 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConic Blackwell Algorithm: Parameter-Free Convex-Concave Saddle-Point Solving
Jun 10, 2021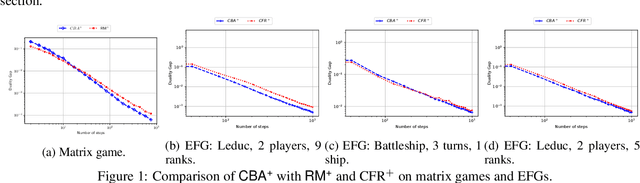
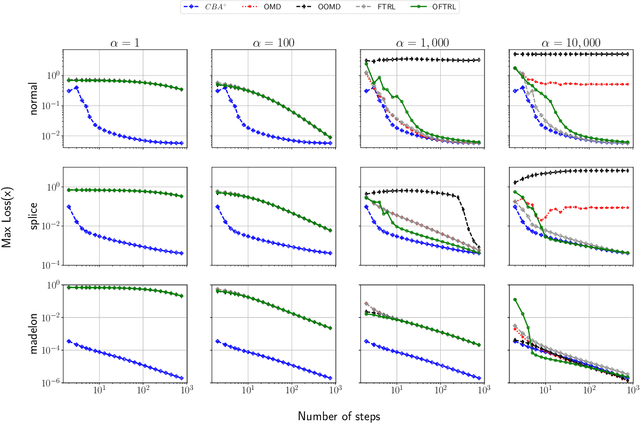
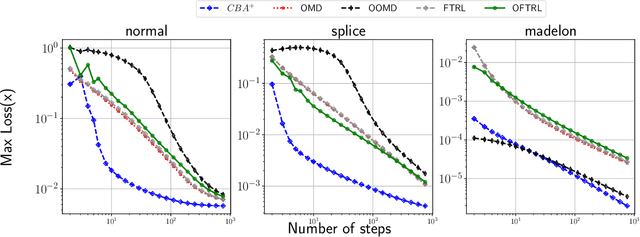
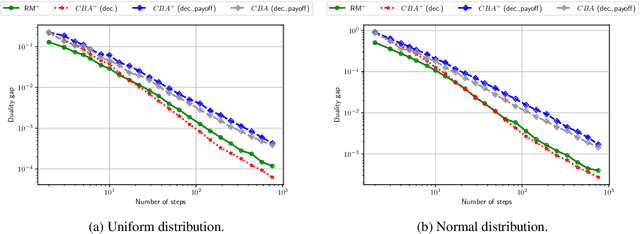
We develop new parameter and scale-free algorithms for solving convex-concave saddle-point problems. Our results are based on a new simple regret minimizer, the Conic Blackwell Algorithm$^+$ (CBA$^+$), which attains $O(1/\sqrt{T})$ average regret. Intuitively, our approach generalizes to other decision sets of interest ideas from the Counterfactual Regret minimization (CFR$^+$) algorithm, which has very strong practical performance for solving sequential games on simplexes. We show how to implement CBA$^+$ for the simplex, $\ell_{p}$ norm balls, and ellipsoidal confidence regions in the simplex, and we present numerical experiments for solving matrix games and distributionally robust optimization problems. Our empirical results show that CBA$^+$ is a simple algorithm that outperforms state-of-the-art methods on synthetic data and real data instances, without the need for any choice of step sizes or other algorithmic parameters.
