 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaitSnippet: Gait Recognition Beyond Unordered Sets and Ordered Sequences
Aug 11, 2025Recent advancements in gait recognition have significantly enhanced performance by treating silhouettes as either an unordered set or an ordered sequence. However, both set-based and sequence-based approaches exhibit notable limitations. Specifically, set-based methods tend to overlook short-range temporal context for individual frames, while sequence-based methods struggle to capture long-range temporal dependencies effectively. To address these challenges, we draw inspiration from human identification and propose a new perspective that conceptualizes human gait as a composition of individualized actions. Each action is represented by a series of frames, randomly selected from a continuous segment of the sequence, which we term a snippet. Fundamentally, the collection of snippets for a given sequence enables the incorporation of multi-scale temporal context, facilitating more comprehensive gait feature learning. Moreover, we introduce a non-trivial solution for snippet-based gait recognition, focusing on Snippet Sampling and Snippet Modeling as key components. Extensive experiments on four widely-used gait datasets validate the effectiveness of our proposed approach and, more importantly, highlight the potential of gait snippets. For instance, our method achieves the rank-1 accuracy of 77.5% on Gait3D and 81.7% on GREW using a 2D convolution-based backbone.
Perceptual Compressive Sensing
Aug 27, 2018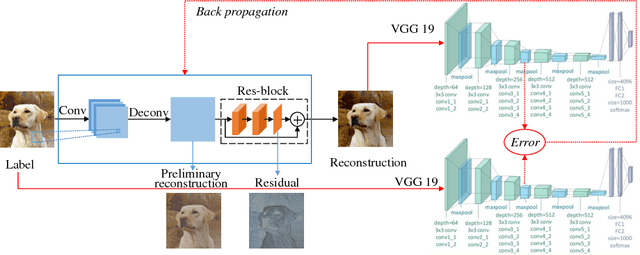
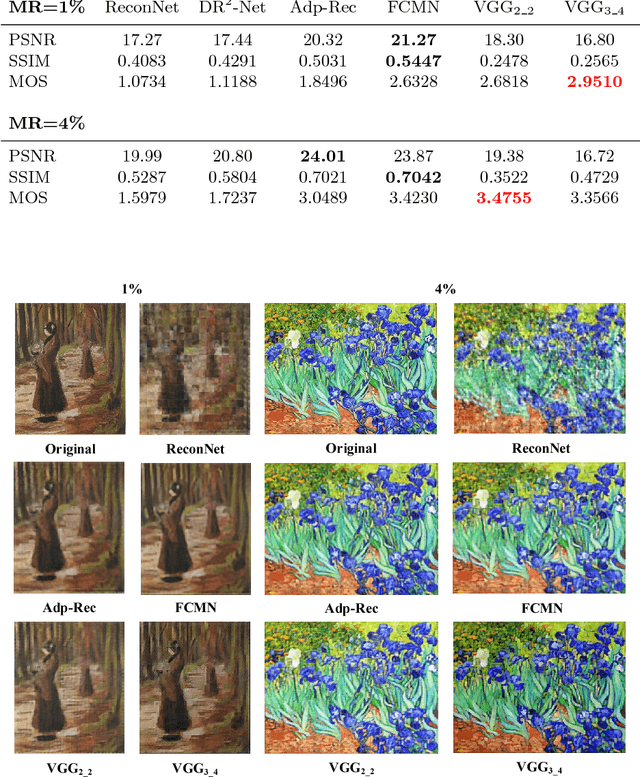


Compressive sensing (CS) works to acquire measurements at sub-Nyquist rate and recover the scene images. Existing CS methods always recover the scene images in pixel level. This causes the smoothness of recovered images and lack of structure information, especially at a low measurement rate. To overcome this drawback, in this paper, we propose perceptual CS to obtain high-level structured recovery. Our task no longer focuses on pixel level. Instead, we work to make a better visual effect. In detail, we employ perceptual loss, defined on feature level, to enhance the structure information of the recovered images. Experiments show that our method achieves better visual results with stronger structure information than existing CS methods at the same measurement rate.
