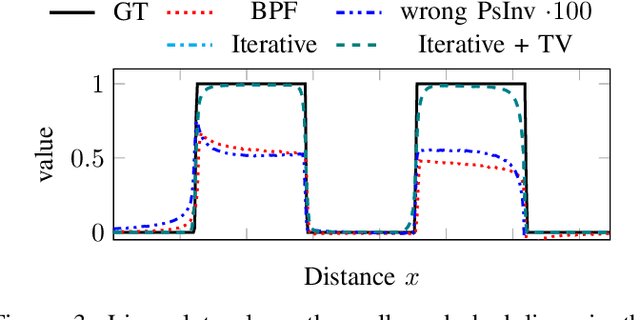
The reconstruction problem of voxels with individual weightings can be modeled a position- and angle- dependent function in the forward-projection. This changes the system matrix and prohibits to use standard filtered backprojection. In this work we first formulate this reconstruction problem in terms of a system matrix and weighting part. We compute the pseudoinverse and show that the solution is rank-deficient and hence very ill posed. This is a fundamental limitation for reconstruction. We then derive an iterative solution and experimentally show its uperiority to any closed-form solution.
Toward Reliable Models for Authenticating Multimedia Content: Detecting Resampling Artifacts With Bayesian Neural Networks
Jul 28, 2020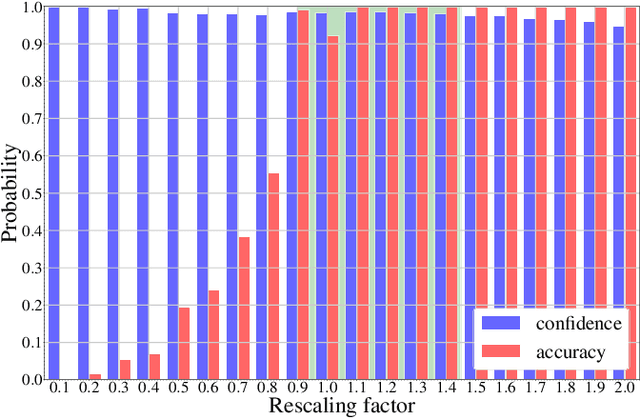
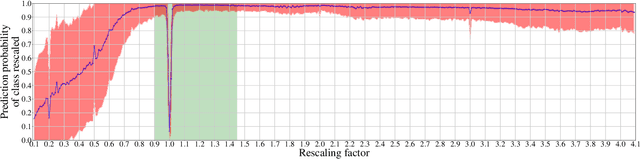
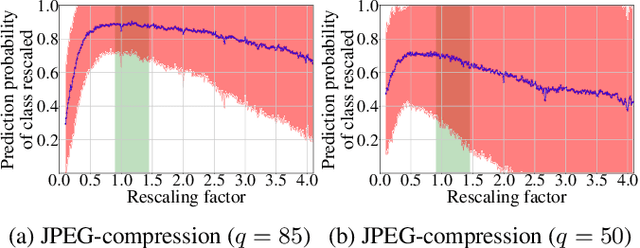
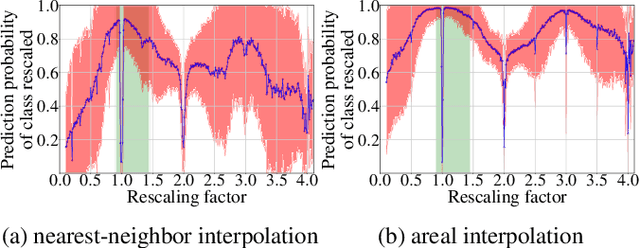
In multimedia forensics, learning-based methods provide state-of-the-art performance in determining origin and authenticity of images and videos. However, most existing methods are challenged by out-of-distribution data, i.e., with characteristics that are not covered in the training set. This makes it difficult to know when to trust a model, particularly for practitioners with limited technical background. In this work, we make a first step toward redesigning forensic algorithms with a strong focus on reliability. To this end, we propose to use Bayesian neural networks (BNN), which combine the power of deep neural networks with the rigorous probabilistic formulation of a Bayesian framework. Instead of providing a point estimate like standard neural networks, BNNs provide distributions that express both the estimate and also an uncertainty range. We demonstrate the usefulness of this framework on a classical forensic task: resampling detection. The BNN yields state-of-the-art detection performance, plus excellent capabilities for detecting out-of-distribution samples. This is demonstrated for three pathologic issues in resampling detection, namely unseen resampling factors, unseen JPEG compression, and unseen resampling algorithms. We hope that this proposal spurs further research toward reliability in multimedia forensics.