Better Regularization for Sequential Decision Spaces: Fast Convergence Rates for Nash, Correlated, and Team Equilibria
May 27, 2021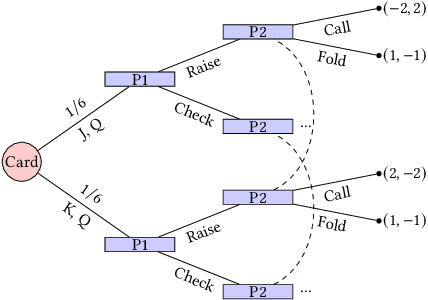
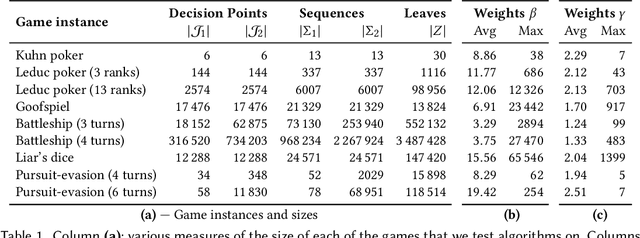
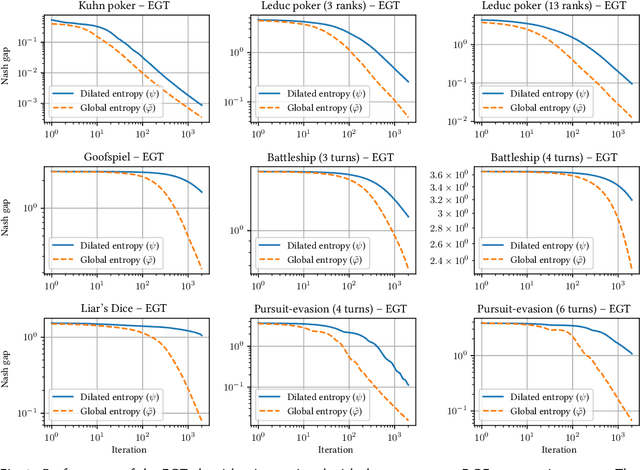
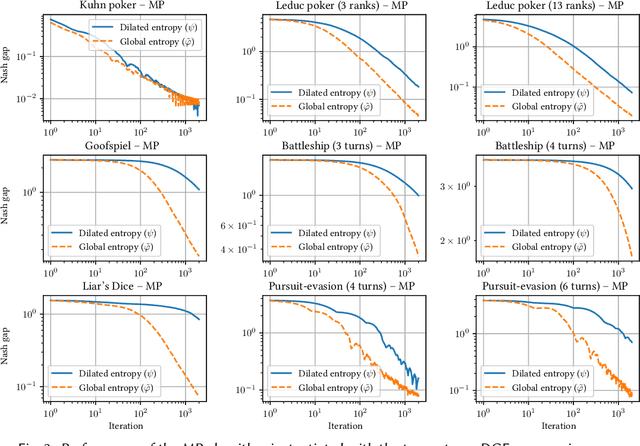
We study the application of iterative first-order methods to the problem of computing equilibria of large-scale two-player extensive-form games. First-order methods must typically be instantiated with a regularizer that serves as a distance-generating function for the decision sets of the players. For the case of two-player zero-sum games, the state-of-the-art theoretical convergence rate for Nash equilibrium is achieved by using the dilated entropy function. In this paper, we introduce a new entropy-based distance-generating function for two-player zero-sum games, and show that this function achieves significantly better strong convexity properties than the dilated entropy, while maintaining the same easily-implemented closed-form proximal mapping. Extensive numerical simulations show that these superior theoretical properties translate into better numerical performance as well. We then generalize our new entropy distance function, as well as general dilated distance functions, to the scaled extension operator. The scaled extension operator is a way to recursively construct convex sets, which generalizes the decision polytope of extensive-form games, as well as the convex polytopes corresponding to correlated and team equilibria. By instantiating first-order methods with our regularizers, we develop the first accelerated first-order methods for computing correlated equilibra and ex-ante coordinated team equilibria. Our methods have a guaranteed $1/T$ rate of convergence, along with linear-time proximal updates.
