 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Model for Hallucinating Diverse Versions of Super Resolution Images
Feb 12, 2021
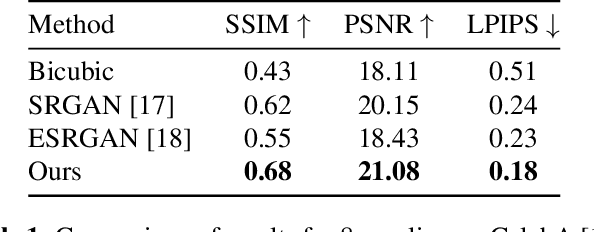
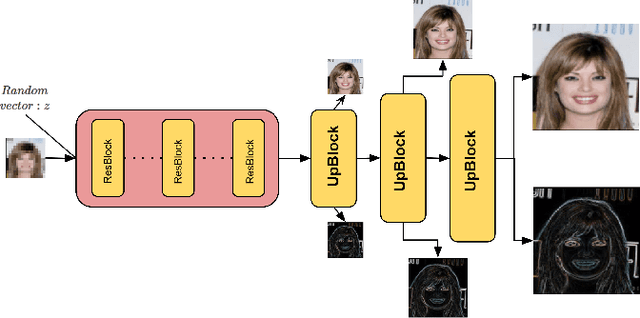
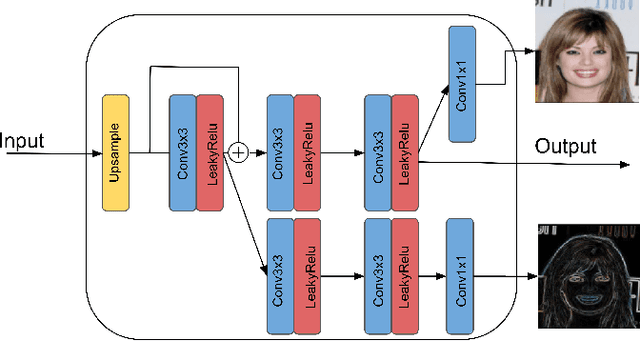
Traditionally, the main focus of image super-resolution techniques is on recovering the most likely high-quality images from low-quality images, using a one-to-one low- to high-resolution mapping. Proceeding that way, we ignore the fact that there are generally many valid versions of high-resolution images that map to a given low-resolution image. We are tackling in this work the problem of obtaining different high-resolution versions from the same low-resolution image using Generative Adversarial Models. Our learning approach makes use of high frequencies available in the training high-resolution images for preserving and exploring in an unsupervised manner the structural information available within these images. Experimental results on the CelebA dataset confirm the effectiveness of the proposed method, which allows the generation of both realistic and diverse high-resolution images from low-resolution images.
Persistent Mixture Model Networks for Few-Shot Image Classification
Nov 24, 2020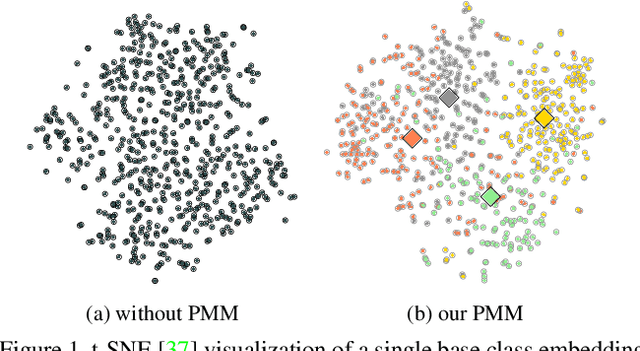
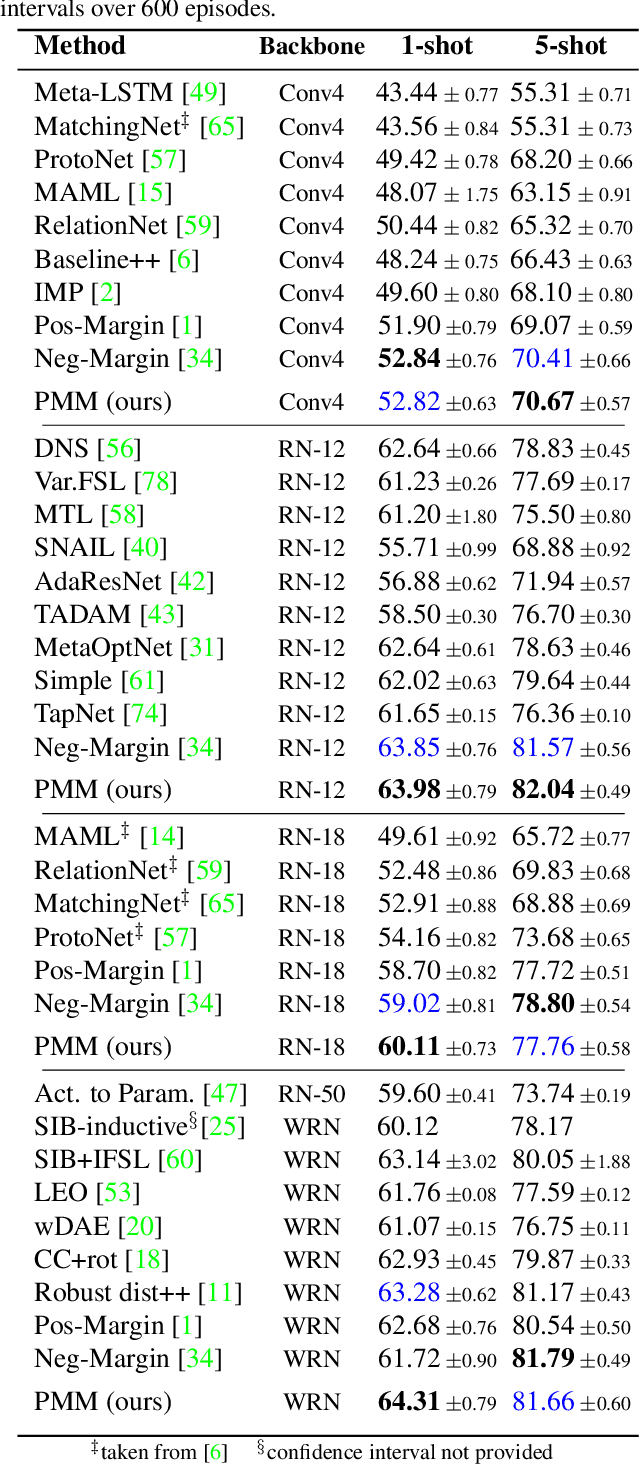
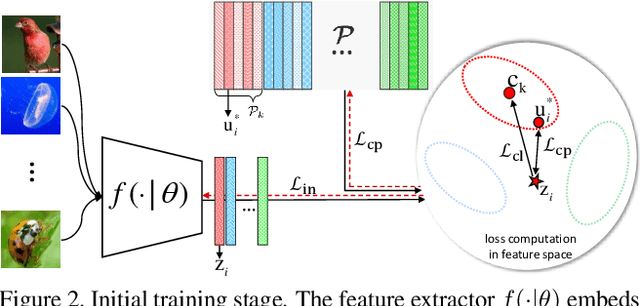
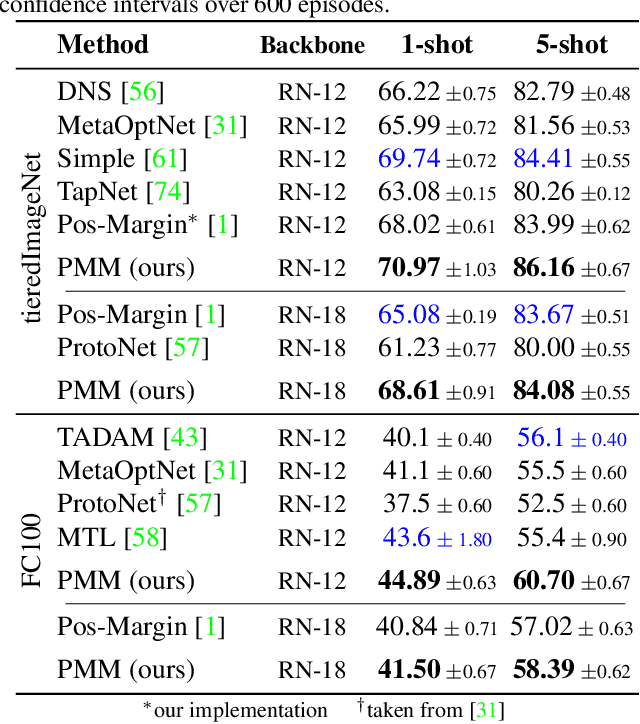
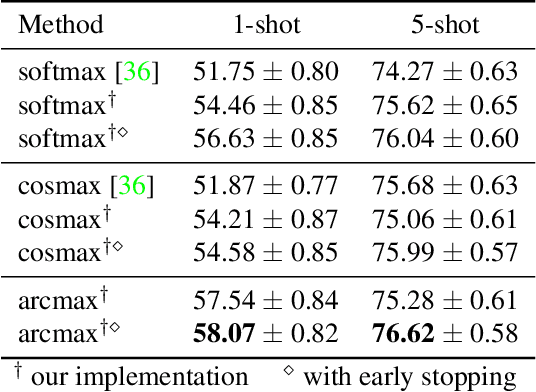
We introduce Persistent Mixture Model (PMM) networks for representation learning in the few-shot image classification context. While previous methods represent classes with a single centroid or rely on post hoc clustering methods, our method learns a mixture model for each base class jointly