Merging-ISP: Multi-Exposure High Dynamic Range Image Signal Processing
Nov 12, 2019
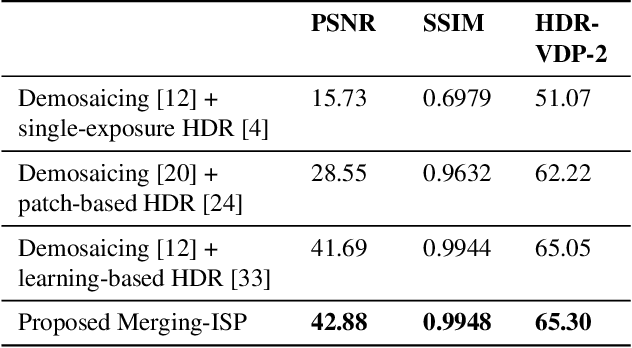
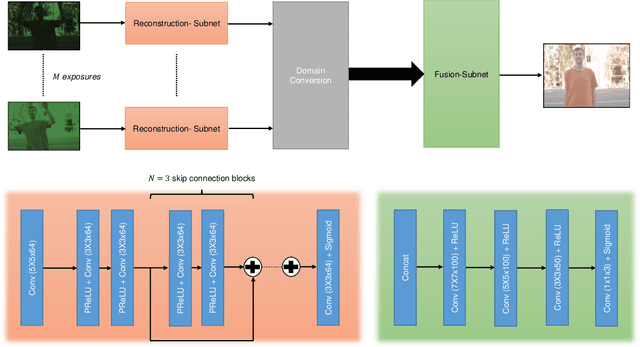
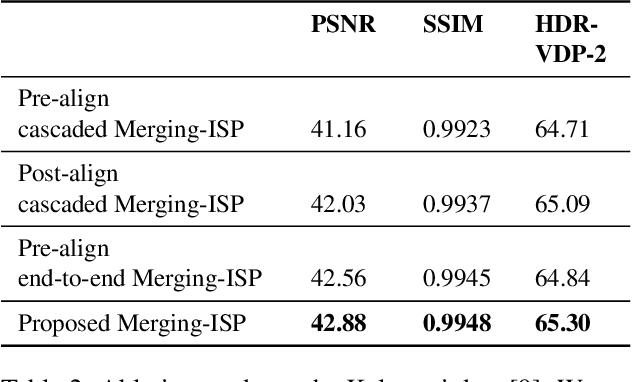
The image signal processing pipeline (ISP) is a core element of digital cameras to capture high-quality displayable images from raw data. In high dynamic range (HDR) imaging, ISPs include steps like demosaicing of raw color filter array (CFA) data at different exposure times, alignment of the exposures, conversion to HDR domain, and exposure merging into an HDR image. Traditionally, such pipelines are built by cascading algorithms addressing the individual subtasks. However, cascaded designs suffer from error propagations since simply combining multiple processing steps is not necessarily optimal for the entire imaging task. This paper proposes a multi-exposure high dynamic range image signal processing pipeline (Merging-ISP) to jointly solve all subtasks for HDR imaging. Our pipeline is modeled by a deep neural network architecture. As such, it is end-to-end trainable, circumvents the use of complex, hand-crafted algorithms in its core, and mitigates error propagation. Merging-ISP enables direct reconstructions of HDR images from multiple differently exposed raw CFA images captured from dynamic scenes. We compared Merging-ISP against different alternative cascaded pipelines. End-to-end learning leads to HDR reconstructions of high perceptual quality and quantitatively outperforms competing ISPs by more than 1 dB in terms of PSNR.