Faster Game Solving via Predictive Blackwell Approachability: Connecting Regret Matching and Mirror Descent
Jul 28, 2020
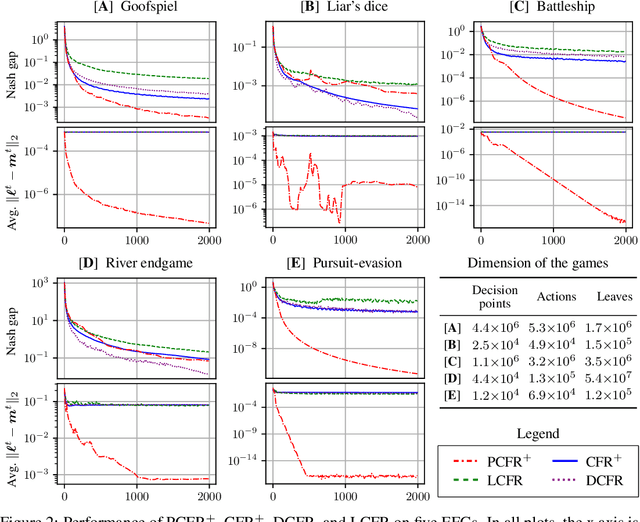
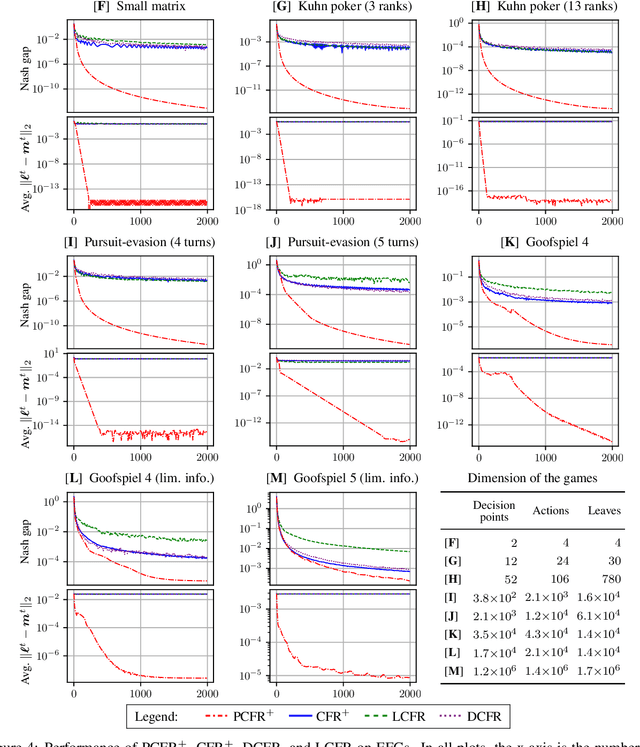
Blackwell approachability is a framework for reasoning about repeated games with vector-valued payoffs. We introduce predictive Blackwell approachability, where an estimate of the next payoff vector is given, and the decision maker tries to achieve better performance based on the accuracy of that estimator. In order to derive algorithms that achieve predictive Blackwell approachability, we start by showing a powerful connection between four well-known algorithms. Follow-the-regularized-leader (FTRL) and online mirror descent (OMD) are the most prevalent regret minimizers in online convex optimization. In spite of this prevalence, the regret matching (RM) and regret matching+ (RM+) algorithms have been preferred in the practice of solving large-scale games (as the local regret minimizers within the counterfactual regret minimization framework). We show that RM and RM+ are the algorithms that result from running FTRL and OMD, respectively, to select the halfspace to force at all times in the underlying Blackwell approachability game. By applying the predictive variants of FTRL or OMD to this connection, we obtain predictive Blackwell approachability algorithms, as well as predictive variants of RM and RM+. In experiments across 18 common zero-sum extensive-form benchmark games, we show that predictive RM+ coupled with counterfactual regret minimization converges vastly faster than the fastest prior algorithms (CFR+, DCFR, LCFR) across all games but two of the poker games and Liar's Dice, sometimes by two or more orders of magnitude.