Fully Convolutional Measurement Network for Compressive Sensing Image Reconstruction
May 29, 2018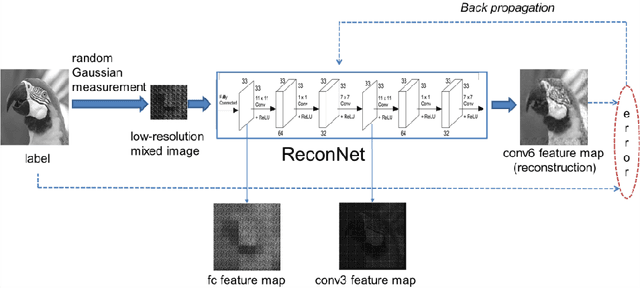
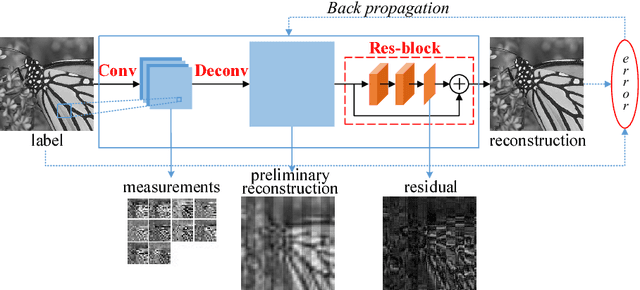
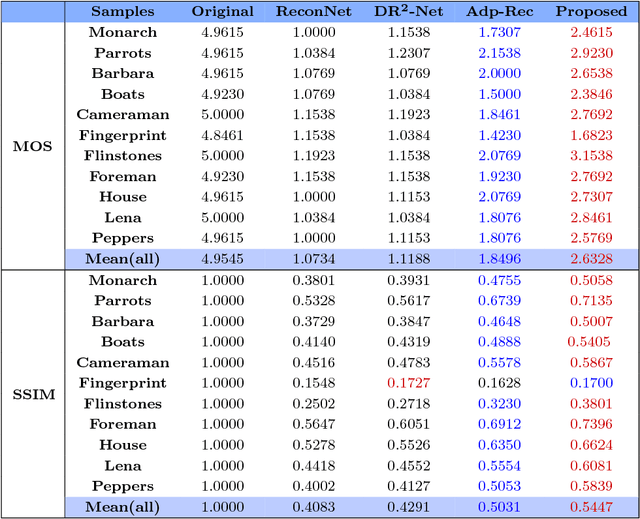
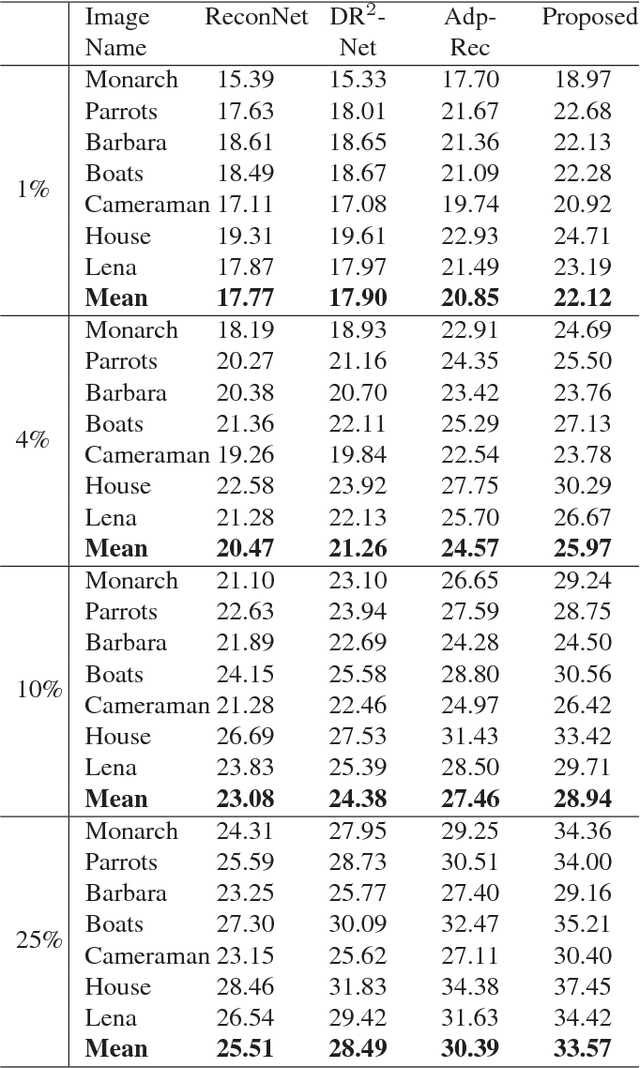
Recently, deep learning methods have made a significant improvement in compressive sensing image reconstruction task. In the existing methods, the scene is measured block by block due to the high computational complexity. This results in block-effect of the recovered images. In this paper, we propose a fully convolutional measurement network, where the scene is measured as a whole. The proposed method powerfully removes the block-effect since the structure information of scene images is preserved. To make the measure more flexible, the measurement and the recovery parts are jointly trained. From the experiments, it is shown that the results by the proposed method outperforms those by the existing methods in PSNR, SSIM, and visual effect.
