 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Overcomplete Word Vector Representations
Jun 05, 2015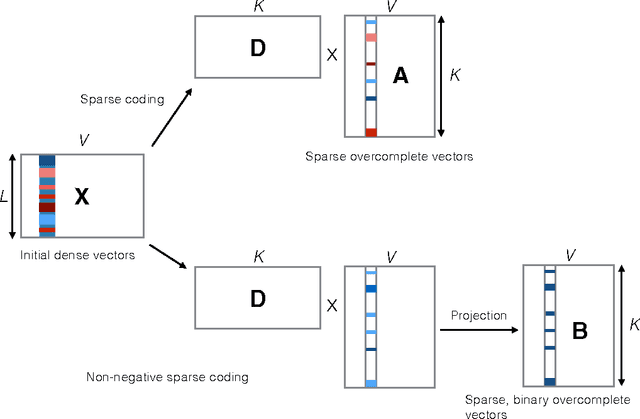
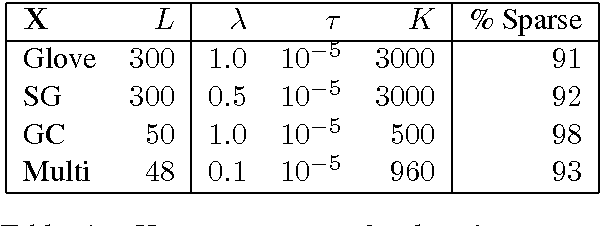
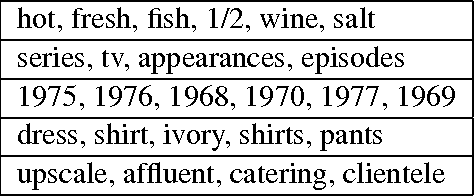
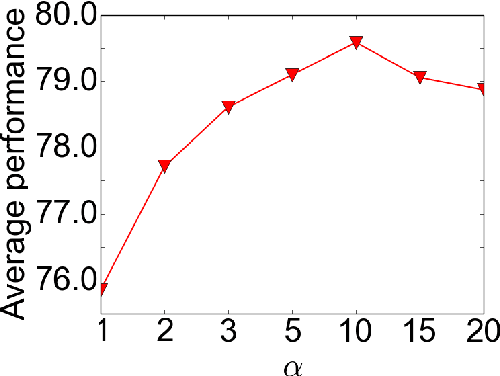
Current distributed representations of words show little resemblance to theories of lexical semantics. The former are dense and uninterpretable, the latter largely based on familiar, discrete classes (e.g., supersenses) and relations (e.g., synonymy and hypernymy). We propose methods that transform word vectors into sparse (and optionally binary) vectors. The resulting representations are more similar to the interpretable features typically used in NLP, though they are discovered automatically from raw corpora. Because the vectors are highly sparse, they are computationally easy to work with. Most importantly, we find that they outperform the original vectors on benchmark tasks.