Evaluating and Rewarding Teamwork Using Cooperative Game Abstractions
Jun 16, 2020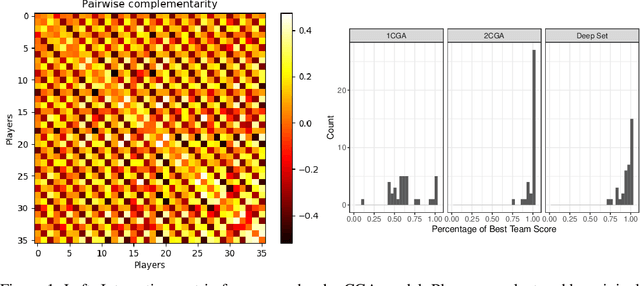

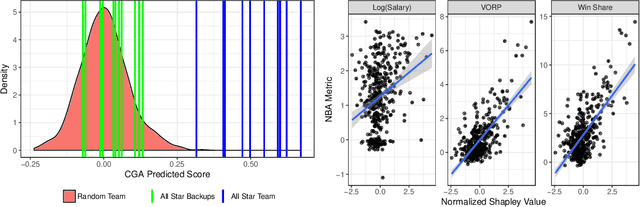

Can we predict how well a team of individuals will perform together? How should individuals be rewarded for their contributions to the team performance? Cooperative game theory gives us a powerful set of tools for answering these questions: the Characteristic Function (CF) and solution concepts like the Shapley Value (SV). There are two major difficulties in applying these techniques to real world problems: first, the CF is rarely given to us and needs to be learned from data. Second, the SV is combinatorial in nature. We introduce a parametric model called cooperative game abstractions (CGAs) for estimating CFs from data. CGAs are easy to learn, readily interpretable, and crucially allow linear-time computation of the SV. We provide identification results and sample complexity bounds for CGA models as well as error bounds in the estimation of the SV using CGAs. We apply our methods to study teams of artificial RL agents as well as real world teams from professional sports.
Scalable First-Order Methods for Robust MDPs
Jun 05, 2020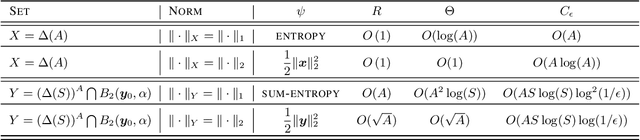

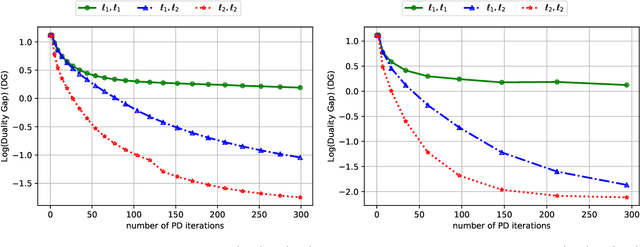
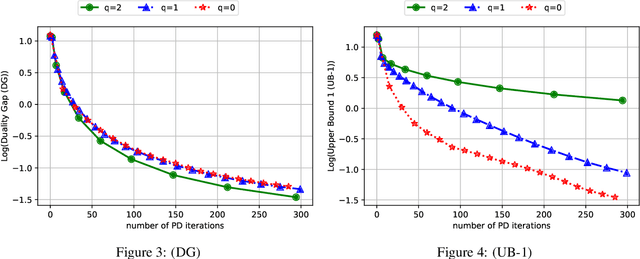
Markov Decision Processes (MDPs) are a widely used model for dynamic decision-making problems. However, MDPs require precise specification of model parameters, and often the cost of a policy can be highly sensitive to the estimated parameters. Robust MDPs ameliorate this issue by allowing one to specify uncertainty sets around the parameters, which leads to a non-convex optimization problem. This non-convex problem can be solved via the Value Iteration algorithm, but Value Iteration requires repeatedly solving convex programs that become prohibitively expensive as MDPs grow larger. We propose an algorithmic framework based on first-order methods, where we interleave approximate value iteration updates with a first-order-based computation of the robust Bellman update. Our algorithm relies on having a proximal setup for the uncertainty sets. We go on to instantiate this proximal setup for $s$-rectangular ellipsoidal uncertainty sets and Kullback-Leibler uncertainty sets. By carefully controlling the warm-starts of our first-order method and the increasing approximation rate at each Value Iteration update, our algorithm achieves a convergence rate of $O \left( A^{2} S^{3}\log(S)\log(\epsilon^{-1}) \epsilon^{-1} \right)$ for the best choice of parameters, where $S,A$ are the numbers of states and actions. Our dependence on the number of states and actions is significantly better than that of Value Iteration algorithms. In numerical experiments on ellipsoidal uncertainty sets, we show that our algorithm is significantly more scalable than state-of-the-art approaches. In the class of $s$-rectangular robust MDPs, to the best of our knowledge, our algorithm is the first to address Kullback-Leibler uncertainty sets.
