 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Granular Grassmannian Clustering Framework via the Schubert Variety of Best Fit
Dec 29, 2025In many classification and clustering tasks, it is useful to compute a geometric representative for a dataset or a cluster, such as a mean or median. When datasets are represented by subspaces, these representatives become points on the Grassmann or flag manifold, with distances induced by their geometry, often via principal angles. We introduce a subspace clustering algorithm that replaces subspace means with a trainable prototype defined as a Schubert Variety of Best Fit (SVBF) - a subspace that comes as close as possible to intersecting each cluster member in at least one fixed direction. Integrated in the Linde-Buzo-Grey (LBG) pipeline, this SVBF-LBG scheme yields improved cluster purity on synthetic, image, spectral, and video action data, while retaining the mathematical structure required for downstream analysis.
ReLU Neural Networks, Polyhedral Decompositions, and Persistent Homolog
Jun 30, 2023



A ReLU neural network leads to a finite polyhedral decomposition of input space and a corresponding finite dual graph. We show that while this dual graph is a coarse quantization of input space, it is sufficiently robust that it can be combined with persistent homology to detect homological signals of manifolds in the input space from samples. This property holds for a variety of networks trained for a wide range of purposes that have nothing to do with this topological application. We found this feature to be surprising and interesting; we hope it will also be useful.
The Flag Median and FlagIRLS
Mar 08, 2022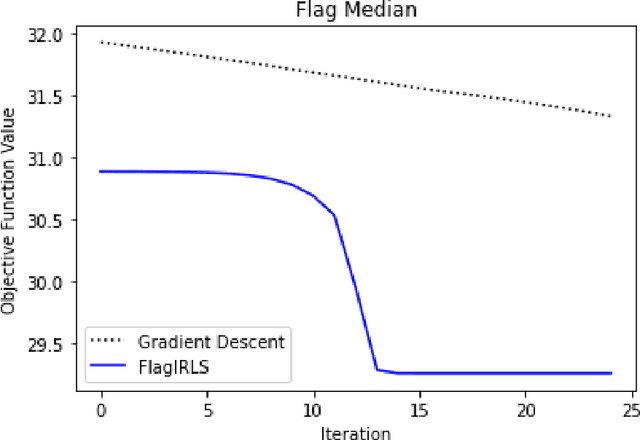
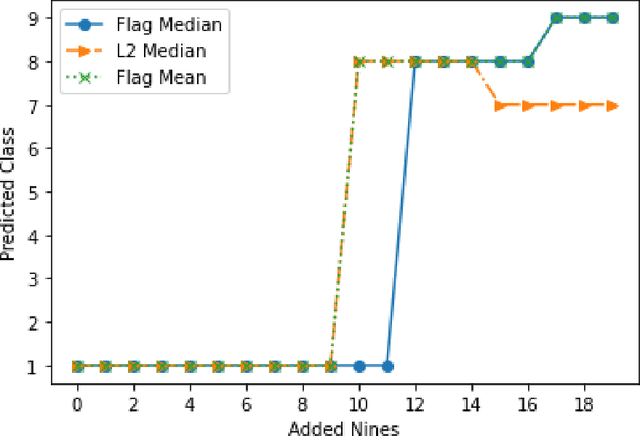
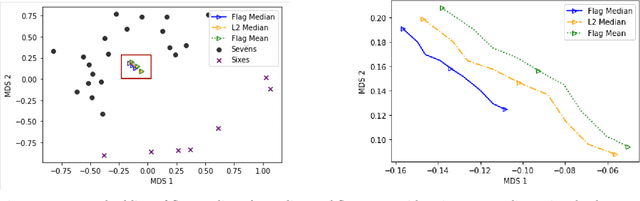
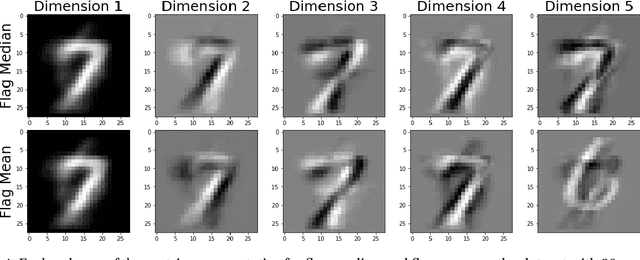