Transition-Based Dependency Parsing with Stack Long Short-Term Memory
May 29, 2015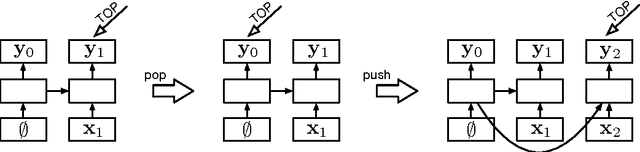
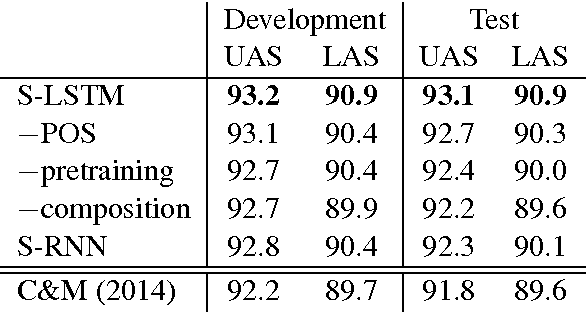
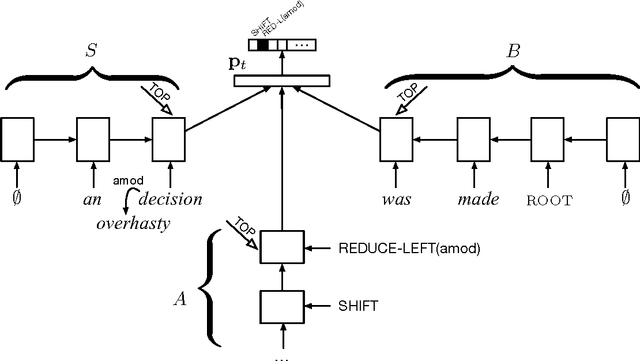
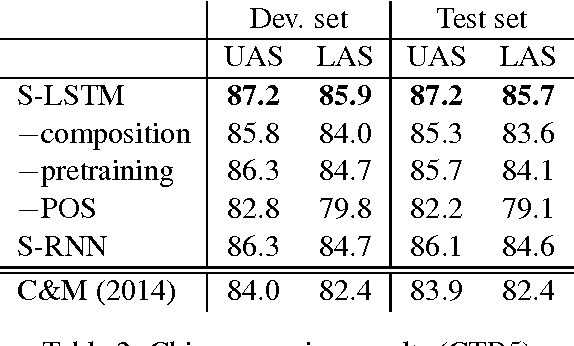
We propose a technique for learning representations of parser states in transition-based dependency parsers. Our primary innovation is a new control structure for sequence-to-sequence neural networks---the stack LSTM. Like the conventional stack data structures used in transition-based parsing, elements can be pushed to or popped from the top of the stack in constant time, but, in addition, an LSTM maintains a continuous space embedding of the stack contents. This lets us formulate an efficient parsing model that captures three facets of a parser's state: (i) unbounded look-ahead into the buffer of incoming words, (ii) the complete history of actions taken by the parser, and (iii) the complete contents of the stack of partially built tree fragments, including their internal structures. Standard backpropagation techniques are used for training and yield state-of-the-art parsing performance.
Unsupervised POS Induction with Word Embeddings
Mar 23, 2015
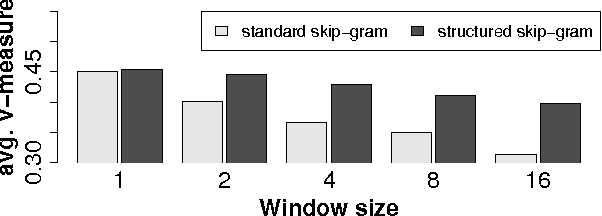
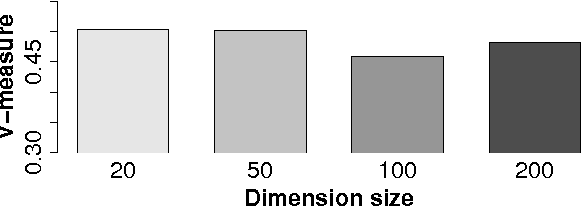
Unsupervised word embeddings have been shown to be valuable as features in supervised learning problems; however, their role in unsupervised problems has been less thoroughly explored. In this paper, we show that embeddings can likewise add value to the problem of unsupervised POS induction. In two representative models of POS induction, we replace multinomial distributions over the vocabulary with multivariate Gaussian distributions over word embeddings and observe consistent improvements in eight languages. We also analyze the effect of various choices while inducing word embeddings on "downstream" POS induction results.