Stochastic Regret Minimization in Extensive-Form Games
Feb 19, 2020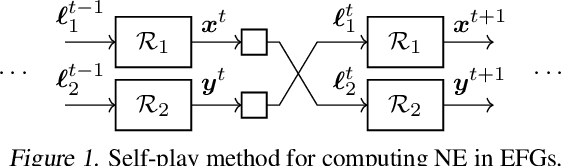
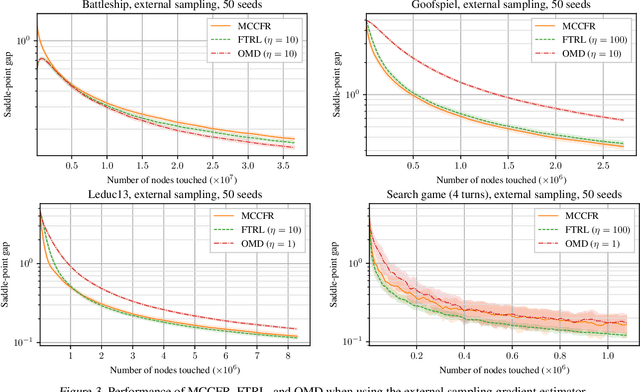
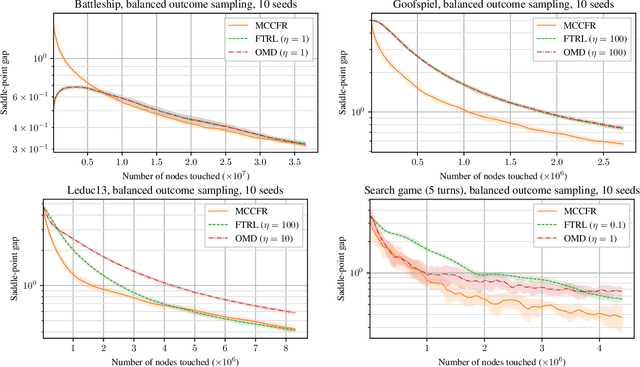
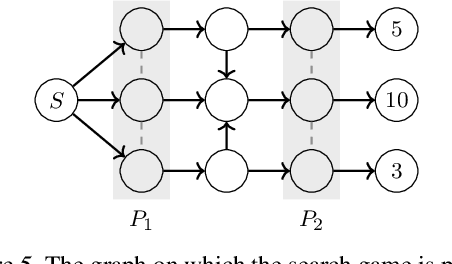
Monte-Carlo counterfactual regret minimization (MCCFR) is the state-of-the-art algorithm for solving sequential games that are too large for full tree traversals. It works by using gradient estimates that can be computed via sampling. However, stochastic methods for sequential games have not been investigated extensively beyond MCCFR. In this paper we develop a new framework for developing stochastic regret minimization methods. This framework allows us to use any regret-minimization algorithm, coupled with any gradient estimator. The MCCFR algorithm can be analyzed as a special case of our framework, and this analysis leads to significantly-stronger theoretical on convergence, while simultaneously yielding a simplified proof. Our framework allows us to instantiate several new stochastic methods for solving sequential games. We show extensive experiments on three games, where some variants of our methods outperform MCCFR.