FaceForensics++: Learning to Detect Manipulated Facial Images
Jan 25, 2019

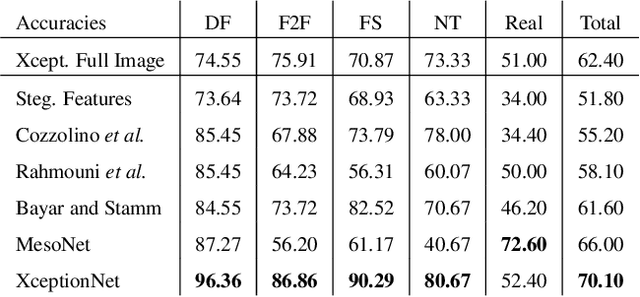
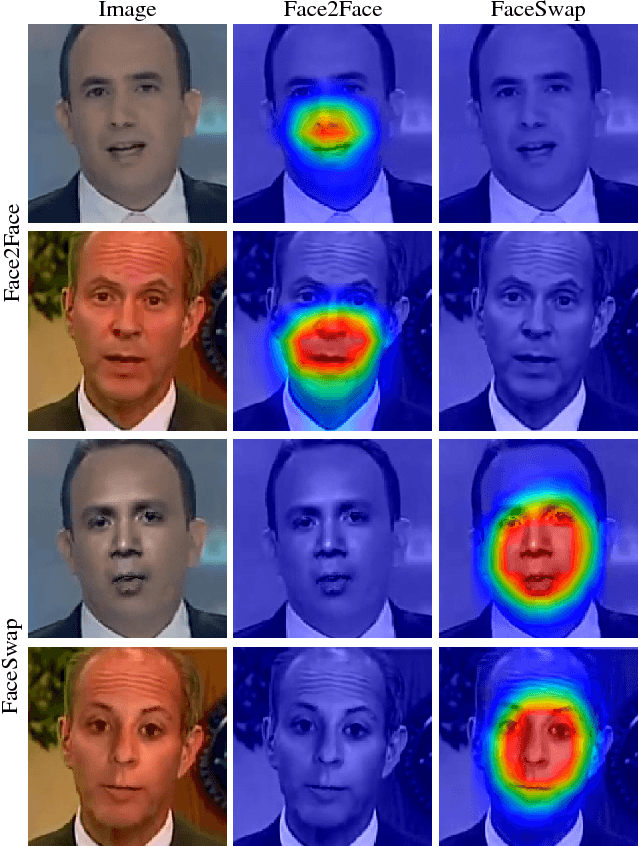
The rapid progress in synthetic image generation and manipulation has now come to a point where it raises significant concerns on the implication on the society. At best, this leads to a loss of trust in digital content, but it might even cause further harm by spreading false information and the creation of fake news. In this paper, we examine the realism of state-of-the-art image manipulations, and how difficult it is to detect them - either automatically or by humans. In particular, we focus on DeepFakes, Face2Face, and FaceSwap as prominent representatives for facial manipulations. We create more than half a million manipulated images respectively for each approach. The resulting publicly available dataset is at least an order of magnitude larger than comparable alternatives and it enables us to train data-driven forgery detectors in a supervised fashion. We show that the use of additional domain specific knowledge improves forgery detection to an unprecedented accuracy, even in the presence of strong compression. By conducting a series of thorough experiments, we quantify the differences between classical approaches, novel deep learning approaches, and the performance of human observers.
ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection
Dec 06, 2018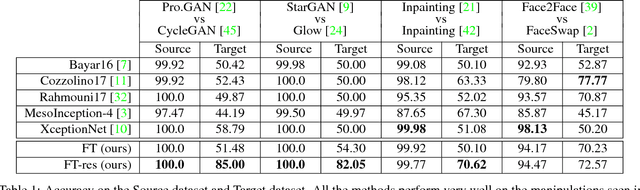


Distinguishing fakes from real images is becoming increasingly difficult as new sophisticated image manipulation approaches come out by the day. Convolutional neural networks (CNN) show excellent performance in detecting image manipulations when they are trained on a specific forgery method. However, on examples from unseen manipulation approaches, their performance drops significantly. To address this limitation in transferability, we introduce ForensicTransfer. ForensicTransfer tackles two challenges in multimedia forensics. First, we devise a learning-based forensic detector which adapts well to new domains, i.e., novel manipulation methods. Second we handle scenarios where only a handful of fake examples are available during training. To this end, we learn a forensic embedding that can be used to distinguish between real and fake imagery. We are using a new autoencoder-based architecture which enforces activations in different parts of a latent vector for the real and fake classes. Together with the constraint of correct reconstruction this ensures that the latent space keeps all the relevant information about the nature of the image. Therefore, the learned embedding acts as a form of anomaly detector; namely, an image manipulated from an unseen method will be detected as fake provided it maps sufficiently far away from the cluster of real images. Comparing with prior works, ForensicTransfer shows significant improvements in transferability, which we demonstrate in a series of experiments on cutting-edge benchmarks. For instance, on unseen examples, we achieve up to 80-85% in terms of accuracy compared to 50-59%, and with only a handful of seen examples, our performance already reaches around 95%.
A 3-D Projection Model for X-ray Dark-field Imaging
Nov 11, 2018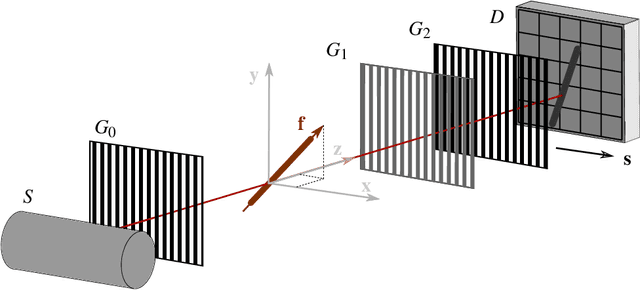
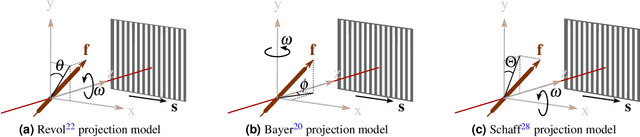
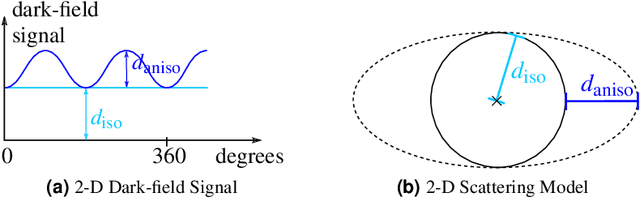
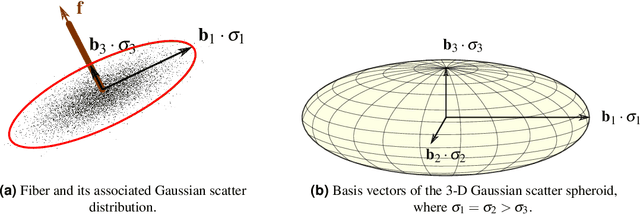
Talbot-Lau X-ray phase-contrast imaging is a novel imaging modality, which provides not only an X-ray absorption image, but also additionally a differential phase image and a dark-field image. The dark-field image is related to small angle scattering and has an interesting property when canning oriented structures: the recorded signal depends on the relative orientation of the structure in the imaging system. Exactly this property allows to draw conclusions about the orientation and to reconstruct the structure. However, the reconstruction is a complex, non-trivial challenge. A lot of research was conducted towards this goal in the last years and several reconstruction algorithms were proposed. A key step of the reconstruction algorithm is the inversion of a forward projection model. Up until now, only 2-D projection models are available, with effectively limit the scanning trajectory to a 2-D plane. To obtain true 3-D information, this limitation requires to combine several 2-D scans, which leads to quite complex, impractical acquisitions schemes. Furthermore, it is not possible with these models to use 3-D trajectories that might allow simpler protocols, like for example a helical trajectory. To address these limitations, we propose in this work a very general 3-D projection model. Our projection model defines the dark-field signal dependent on an arbitrarily chosen ray and sensitivity direction. We derive the projection model under the assumption that the observed scatter distribution has a Gaussian shape. We theoretically show the consistency of our model with more constrained existing 2-D models. Furthermore, we experimentally show the compatibility of our model with dark-field measurements of two matchsticks. We believe that this 3-D projection model is an important step towards more flexible trajectories and imaging protocols that are much better applicable in practice.
