 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparable Expert Architecture: Toward Privacy-Preserving LLM Personalization via Composable Adapters and Deletable User Proxies
Apr 23, 2026Current model training approaches incorporate user information directly into shared weights, making individual data removal computationally infeasible without retraining. This paper presents a three-layer architecture that decouples personal data from shared weights by combining a static base model, composable domain-expert LoRA adapters that shape behavior without imparting user data, and per-user proxy artefacts whose deletion constitutes deterministic unlearning. Evaluation on Phi-3.5-mini and Llama-3.1-8B confirms per-user differentiation in which personal data influences outputs while remaining isolated, verified by a return to baseline after proxy removal (KL divergence of approximately 0.21 nats, 82-89% verification pass rate) and near-zero cross-user contamination. Because user-specific information never enters shared weights, the architecture mitigates model inversion, membership inference, and training-data extraction against shared model components by construction. The approach converts machine unlearning from an intractable weight-editing problem into a deterministic deletion operation that preserves personalization alongside privacy-enhancing guarantees and is compatible with differentially private stochastic gradient descent (DP-SGD) for privacy-preserving shared model improvement.
Verifiable Semantics for Agent-to-Agent Communication
Feb 18, 2026Multiagent AI systems require consistent communication, but we lack methods to verify that agents share the same understanding of the terms used. Natural language is interpretable but vulnerable to semantic drift, while learned protocols are efficient but opaque. We propose a certification protocol based on the stimulus-meaning model, where agents are tested on shared observable events and terms are certified if empirical disagreement falls below a statistical threshold. In this protocol, agents restricting their reasoning to certified terms ("core-guarded reasoning") achieve provably bounded disagreement. We also outline mechanisms for detecting drift (recertification) and recovering shared vocabulary (renegotiation). In simulations with varying degrees of semantic divergence, core-guarding reduces disagreement by 72-96%. In a validation with fine-tuned language models, disagreement is reduced by 51%. Our framework provides a first step towards verifiable agent-to-agent communication.
Autonomous Fault Detection in Self-Healing Systems using Restricted Boltzmann Machines
Jan 07, 2015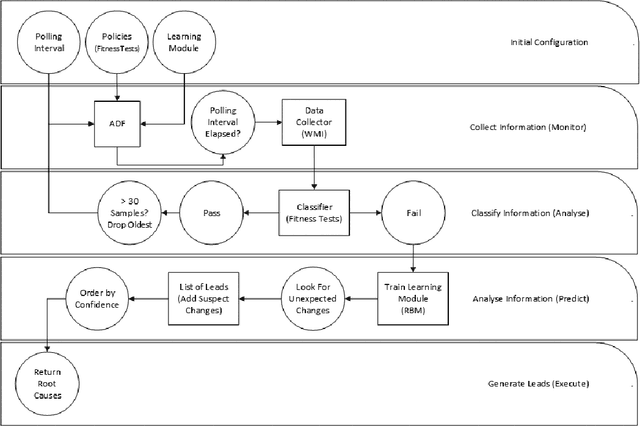
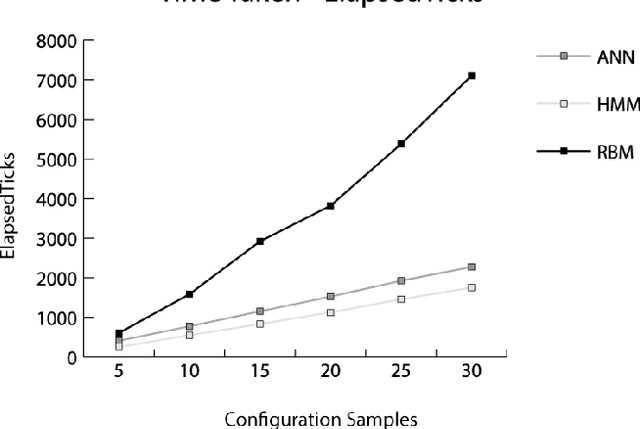
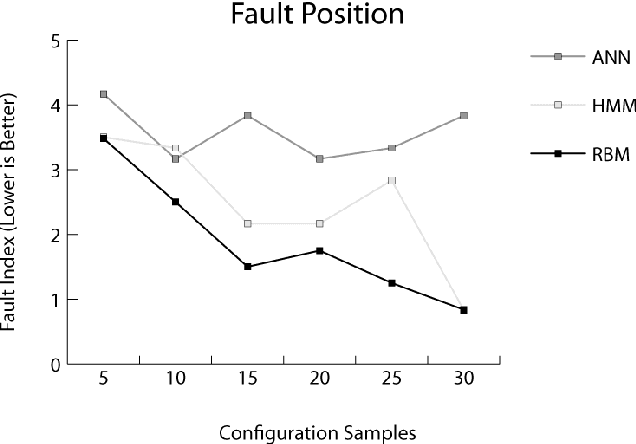
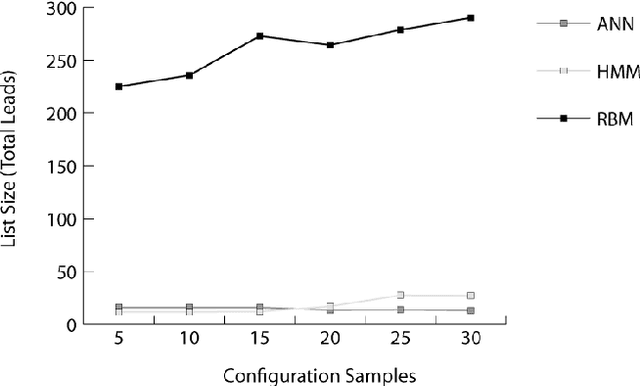
Autonomously detecting and recovering from faults is one approach for reducing the operational complexity and costs associated with managing computing environments. We present a novel methodology for autonomously generating investigation leads that help identify systems faults, and extends our previous work in this area by leveraging Restricted Boltzmann Machines (RBMs) and contrastive divergence learning to analyse changes in historical feature data. This allows us to heuristically identify the root cause of a fault, and demonstrate an improvement to the state of the art by showing feature data can be predicted heuristically beyond a single instance to include entire sequences of information.