with the data representation in an end-to-end manner. The PMM training algorithm is organized into two main stages: 1) initial training and 2) progressive following. First, the initial estimate for multi-component mixtures is learned for each class in the base domain using a combination of two loss functions (competitive and collaborative). The resulting network is then progressively refined through a leader-follower learning procedure, which uses the current estimate of the learner as a fixed "target" network. This target network is used to make a consistent assignment of instances to mixture components, in order to increase performance while stabilizing the training. The effectiveness of our joint representation/mixture learning approach is demonstrated with extensive experiments on four standard datasets and four backbones. In particular, we demonstrate that when we combine our robust representation with recent alignment- and margin-based approaches, we achieve new state-of-the-art results in the inductive setting, with an absolute accuracy for 5-shot classification of 82.45% on miniImageNet, 88.20% with tieredImageNet, and 60.70% in FC100, all using the ResNet-12 backbone.
Beyond $\mathcal{H}$-Divergence: Domain Adaptation Theory With Jensen-Shannon Divergence
Jul 30, 2020



We reveal the incoherence between the widely-adopted empirical domain adversarial training and its generally-assumed theoretical counterpart based on $\mathcal{H}$-divergence. Concretely, we find that $\mathcal{H}$-divergence is not equivalent to Jensen-Shannon divergence, the optimization objective in domain adversarial training. To this end, we establish a new theoretical framework by directly proving the upper and lower target risk bounds based on