Finding prototypes (e.g., mean and median) for a dataset is central to a number of common machine learning algorithms. Subspaces have been shown to provide useful, robust representations for datasets of images, videos and more. Since subspaces correspond to points on a Grassmann manifold, one is led to consider the idea of a subspace prototype for a Grassmann-valued dataset. While a number of different subspace prototypes have been described, the calculation of some of these prototypes has proven to be computationally expensive while other prototypes are affected by outliers and produce highly imperfect clustering on noisy data. This work proposes a new subspace prototype, the flag median, and introduces the FlagIRLS algorithm for its calculation. We provide evidence that the flag median is robust to outliers and can be used effectively in algorithms like Linde-Buzo-Grey (LBG) to produce improved clusterings on Grassmannians. Numerical experiments include a synthetic dataset, the MNIST handwritten digits dataset, the Mind's Eye video dataset and the UCF YouTube action dataset. The flag median is compared the other leading algorithms for computing prototypes on the Grassmannian, namely, the $\ell_2$-median and to the flag mean. We find that using FlagIRLS to compute the flag median converges in $4$ iterations on a synthetic dataset. We also see that Grassmannian LBG with a codebook size of $20$ and using the flag median produces at least a $10\%$ improvement in cluster purity over Grassmannian LBG using the flag mean or $\ell_2$-median on the Mind's Eye dataset.
Supporting Massive DLRM Inference Through Software Defined Memory
Nov 08, 2021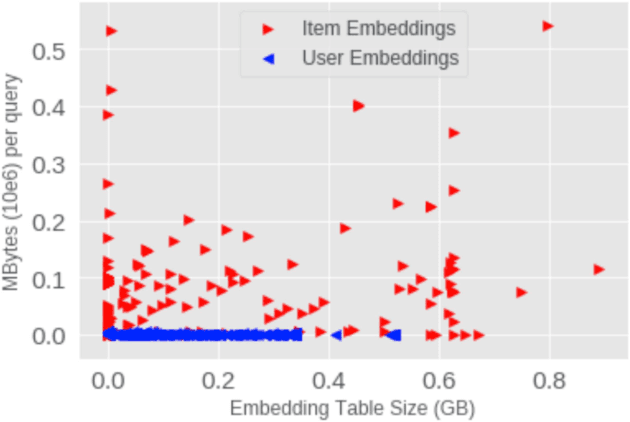

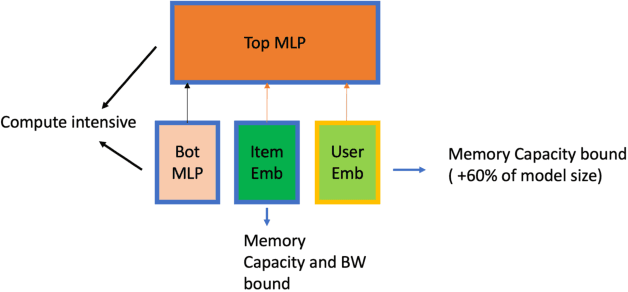

Deep Learning Recommendation Models (DLRM) are widespread, account for a considerable data center footprint, and grow by more than 1.5x per year. With model size soon to be in terabytes range, leveraging Storage ClassMemory (SCM) for inference enables lower power consumption and cost. This paper evaluates the major challenges in extending the memory hierarchy to SCM for DLRM, and presents different techniques to improve performance through a Software Defined Memory. We show how underlying technologies such as Nand Flash and 3DXP differentiate, and relate to real world scenarios, enabling from 5% to 29% power savings.