A Gentle Introduction to Deep Learning in Medical Image Processing
Oct 12, 2018
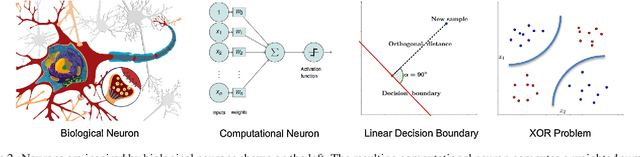
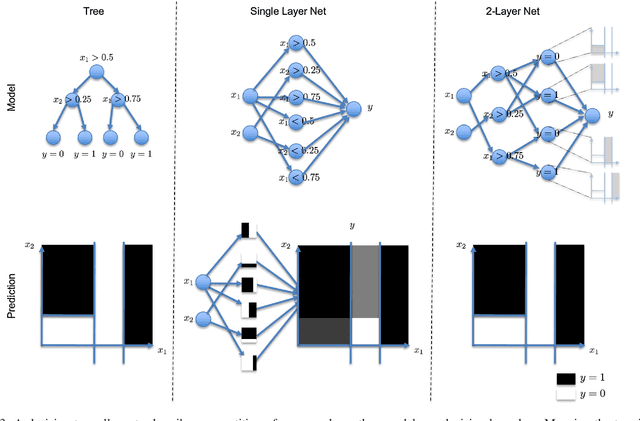
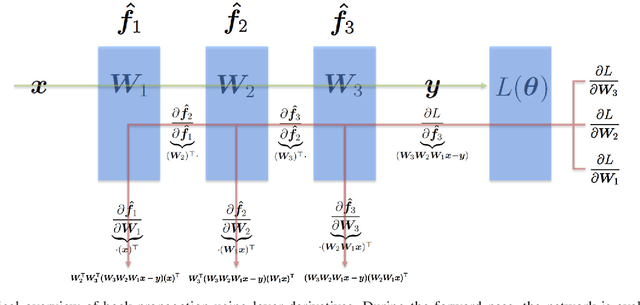
This paper tries to give a gentle introduction to deep learning in medical image processing, proceeding from theoretical foundations to applications. We first discuss general reasons for the popularity of deep learning, including several major breakthroughs in computer science. Next, we start reviewing the fundamental basics of the perceptron and neural networks, along with some fundamental theory that is often omitted. Doing so allows us to understand the reasons for the rise of deep learning in many application domains. Obviously medical image processing is one of these areas which has been largely affected by this rapid progress, in particular in image detection and recognition, image segmentation, image registration, and computer-aided diagnosis. There are also recent trends in physical simulation, modelling, and reconstruction that have led to astonishing results. Yet, some of these approaches neglect prior knowledge and hence bear the risk of producing implausible results. These apparent weaknesses highlight current limitations of deep learning. However, we also briefly discuss promising approaches that might be able to resolve these problems in the future.