joint distributional Jensen-Shannon divergence. We further derive bi-directional upper bounds for marginal and conditional shifts. Our framework exhibits inherent flexibilities for different transfer learning problems, which is usable for various scenarios where $\mathcal{H}$-divergence-based theory fails to adapt. From an algorithmic perspective, our theory enables a generic guideline unifying principles of semantic conditional matching, feature marginal matching, and label marginal shift correction. We employ algorithms for each principle and empirically validate the benefits of our framework on real datasets.
Input Dropout for Spatially Aligned Modalities
Feb 07, 2020



Computer vision datasets containing multiple modalities such as color, depth, and thermal properties are now commonly accessible and useful for solving a wide array of challenging tasks. However, deploying multi-sensor heads is not possible in many scenarios. As such many practical solutions tend to be based on simpler sensors, mostly for cost, simplicity and robustness considerations. In this work, we propose a training methodology to take advantage of these additional modalities available in datasets, even if they are not available at test time. By assuming that the modalities have a strong spatial correlation, we propose Input Dropout, a simple technique that consists in stochastic hiding of one or many input modalities at training time, while using only the canonical (e.g. RGB) modalities at test time. We demonstrate that Input Dropout trivially combines with existing deep convolutional architectures, and improves their performance on a wide range of computer vision tasks such as dehazing, 6-DOF object tracking, pedestrian detection and object classification.