Retrofitting Word Vectors to Semantic Lexicons
Mar 22, 2015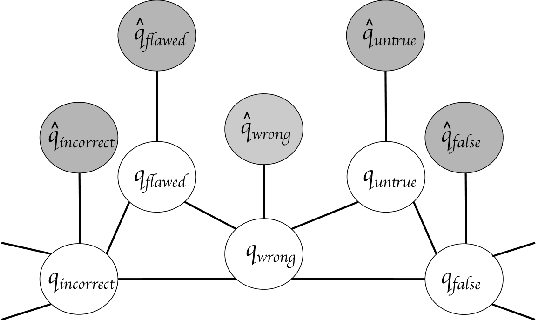
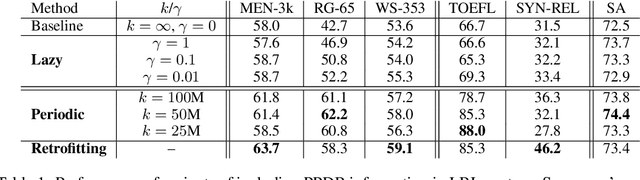
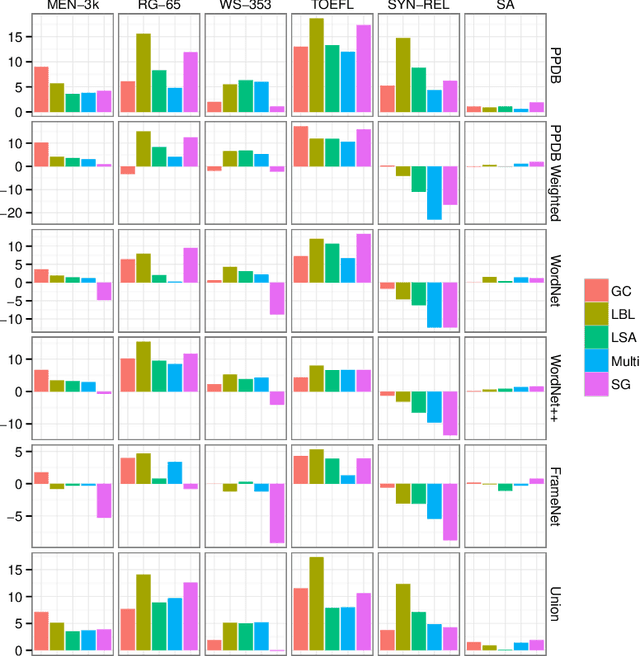
Vector space word representations are learned from distributional information of words in large corpora. Although such statistics are semantically informative, they disregard the valuable information that is contained in semantic lexicons such as WordNet, FrameNet, and the Paraphrase Database. This paper proposes a method for refining vector space representations using relational information from semantic lexicons by encouraging linked words to have similar vector representations, and it makes no assumptions about how the input vectors were constructed. Evaluated on a battery of standard lexical semantic evaluation tasks in several languages, we obtain substantial improvements starting with a variety of word vector models. Our refinement method outperforms prior techniques for incorporating semantic lexicons into the word vector training algorithms.
Conditional Random Field Autoencoders for Unsupervised Structured Prediction
Nov 10, 2014
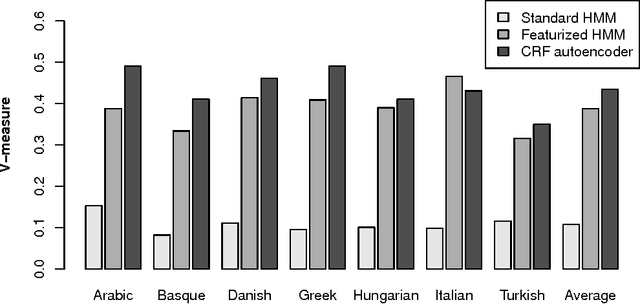
We introduce a framework for unsupervised learning of structured predictors with overlapping, global features. Each input's latent representation is predicted conditional on the observable data using a feature-rich conditional random field. Then a reconstruction of the input is (re)generated, conditional on the latent structure, using models for which maximum likelihood estimation has a closed-form. Our autoencoder formulation enables efficient learning without making unrealistic independence assumptions or restricting the kinds of features that can be used. We illustrate insightful connections to traditional autoencoders, posterior regularization and multi-view learning. We show competitive results with instantiations of the model for two canonical NLP tasks: part-of-speech induction and bitext word alignment, and show that training our model can be substantially more efficient than comparable feature-rich baselines.
