Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA framework for (under)specifying dependency syntax without overloading annotators
Jun 15, 2013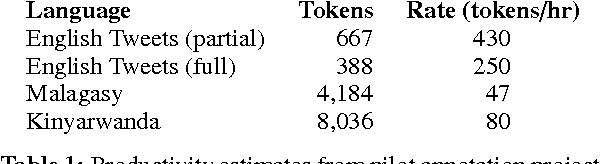

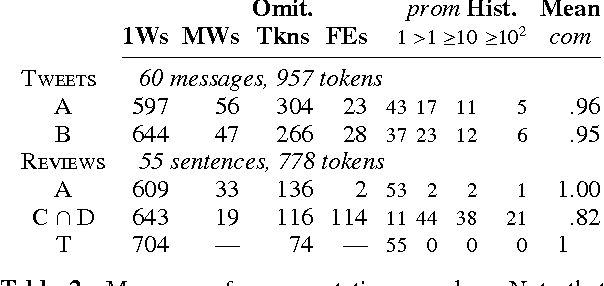
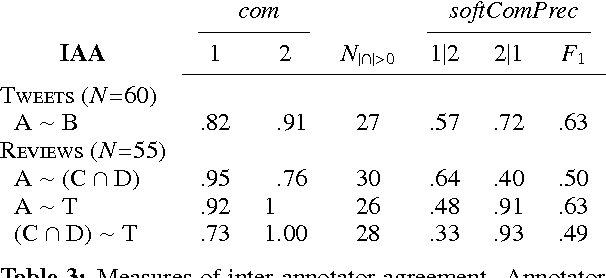
We introduce a framework for lightweight dependency syntax annotation. Our formalism builds upon the typical representation for unlabeled dependencies, permitting a simple notation and annotation workflow. Moreover, the formalism encourages annotators to underspecify parts of the syntax if doing so would streamline the annotation process. We demonstrate the efficacy of this annotation on three languages and develop algorithms to evaluate and compare underspecified annotations.
* This is an expanded version of a paper appearing in Proceedings of
the 7th Linguistic Annotation Workshop & Interoperability with Discourse,
Sofia, Bulgaria, August 8-9, 2013
Via