Bridging the Simulated-to-Real Gap: Benchmarking Super-Resolution on Real Data
Sep 17, 2018
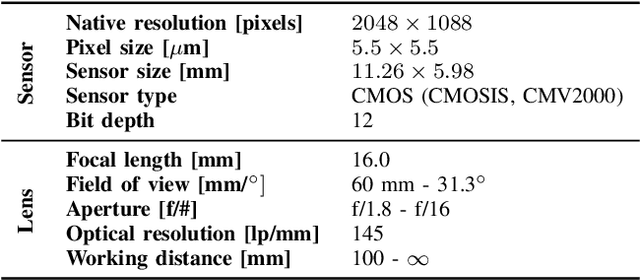
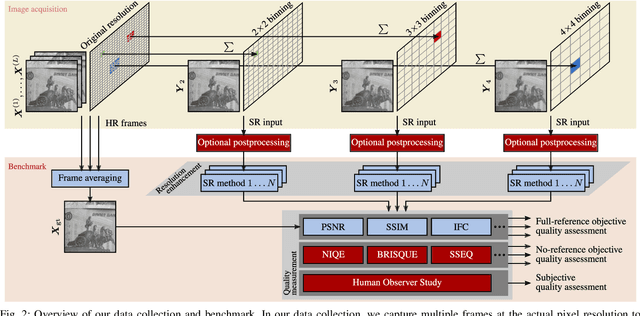

Capturing ground truth data to benchmark super-resolution (SR) is challenging. Therefore, current quantitative studies are mainly evaluated on simulated data artificially sampled from ground truth images. We argue that such evaluations overestimate the actual performance of SR methods compared to their behavior on real images. To bridge this simulated-to-real gap, we introduce the Super-Resolution Erlangen (SupER) database, the first comprehensive laboratory SR database of all-real acquisitions with pixel-wise ground truth. It consists of more than 80k images of 14 scenes combining different facets: CMOS sensor noise, real sampling at four resolution levels, nine scene motion types, two photometric conditions, and lossy video coding at five levels. As such, the database exceeds existing benchmarks by an order of magnitude in quality and quantity. This paper also benchmarks 19 popular single-image and multi-frame algorithms on our data. The benchmark comprises a quantitative study by exploiting ground truth data and qualitative evaluations in a large-scale observer study. We also rigorously investigate agreements between both evaluations from a statistical perspective. One interesting result is that top-performing methods on simulated data may be surpassed by others on real data. Our insights can spur further algorithm development, and the publicy available dataset can foster future evaluations.
Automatic Classification of Defective Photovoltaic Module Cells in Electroluminescence Images
Jul 08, 2018
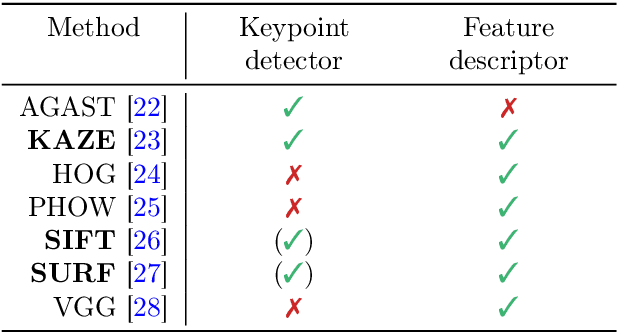


Electroluminescence (EL) imaging is a useful modality for the inspection of photovoltaic (PV) modules. EL images provide high spatial resolution, which makes it possible to detect even finest defects on the surface of PV modules. However, the analysis of EL images is typically a manual process that is expensive, time-consuming, and requires expert knowledge of many different types of defects. In this work, we investigate two approaches for automatic detection of such defects in a single image of a PV cell. The approaches differ in their hardware requirements, which are dictated by their respective application scenarios. The more hardware-efficient approach is based on hand-crafted features that are classified in a Support Vector Machine (SVM). To obtain a strong performance, we investigate and compare various processing variants. The more hardware-demanding approach uses an end-to-end deep Convolutional Neural Network (CNN) that runs on a Graphics Processing Unit (GPU). Both approaches are trained on 1,968 cells extracted from high resolution EL intensity images of mono- and polycrystalline PV modules. The CNN is more accurate, and reaches an average accuracy of 88.42%. The SVM achieves a slightly lower average accuracy of 82.44%, but can run on arbitrary hardware. Both automated approaches make continuous, highly accurate monitoring of PV cells feasible.