Locally Linear Attributes of ReLU Neural Networks
Nov 30, 2020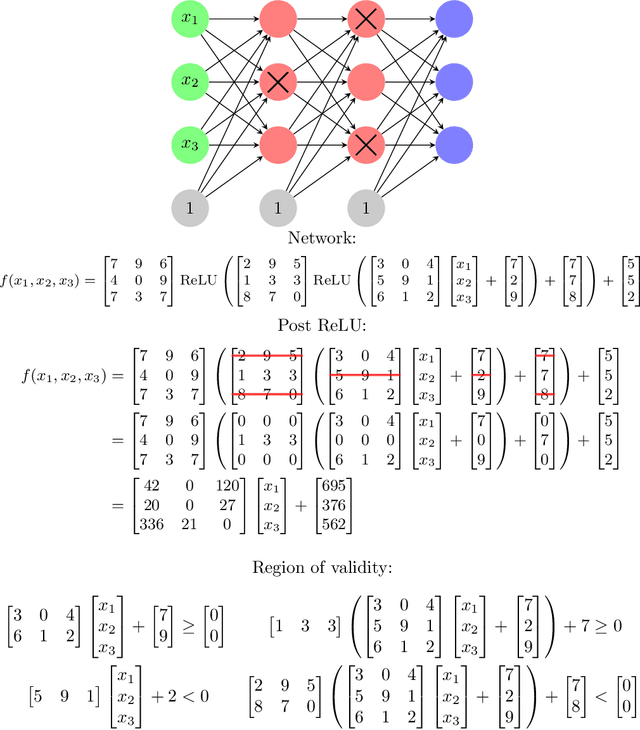
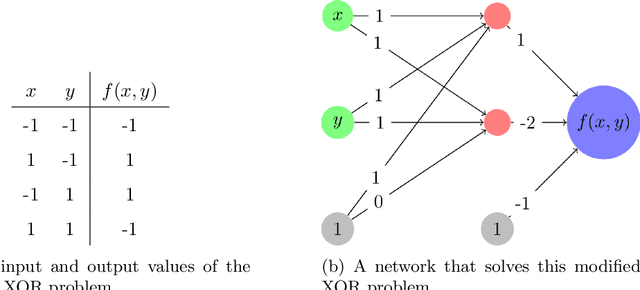
A ReLU neural network determines/is a continuous piecewise linear map from an input space to an output space. The weights in the neural network determine a decomposition of the input space into convex polytopes and on each of these polytopes the network can be described by a single affine mapping. The structure of the decomposition, together with the affine map attached to each polytope, can be analyzed to investigate the behavior of the associated neural network.
The flag manifold as a tool for analyzing and comparing data sets
Jun 24, 2020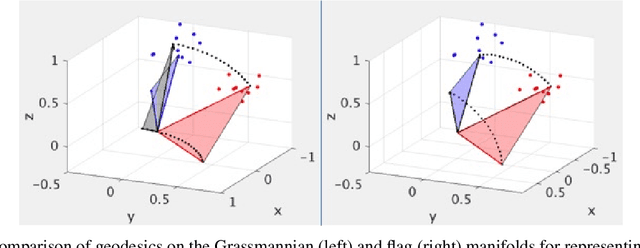
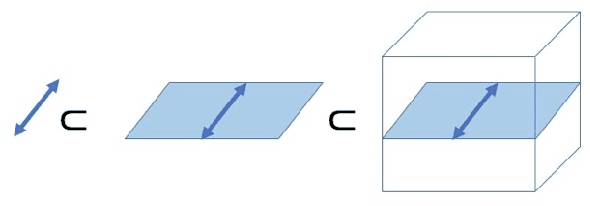
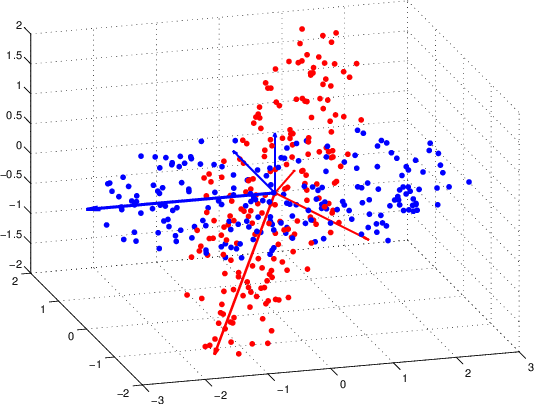
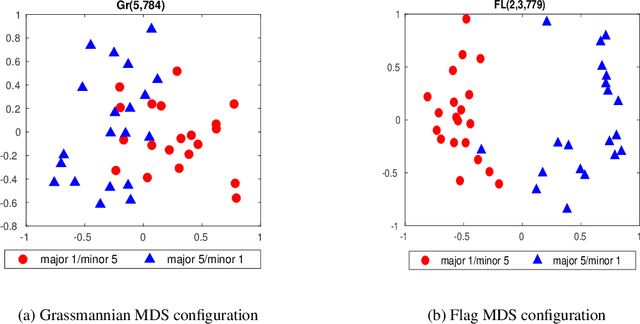
The shape and orientation of data clouds reflect variability in observations that can confound pattern recognition systems. Subspace methods, utilizing Grassmann manifolds, have been a great aid in dealing with such variability. However, this usefulness begins to falter when the data cloud contains sufficiently many outliers corresponding to stray elements from another class or when the number of data points is larger than the number of features. We illustrate how nested subspace methods, utilizing flag manifolds, can help to deal with such additional confounding factors. Flag manifolds, which are parameter spaces for nested