Optimistic Regret Minimization for Extensive-Form Games via Dilated Distance-Generating Functions
Oct 28, 2019
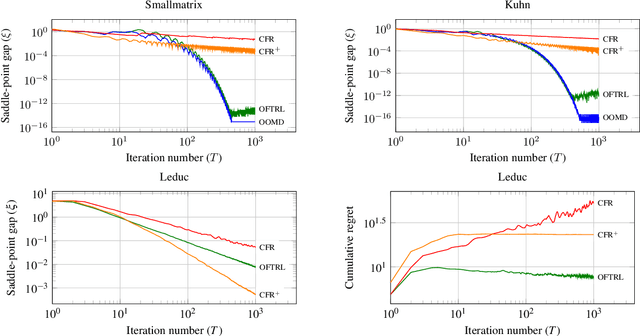
We study the performance of optimistic regret-minimization algorithms for both minimizing regret in, and computing Nash equilibria of, zero-sum extensive-form games. In order to apply these algorithms to extensive-form games, a distance-generating function is needed. We study the use of the dilated entropy and dilated Euclidean distance functions. For the dilated Euclidean distance function we prove the first explicit bounds on the strong-convexity parameter for general treeplexes. Furthermore, we show that the use of dilated distance-generating functions enable us to decompose the mirror descent algorithm, and its optimistic variant, into local mirror descent algorithms at each information set. This decomposition mirrors the structure of the counterfactual regret minimization framework, and enables important techniques in practice, such as distributed updates and pruning of cold parts of the game tree. Our algorithms provably converge at a rate of $T^{-1}$, which is superior to prior counterfactual regret minimization algorithms. We experimentally compare to the popular algorithm CFR+, which has a theoretical convergence rate of $T^{-0.5}$ in theory, but is known to often converge at a rate of $T^{-1}$, or better, in practice. We give an example matrix game where CFR+ experimentally converges at a relatively slow rate of $T^{-0.74}$, whereas our optimistic methods converge faster than $T^{-1}$. We go on to show that our fast rate also holds in the Kuhn poker game, which is an extensive-form game. For games with deeper game trees however, we find that CFR+ is still faster. Finally we show that when the goal is minimizing regret, rather than computing a Nash equilibrium, our optimistic methods can outperform CFR+, even in deep game trees.
Fair Division Without Disparate Impact
Jun 06, 2019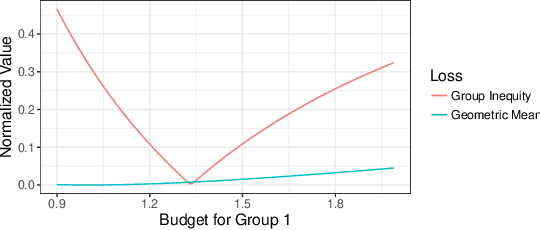
We consider the problem of dividing items between individuals in a way that is fair both in the sense of distributional fairness and in the sense of not having disparate impact across protected classes. An important existing mechanism for distributionally fair division is competitive equilibrium from equal incomes (CEEI). Unfortunately, CEEI will not, in general, respect disparate impact constraints. We consider two types of disparate impact measures: requiring that allocations be similar across protected classes and requiring that average utility levels be similar across protected classes. We modify the standard CEEI algorithm in two ways: equitable equilibrium from equal incomes, which removes disparate impact in allocations, and competitive equilibrium from equitable incomes which removes disparate impact in attained utility levels. We show analytically that removing disparate impact in outcomes breaks several of CEEI's desirable properties such as envy, regret, Pareto optimality, and incentive compatibility. By contrast, we can remove disparate impact in attained utility levels without affecting these properties. Finally, we experimentally evaluate the tradeoffs between efficiency, equity, and disparate impact in a recommender-system based market.