Learning Word Representations with Hierarchical Sparse Coding
Nov 06, 2014
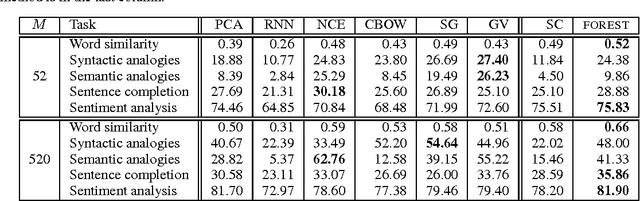

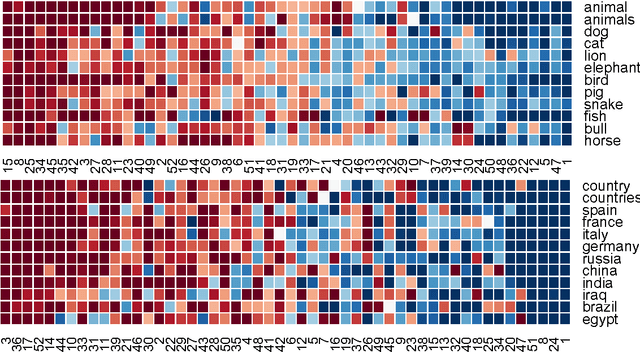
We propose a new method for learning word representations using hierarchical regularization in sparse coding inspired by the linguistic study of word meanings. We show an efficient learning algorithm based on stochastic proximal methods that is significantly faster than previous approaches, making it possible to perform hierarchical sparse coding on a corpus of billions of word tokens. Experiments on various benchmark tasks---word similarity ranking, analogies, sentence completion, and sentiment analysis---demonstrate that the method outperforms or is competitive with state-of-the-art methods. Our word representations are available at \url{http://www.ark.cs.cmu.edu/dyogatam/wordvecs/}.
Notes on Noise Contrastive Estimation and Negative Sampling
Oct 30, 2014Estimating the parameters of probabilistic models of language such as maxent models and probabilistic neural models is computationally difficult since it involves evaluating partition functions by summing over an entire vocabulary, which may be millions of word types in size. Two closely related strategies---noise contrastive estimation (Mnih and Teh, 2012; Mnih and Kavukcuoglu, 2013; Vaswani et al., 2013) and negative sampling (Mikolov et al., 2012; Goldberg and Levy, 2014)---have emerged as popular solutions to this computational problem, but some confusion remains as to which is more appropriate and when. This document explicates their relationships to each other and to other estimation techniques. The analysis shows that, although they are superficially similar, NCE is a general parameter estimation technique that is asymptotically unbiased, while negative sampling is best understood as a family of binary classification models that are useful for learning word representations but not as a general-purpose estimator.
Language Modeling with Power Low Rank Ensembles
Oct 03, 2014
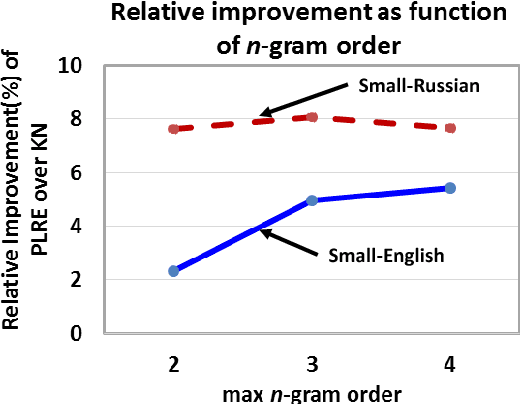
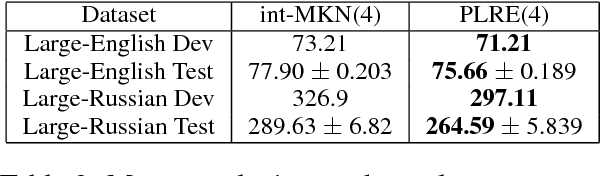

We present power low rank ensembles (PLRE), a flexible framework for n-gram language modeling where ensembles of low rank matrices and tensors are used to obtain smoothed probability estimates of words in context. Our method can be understood as a generalization of n-gram modeling to non-integer n, and includes standard techniques such as absolute discounting and Kneser-Ney smoothing as special cases. PLRE training is efficient and our approach outperforms state-of-the-art modified Kneser Ney baselines in terms of perplexity on large corpora as well as on BLEU score in a downstream machine translation task.