Full Image Recover for Block-Based Compressive Sensing
Feb 01, 2018
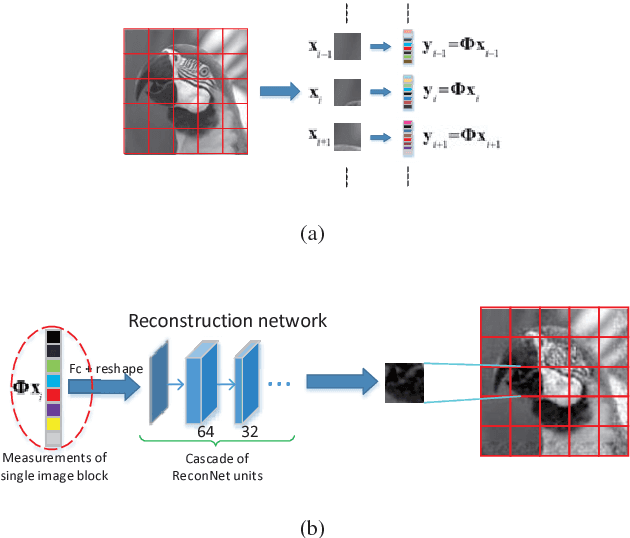
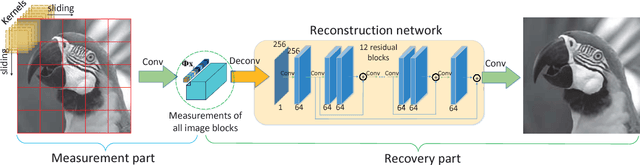
Recent years, compressive sensing (CS) has improved greatly for the application of deep learning technology. For convenience, the input image is usually measured and reconstructed block by block. This usually causes block effect in reconstructed images. In this paper, we present a novel CNN-based network to solve this problem. In measurement part, the input image is adaptively measured block by block to acquire a group of measurements. While in reconstruction part, all the measurements from one image are used to reconstruct the full image at the same time. Different from previous method recovering block by block, the structure information destroyed in measurement part is recovered in our framework. Block effect is removed accordingly. We train the proposed framework by mean square error (MSE) loss function. Experiments show that there is no block effect at all in the proposed method. And our results outperform 1.8 dB compared with existing methods.