subspaces, are a natural geometric generalization of Grassmann manifolds. To make practical comparisons on a flag manifold, algorithms are proposed for determining the distances between points $[A], [B]$ on a flag manifold, where $A$ and $B$ are arbitrary orthogonal matrix representatives for $[A]$ and $[B]$, and for determining the initial direction of these minimal length geodesics. The approach is illustrated in the context of (hyper) spectral imagery showing the impact of ambient dimension, sample dimension, and flag structure.
More chemical detection through less sampling: amplifying chemical signals in hyperspectral data cubes through compressive sensing
Jun 27, 2019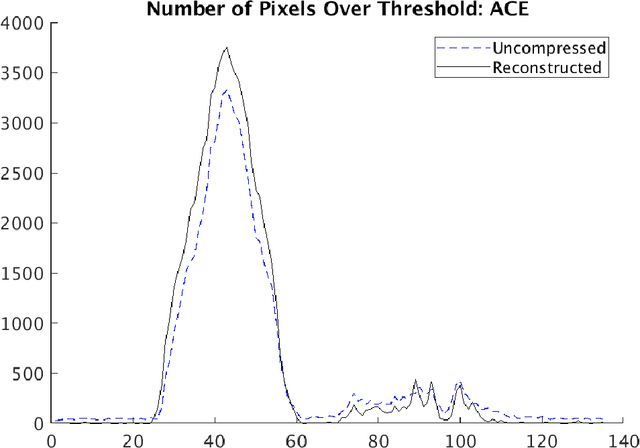
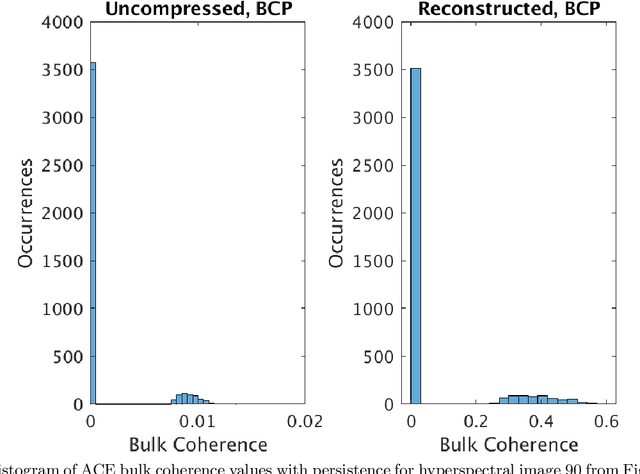
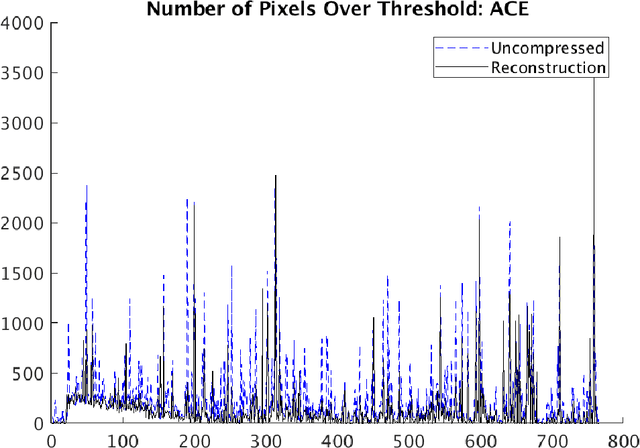
Compressive sensing (CS) is a method of sampling which permits some classes of signals to be reconstructed with high accuracy even when they were under-sampled. In this paper we explore a phenomenon in which bandwise CS sampling of a hyperspectral data cube followed by reconstruction can actually result in amplification of chemical signals contained in the cube. Perhaps most surprisingly, chemical signal amplification generally seems to increase as the level of sampling decreases. In some examples, the chemical signal is significantly stronger in a data cube reconstructed from 10% CS sampling than it is in the raw, 100% sampled data cube. We explore this phenomenon in two