Robust Multi-agent Counterfactual Prediction
Apr 03, 2019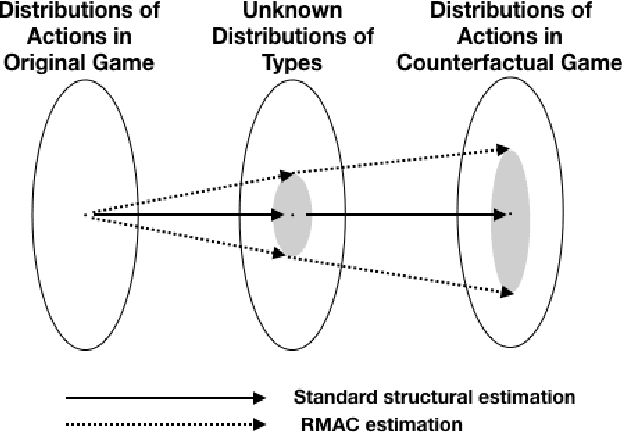
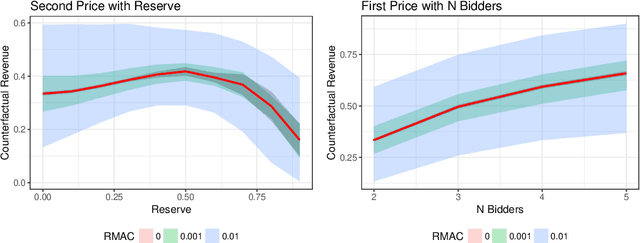
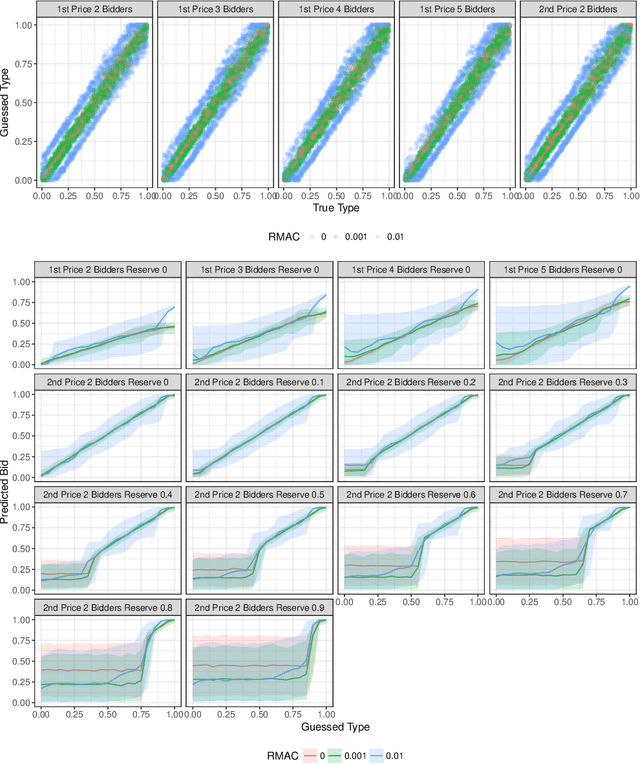
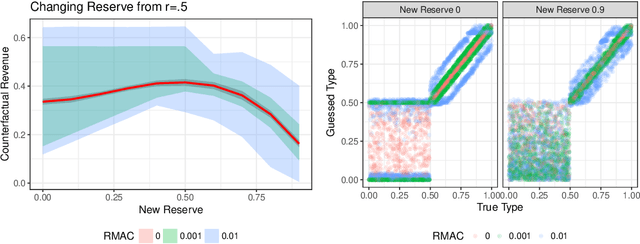
We consider the problem of using logged data to make predictions about what would happen if we changed the `rules of the game' in a multi-agent system. This task is difficult because in many cases we observe actions individuals take but not their private information or their full reward functions. In addition, agents are strategic, so when the rules change, they will also change their actions. Existing methods (e.g. structural estimation, inverse reinforcement learning) make counterfactual predictions by constructing a model of the game, adding the assumption that agents' behavior comes from optimizing given some goals, and then inverting observed actions to learn agent's underlying utility function (a.k.a. type). Once the agent types are known, making counterfactual predictions amounts to solving for the equilibrium of the counterfactual environment. This approach imposes heavy assumptions such as rationality of the agents being observed, correctness of the analyst's model of the environment/parametric form of the agents' utility functions, and various other conditions to make point identification possible. We propose a method for analyzing the sensitivity of counterfactual conclusions to violations of these assumptions. We refer to this method as robust multi-agent counterfactual prediction (RMAC). We apply our technique to investigating the robustness of counterfactual claims for classic environments in market design: auctions, school choice, and social choice. Importantly, we show RMAC can be used in regimes where point identification is impossible (e.g. those which have multiple equilibria or non-injective maps from type distributions to outcomes).