Predicting the NFL using Twitter
Oct 25, 2013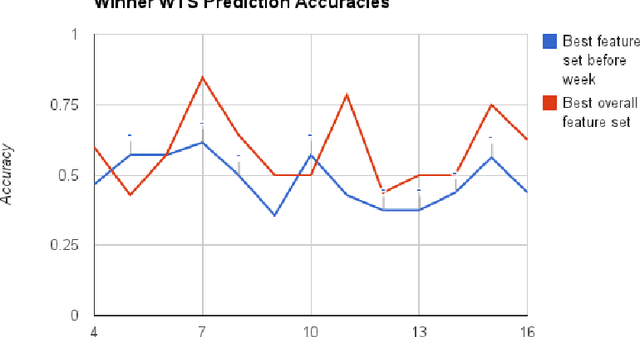
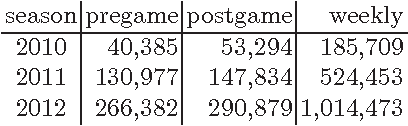
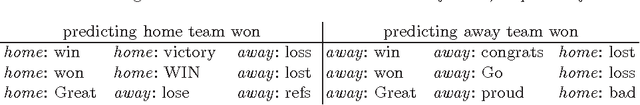
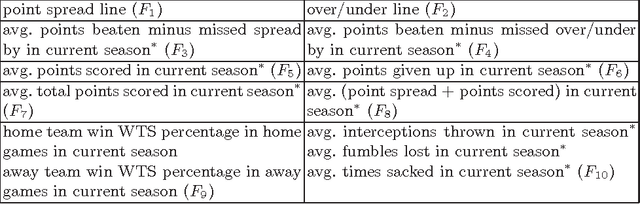
We study the relationship between social media output and National Football League (NFL) games, using a dataset containing messages from Twitter and NFL game statistics. Specifically, we consider tweets pertaining to specific teams and games in the NFL season and use them alongside statistical game data to build predictive models for future game outcomes (which team will win?) and sports betting outcomes (which team will win with the point spread? will the total points be over/under the line?). We experiment with several feature sets and find that simple features using large volumes of tweets can match or exceed the performance of more traditional features that use game statistics.
Minimum Error Rate Training and the Convex Hull Semiring
Jul 13, 2013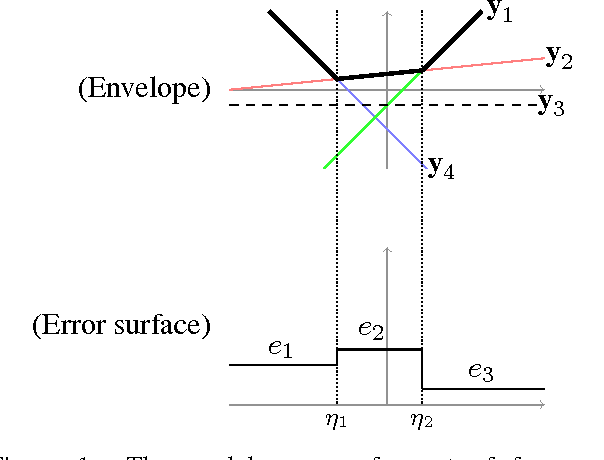
We describe the line search used in the minimum error rate training algorithm MERT as the "inside score" of a weighted proof forest under a semiring defined in terms of well-understood operations from computational geometry. This conception leads to a straightforward complexity analysis of the dynamic programming MERT algorithms of Macherey et al. (2008) and Kumar et al. (2009) and practical approaches to implementation.