 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Word Sense Disambiguation Using Pre-Trained Contextualized Word Representations
Oct 01, 2019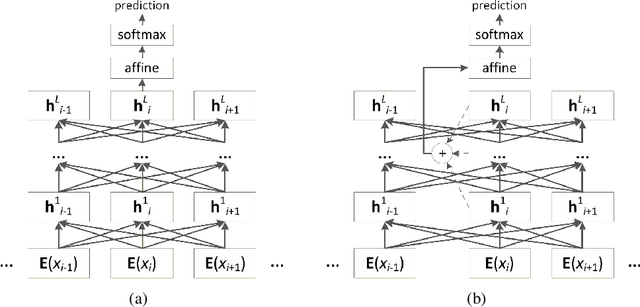
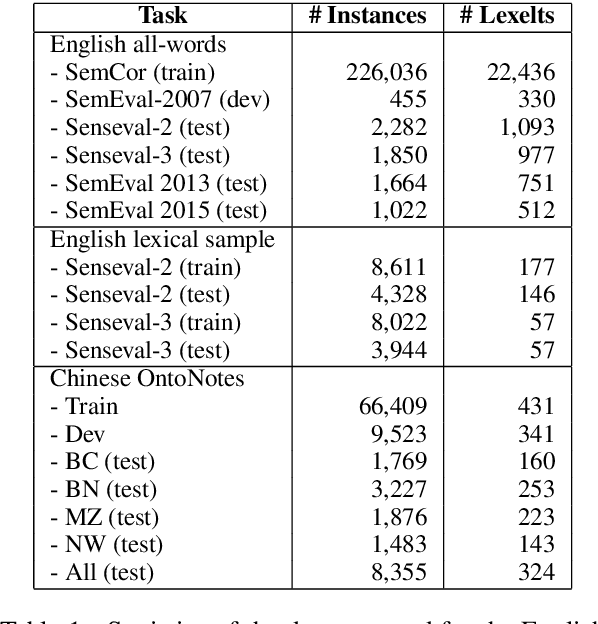
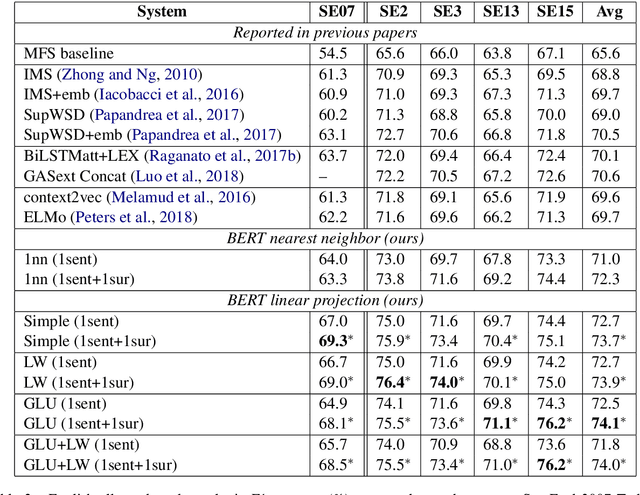
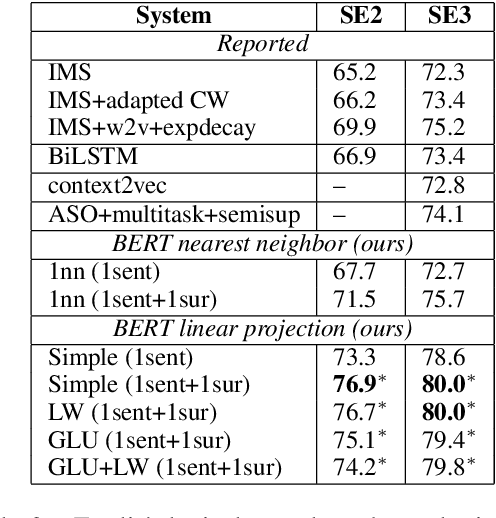
Contextualized word representations are able to give different representations for the same word in different contexts, and they have been shown to be effective in downstream natural language processing tasks, such as question answering, named entity recognition, and sentiment analysis. However, evaluation on word sense disambiguation (WSD) in prior work shows that using contextualized word representations does not outperform the state-of-the-art approach that makes use of non-contextualized word embeddings. In this paper, we explore different strategies of integrating pre-trained contextualized word representations and our best strategy achieves accuracies exceeding the best prior published accuracies by significant margins on multiple benchmark WSD datasets.