First-Order Methods with Increasing Iterate Averaging for Solving Saddle-Point Problems
Mar 26, 2019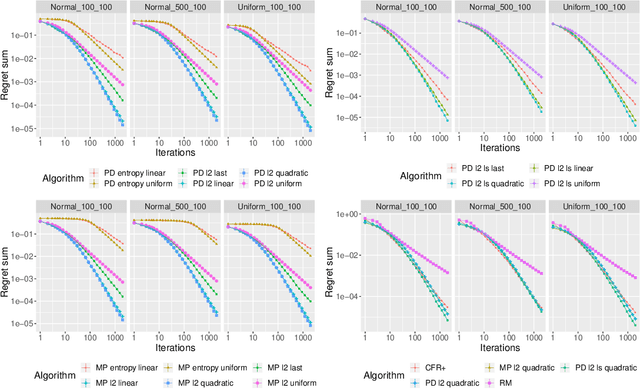

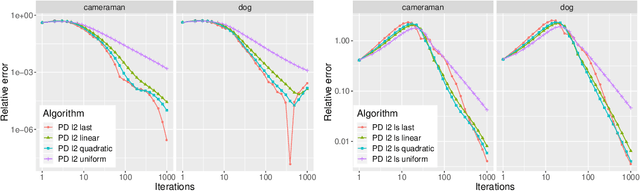
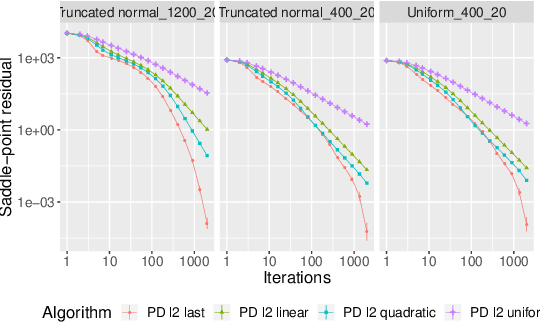
First-order methods are known to be among the fastest algorithms for solving large-scale convex-concave saddle-point problems. Algorithms that achieve a theoretical convergence rate on the order of $1/T$ are known, but these often rely on uniformly averaging iterates in order to get the guaranteed rate. In contrast, using the last iterate has repeatedly been found to perform better in practice, but with no guarantee on convergence rate. In this paper we propose using averaging schemes with increasing weight on recent iterates, which leads to a guaranteed $1/T$ convergence rate, while capturing the practical performance of using the last iterate. We show this for Chambolle and Pock's primal-dual algorithm, and mirror prox. We present numerical results on computing Nash equilibria in matrix games, competitive equilibria in Fisher markets, and image denoising via total-variation minimization under the $\ell_1$ norm. In all cases we find that our averaging schemes lead to much better performance than uniform averaging, and sometimes even better performance than using the last iterate.