Associative Alignment for Few-shot Image Classification
Dec 11, 2019

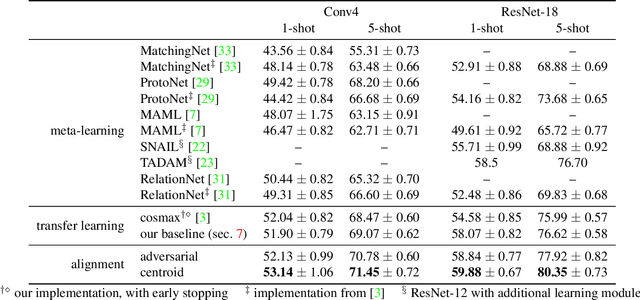
Few-shot image classification aims at training a model by using only a few (e.g., 5 or even 1) examples of novel classes. The established way of doing so is to rely on a larger set of base data for either pre-training a model, or for training in a meta-learning context. Unfortunately, these approaches often suffer from overfitting since the models can easily memorize all of the novel samples. This paper mitigates this issue and proposes to leverage part of the base data by aligning the novel training instances to the closely related ones in the base training set. This expands the size of the effective novel training set by adding extra related base instances to the few novel ones, thereby allowing to train the entire network. Doing so limits overfitting and simultaneously strengthens the generalization capabilities of the network. We propose two associative alignment strategies: 1) a conditional adversarial alignment loss based on the Wasserstein distance; and 2) a metric-learning loss for minimizing the distance between related base samples and the centroid of novel instances in the feature space. Experiments on two standard datasets demonstrate that combining our centroid-based alignment loss results in absolute accuracy improvements of 4.4%, 1.2%, and 6.0% in 5-shot learning over the state of the art for object recognition, fine-grained classification, and cross-domain adaptation, respectively.
Deep Active Learning: Unified and Principled Method for Query and Training
Nov 20, 2019


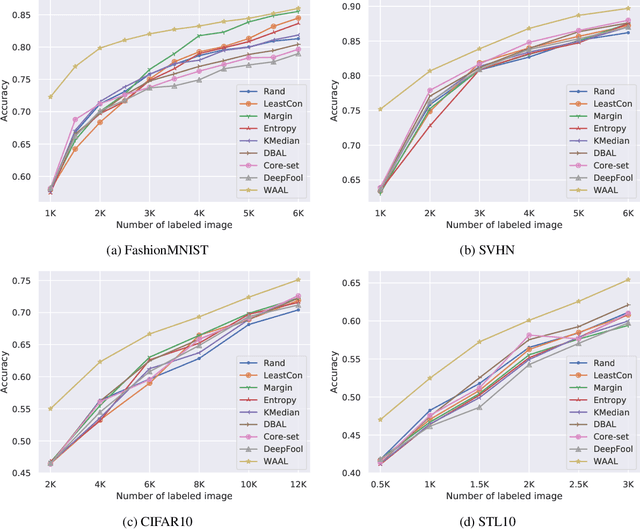
In this paper, we proposed a unified and principled method for both querying and training process in deep batch active learning. We provided the theoretical insights from the intuition of modeling the interactive procedure in active learning as distribution matching, by adopting Wasserstein distance. As a consequence, we derived a new training loss from the theoretical analysis, which is decomposed into optimizing deep neural network parameter and batch query selection through alternative optimization. In addition, the loss for training deep neural network is naturally formulated as a min-max optimization problem through leveraging the unlabeled data information. Moreover, the proposed principles also indicate an explicit uncertainty-diversity trade-off in the query batch selection. Finally we evaluated our proposed method for different benchmarks, showing consistently better empirical performances and more time efficient query strategy, comparing to several baselines.
Deep Parametric Indoor Lighting Estimation
Oct 19, 2019

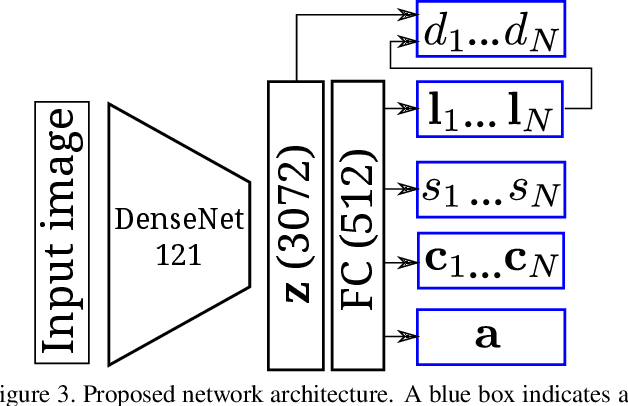

We present a method to estimate lighting from a single image of an indoor scene. Previous work has used an environment map representation that does not account for the localized nature of indoor lighting. Instead, we represent lighting as a set of discrete 3D lights with geometric and photometric parameters. We train a deep neural network to regress these parameters from a single image, on a dataset of environment maps annotated with depth. We propose a differentiable layer to convert these parameters to an environment map to compute our loss; this bypasses the challenge of establishing correspondences between estimated and ground truth lights. We demonstrate, via quantitative and qualitative evaluations, that our representation and training scheme lead to more accurate results compared to previous work, while allowing for more realistic 3D object compositing with spatially-varying lighting.