real-world datasets including the Physical Sciences Inc. Fabry-P\'{e}rot interferometer sensor multispectral dataset and the Johns Hopkins Applied Physics Lab FTIR-based longwave infrared sensor hyperspectral dataset. Each of these datasets contains the release of a chemical simulant, such as glacial acetic acid, triethyl phospate, and sulfur hexafluoride, and in all cases we use the adaptive coherence estimator (ACE) to detect a target signal in the hyperspectral data cube. We end the paper by suggesting some theoretical justifications for why chemical signals would be amplified in CS sampled and reconstructed hyperspectral data cubes and discuss some practical implications.
A data-driven approach to sampling matrix selection for compressive sensing
Jun 20, 2019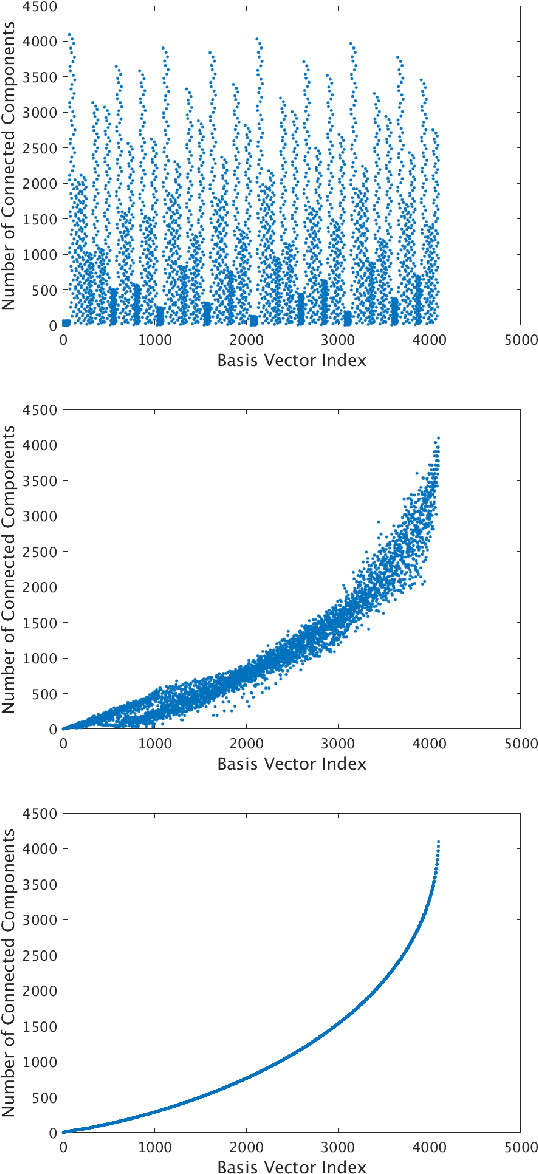
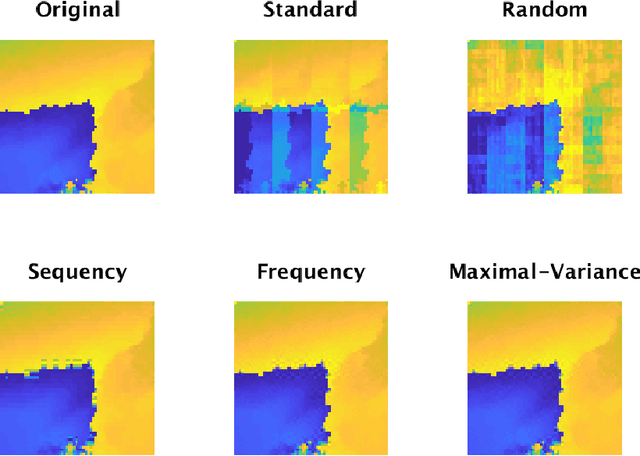
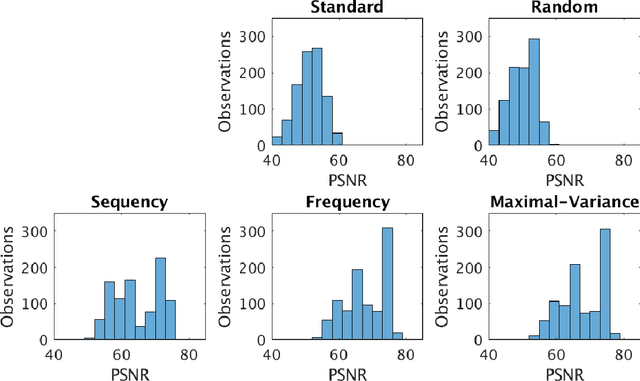
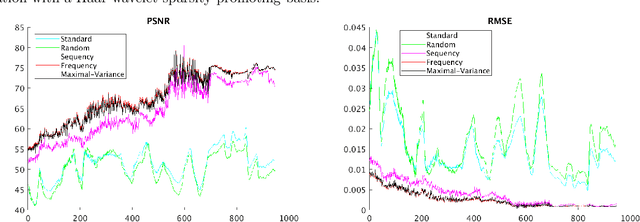
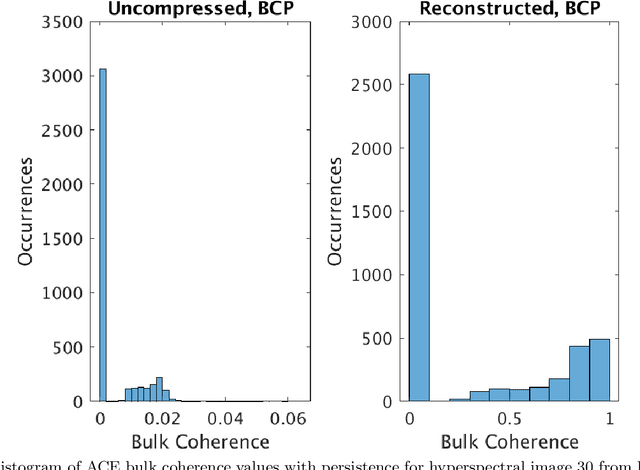
Sampling is a fundamental aspect of any implementation of compressive sensing. Typically, the choice of sampling method is guided by the reconstruction basis. However, this approach can be problematic with respect to certain hardware constraints and is not responsive to domain-specific context. We propose a method for defining an order for a sampling basis that is optimal with respect to capturing variance in data, thus allowing for meaningful sensing at any desired level of compression. We focus on the