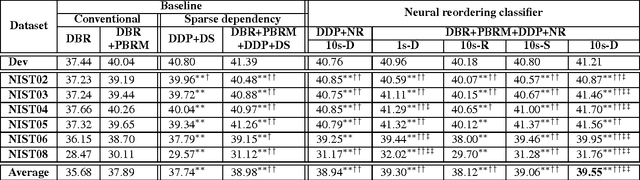
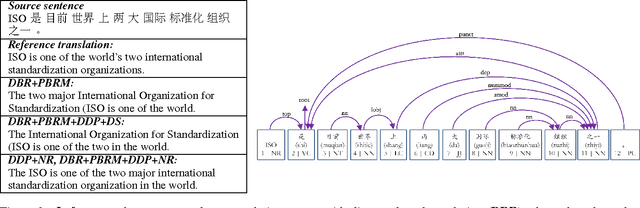
Upping the Ante: Towards a Better Benchmark for Chinese-to-English Machine Translation
May 04, 2018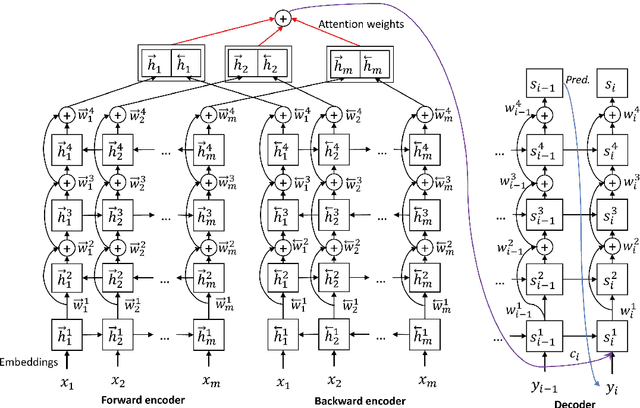
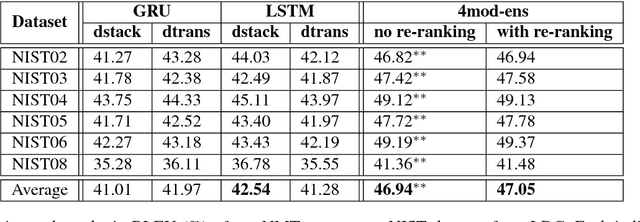
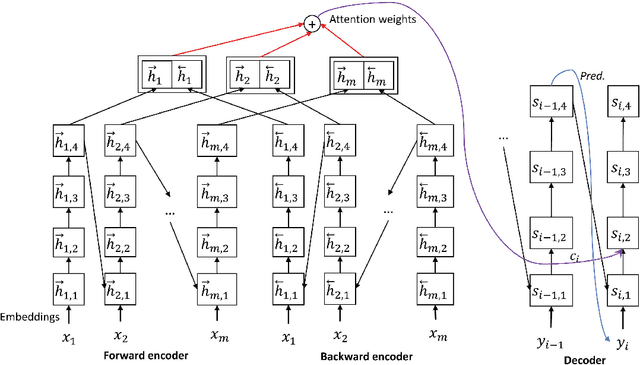
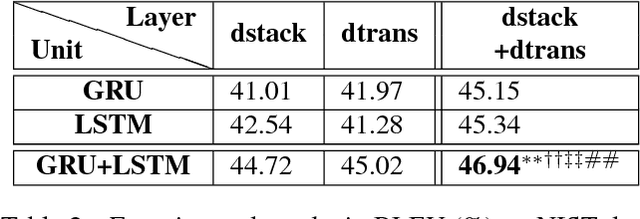
There are many machine translation (MT) papers that propose novel approaches and show improvements over their self-defined baselines. The experimental setting in each paper often differs from one another. As such, it is hard to determine if a proposed approach is really useful and advances the state of the art. Chinese-to-English translation is a common translation direction in MT papers, although there is not one widely accepted experimental setting in Chinese-to-English MT. Our goal in this paper is to propose a benchmark in evaluation setup for Chinese-to-English machine translation, such that the effectiveness of a new proposed MT approach can be directly compared to previous approaches. Towards this end, we also built a highly competitive state-of-the-art MT system trained on a large-scale training set. Our system outperforms reported results on NIST OpenMT test sets in almost all papers published in major conferences and journals in computational linguistics and artificial intelligence in the past 11 years. We argue that a standardized benchmark on data and performance is important for meaningful comparison.