Unsupervised Temperature Scaling: Post-Processing Unsupervised Calibration of Deep Models Decisions
May 08, 2019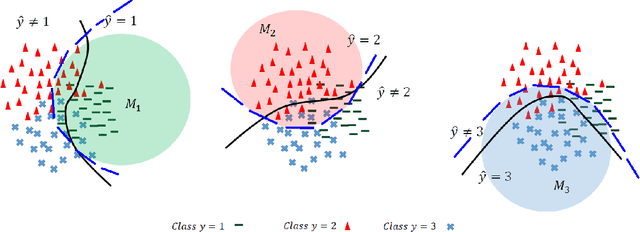
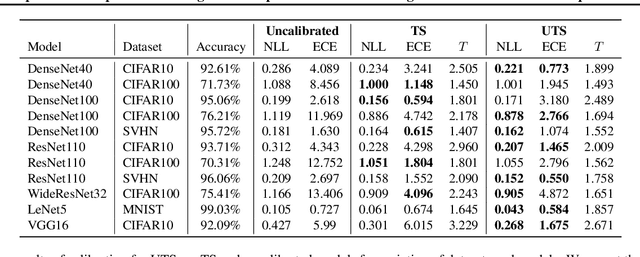
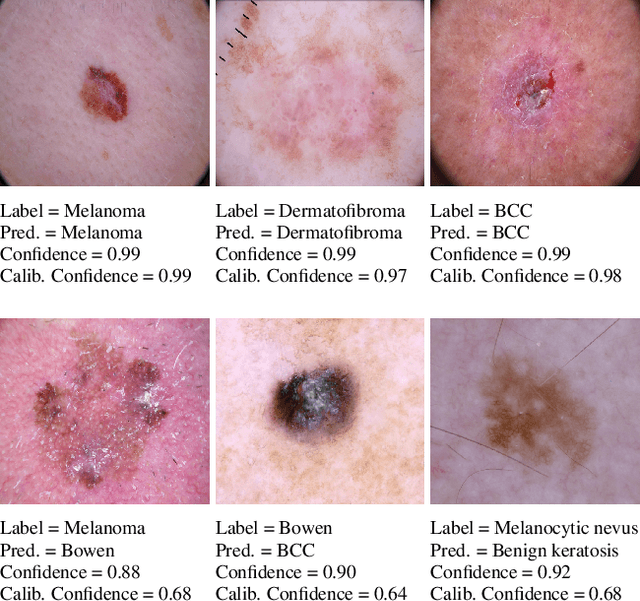

Great performances of deep learning are undeniable, with impressive results on wide range of tasks. However, the output confidence of these models is usually not well calibrated, which can be an issue for applications where confidence on the decisions is central to bring trust and reliability (e.g., autonomous driving or medical diagnosis). For models using softmax at the last layer, Temperature Scaling (TS) is a state-of-the-art calibration method, with low time and memory complexity as well as demonstrated effectiveness.TS relies on a T parameter to rescale and calibrate values of the softmax layer, using a labelled dataset to determine the value of that parameter.We are proposing an Unsupervised Temperature Scaling (UTS) approach, which does not dependent on labelled samples to calibrate the model,allowing, for example, using a part of test samples for calibrating the pre-trained model before going into inference mode. We provide theoretical justifications for UTS and assess its effectiveness on the wide range of deep models and datasets. We also demonstrate calibration results of UTS on skin lesion detection, a problem where a well-calibrated output can play an important role for accurate decision-making.