Walsh-Hadamard sampling basis for its relevance to hardware constraints, but our approach applies to any sampling basis of interest. We illustrate the effectiveness of our method on the Physical Sciences Inc. Fabry-P\'{e}rot interferometer sensor multispectral dataset, the Johns Hopkins Applied Physics Lab FTIR-based longwave infrared sensor hyperspectral dataset, and a Colorado State University Swiss Ranger depth image dataset. The spectral datasets consist of simulant experiments, including releases of chemicals such as GAA and SF6. We combine our sampling and reconstruction with the adaptive coherence estimator (ACE) and bulk coherence for chemical detection and we incorporate an algorithmic threshold for ACE values to determine the presence or absence of a chemical. We compare results across sampling methods in this context. We have successful chemical detection at a compression rate of 90%. For all three datasets, we compare our sampling approach to standard orderings of sampling basis such as random, sequency, and an analog of sequency that we term `frequency.' In one instance, the peak signal to noise ratio was improved by over 30% across a test set of depth images.
Monitoring the shape of weather, soundscapes, and dynamical systems: a new statistic for dimension-driven data analysis on large data sets
Oct 27, 2018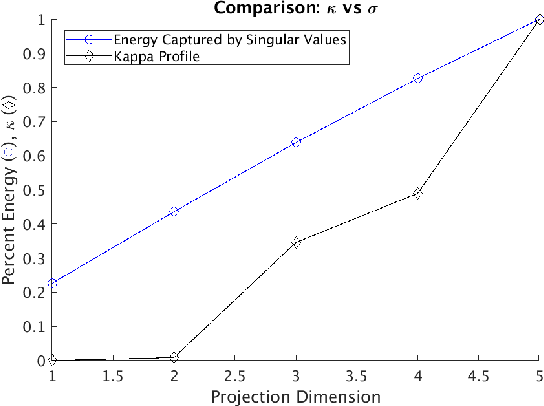
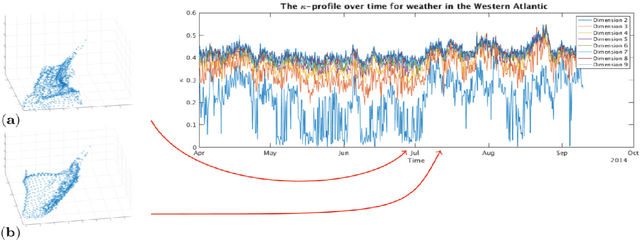
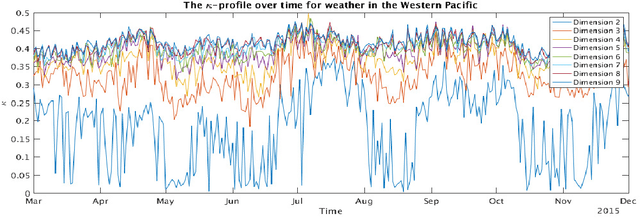
Dimensionality-reduction methods are a fundamental tool in the analysis of large data sets. These algorithms work on the assumption that the "intrinsic dimension" of the data is generally much smaller than the ambient dimension in which it is collected. Alongside their usual purpose of mapping data into a smaller dimension with minimal information loss, dimensionality-reduction techniques implicitly or explicitly provide information about the dimension of the data set. In this paper, we propose a new statistic that we call the $\kappa$-profile for analysis of large data sets. The $\kappa$-profile arises from a dimensionality-reduction optimization problem: namely that of finding a projection into $k$-dimensions that optimally preserves the secants between points in the data set. From this optimal projection we extract $\kappa,$ the norm of the shortest projected secant from among the set of all normalized secants. This $\kappa$ can be computed for any $k$; thus the tuple of $\kappa$ values (indexed by dimension) becomes a $\kappa$-profile. Algorithms such as the Secant-Avoidance Projection algorithm and the Hierarchical Secant-Avoidance Projection algorithm, provide a computationally feasible means of estimating the $\kappa$-profile for large data sets, and thus a method of understanding and monitoring their behavior. As we demonstrate in this paper, the $\kappa$-profile serves as a useful statistic in several representative settings: weather data, soundscape data, and dynamical systems data.