A Dependency-Based Neural Reordering Model for Statistical Machine Translation
Feb 15, 2017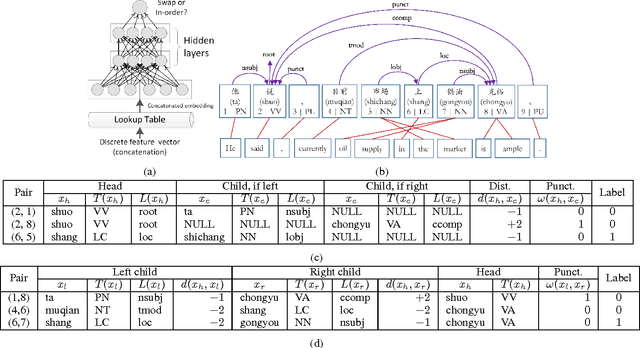
In machine translation (MT) that involves translating between two languages with significant differences in word order, determining the correct word order of translated words is a major challenge. The dependency parse tree of a source sentence can help to determine the correct word order of the translated words. In this paper, we present a novel reordering approach utilizing a neural network and dependency-based embeddings to predict whether the translations of two source words linked by a dependency relation should remain in the same order or should be swapped in the translated sentence. Experiments on Chinese-to-English translation show that our approach yields a statistically significant improvement of 0.57 BLEU point on benchmark NIST test sets, compared to our prior state-of-the-art statistical MT system that uses sparse dependency-based reordering features.
* 7 pages, 3 figures, Proceedings of AAAI-17
To Swap or Not to Swap? Exploiting Dependency Word Pairs for Reordering in Statistical Machine Translation
Aug 03, 2016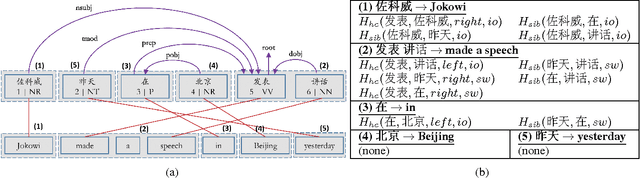
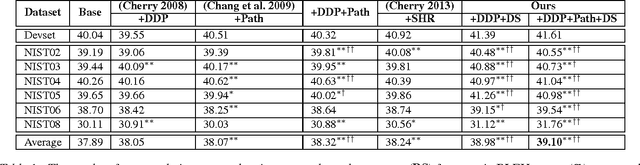
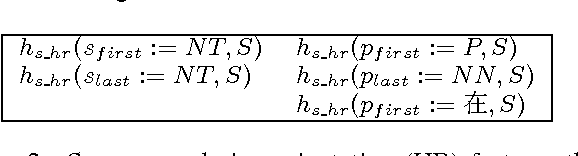
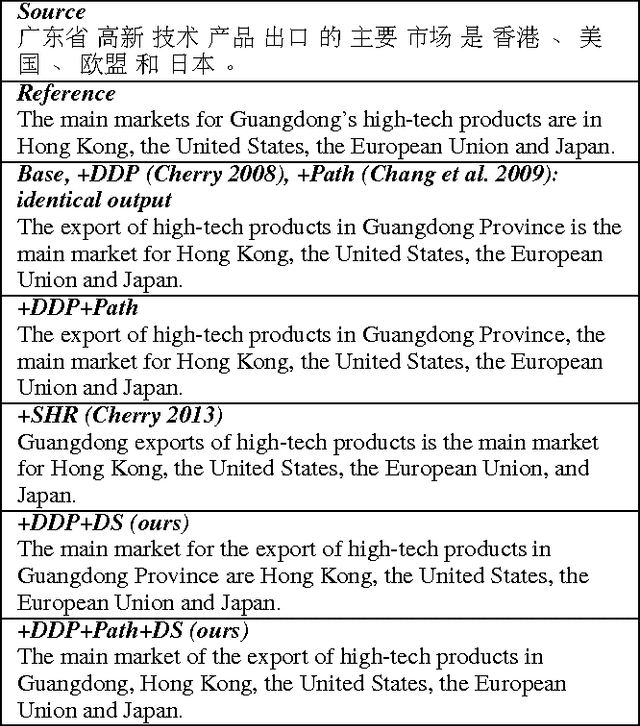
Reordering poses a major challenge in machine translation (MT) between two languages with significant differences in word order. In this paper, we present a novel reordering approach utilizing sparse features based on dependency word pairs. Each instance of these features captures whether two words, which are related by a dependency link in the source sentence dependency parse tree, follow the same order or are swapped in the translation output. Experiments on Chinese-to-English translation show a statistically significant improvement of 1.21 BLEU point using our approach, compared to a state-of-the-art statistical MT system that incorporates prior reordering approaches.
* 7 pages, 1 figures, Proceedings of AAAI-16