A Principled Approach for Learning Task Similarity in Multitask Learning
Mar 21, 2019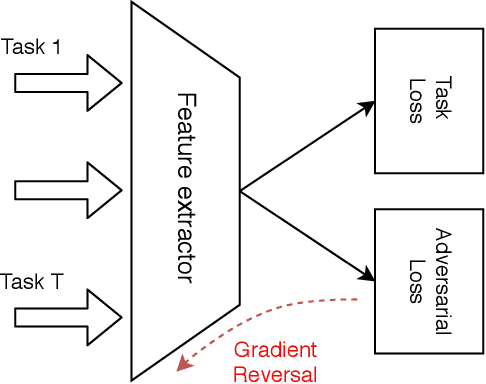

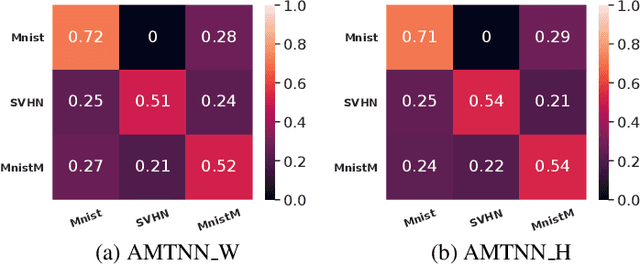
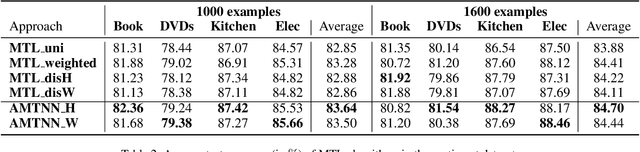
Multitask learning aims at solving a set of related tasks simultaneously, by exploiting the shared knowledge for improving the performance on individual tasks. Hence, an important aspect of multitask learning is to understand the similarities within a set of tasks. Previous works have incorporated this similarity information explicitly (e.g., weighted loss for each task) or implicitly (e.g., adversarial loss for feature adaptation), for achieving good empirical performances. However, the theoretical motivations for adding task similarity knowledge are often missing or incomplete. In this paper, we give a different perspective from a theoretical point of view to understand this practice. We first provide an upper bound on the generalization error of multitask learning, showing the benefit of explicit and implicit task similarity knowledge. We systematically derive the bounds based on two distinct task similarity metrics: H divergence and Wasserstein distance. From these theoretical results, we revisit the Adversarial Multi-task Neural Network, proposing a new training algorithm to learn the task relation coefficients and neural network parameters iteratively. We assess our new algorithm empirically on several benchmarks, showing not only that we find interesting and robust task relations, but that the proposed approach outperforms the baselines, reaffirming the benefits of theoretical insight in algorithm design.
Learning of Image Dehazing Models for Segmentation Tasks
Mar 04, 2019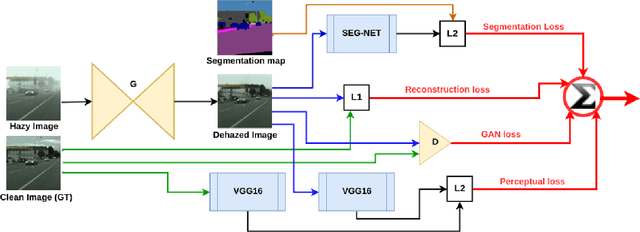
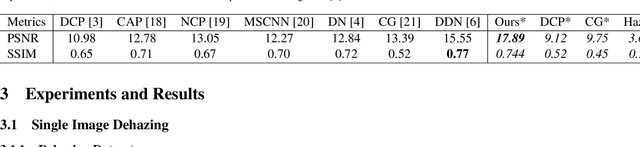

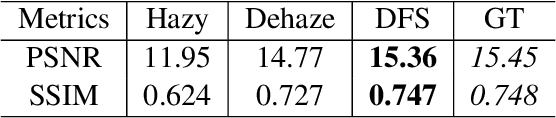
To evaluate their performance, existing dehazing approaches generally rely on distance measures between the generated image and its corresponding ground truth. Despite its ability to produce visually good images, using pixel-based or even perceptual metrics do not guarantee, in general, that the produced image is fit for being used as input for low-level computer vision tasks such as segmentation. To overcome this weakness, we are proposing a novel end-to-end approach for image dehazing, fit for being used as input to an image segmentation procedure, while maintaining the visual quality of the generated images. Inspired by the success of Generative Adversarial Networks (GAN), we propose to optimize the generator by introducing a discriminator network and a loss function that evaluates segmentation quality of dehazed images. In addition, we make use of a supplementary loss function that verifies that the visual and the perceptual quality of the generated image are preserved in hazy conditions. Results obtained using the proposed technique are appealing, with a favorable comparison to state-of-the-art approaches when considering the performance of segmentation algorithms on the hazy images.