Too many secants: a hierarchical approach to secant-based dimensionality reduction on large data sets
Aug 05, 2018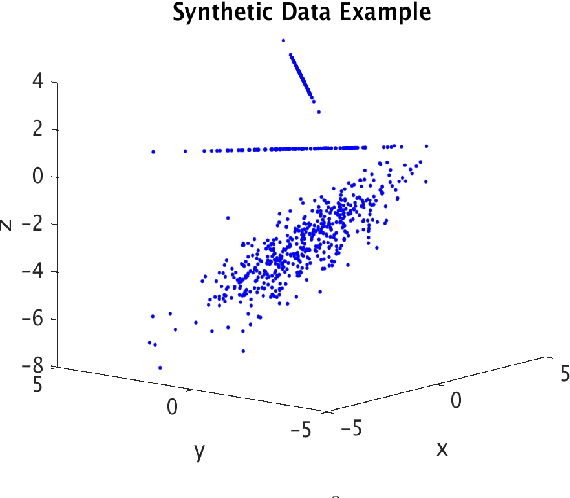
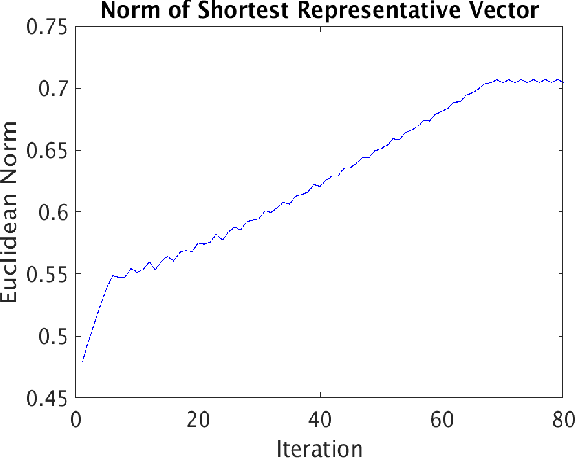

A fundamental question in many data analysis settings is the problem of discerning the "natural" dimension of a data set. That is, when a data set is drawn from a manifold (possibly with noise), a meaningful aspect of the data is the dimension of that manifold. Various approaches exist for estimating this dimension, such as the method of Secant-Avoidance Projection (SAP). Intuitively, the SAP algorithm seeks to determine a projection which best preserves the lengths of all secants between points in a data set; by applying the algorithm to find the best projections to vector spaces of various dimensions, one may infer the dimension of the manifold of origination. That is, one may learn the dimension at which it is possible to construct a diffeomorphic copy of the data in a lower-dimensional Euclidean space. Using Whitney's embedding theorem, we can relate this information to the natural dimension of the data. A drawback of the SAP algorithm is that a data set with $T$ points has $O(T^2)$ secants, making the computation and storage of all secants infeasible for very large data sets. In this paper, we propose a novel algorithm that generalizes the SAP algorithm with an emphasis on addressing this issue. That is, we propose a hierarchical secant-based dimensionality-reduction method, which can be employed for data sets where explicitly calculating all secants is not feasible.