Segmentation of Photovoltaic Module Cells in Electroluminescence Images
Jun 18, 2018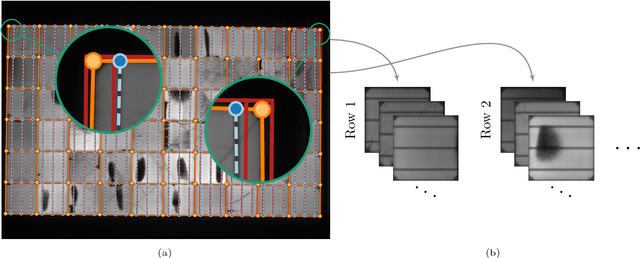
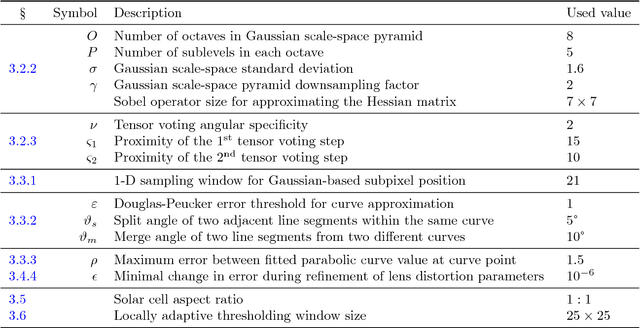
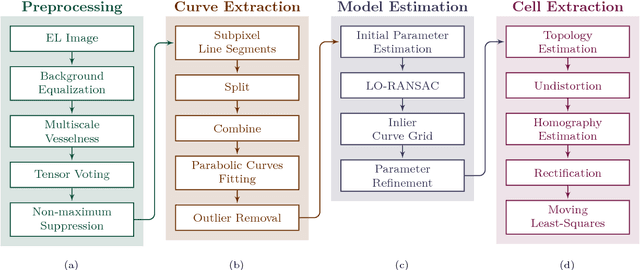
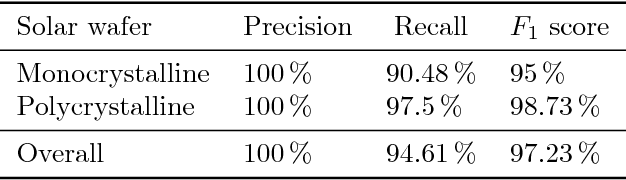
High resolution electroluminescence (EL) images captured in the infrared spectrum allow to visually and non-destructively inspect the quality of photovoltaic (PV) modules. Currently, however, such a visual inspection requires trained experts to discern different kind of defects, which is time-consuming and expensive. In this work, we make an important step towards improving the current state-of-the-art in solar module inspection. We propose a robust automated segmentation method to extract individual solar cells from EL images of PV modules. Automated segmentation of cells is a key step in automating the visual inspection workflow. It also enables controlled studies on large amounts of data to understanding the effects of module degradation over time - a process not yet fully understood. The proposed method infers in several steps a high level solar module representation from low-level edge features. An important step in the algorithm is to formulate the segmentation problem in terms of lens calibration by exploiting the plumbline constraint. We evaluate our method on a dataset of various solar modules types containing a total of 408 solar cells with various defects. Our method robustly solves this task with a median weighted Jaccard index of 96.09% and an $F_1$ score of 97.23%.