Real-Time Illegal Parking Detection System Based on Deep Learning
Oct 05, 2017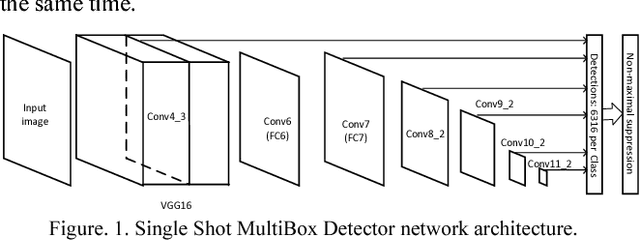
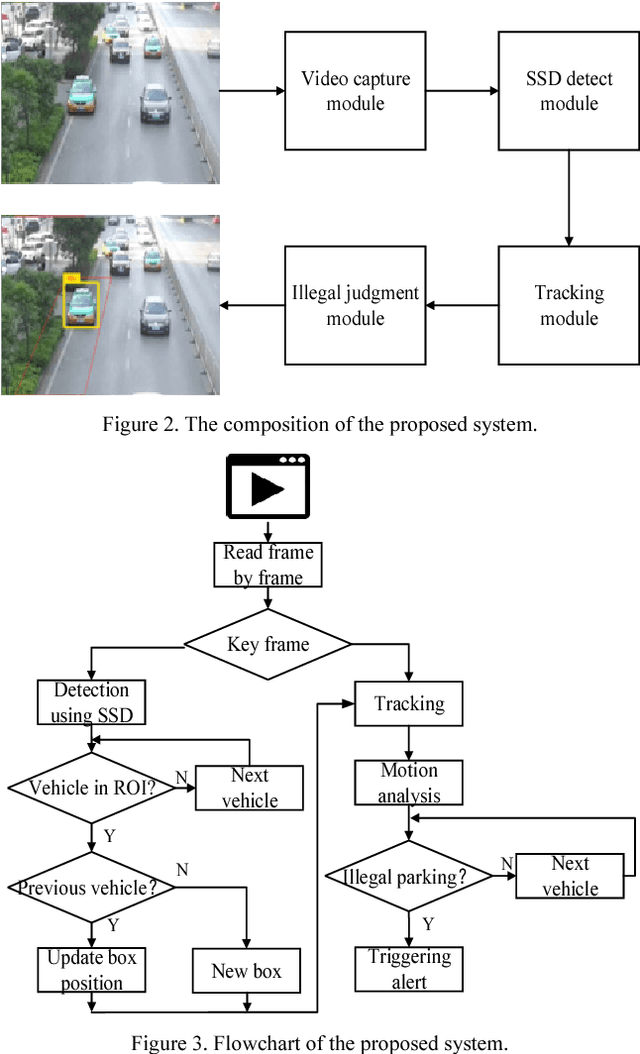
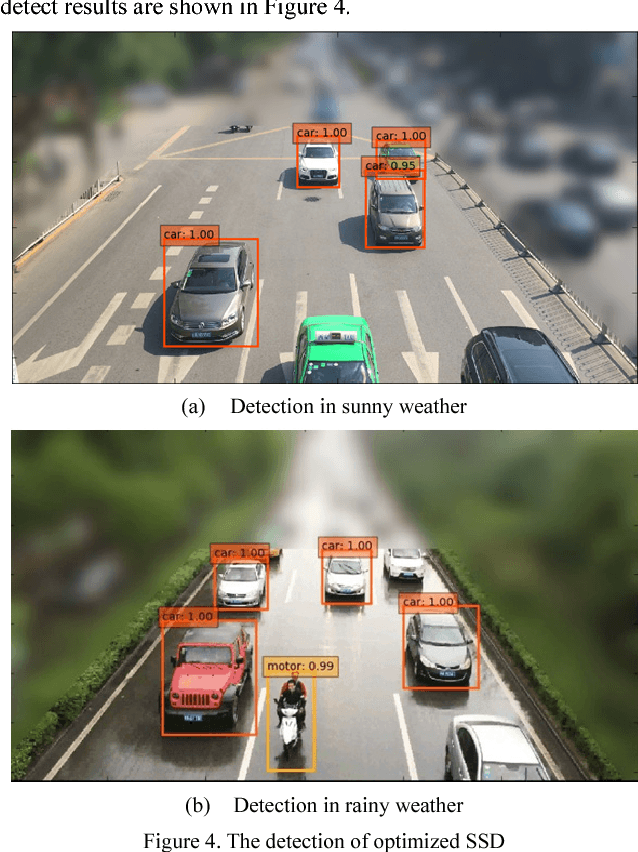
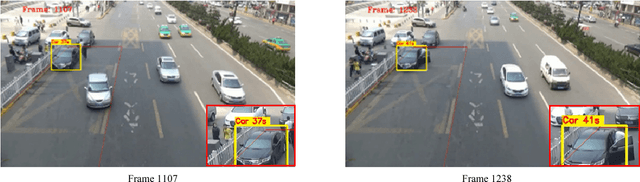
The increasing illegal parking has become more and more serious. Nowadays the methods of detecting illegally parked vehicles are based on background segmentation. However, this method is weakly robust and sensitive to environment. Benefitting from deep learning, this paper proposes a novel illegal vehicle parking detection system. Illegal vehicles captured by camera are firstly located and classified by the famous Single Shot MultiBox Detector (SSD) algorithm. To improve the performance, we propose to optimize SSD by adjusting the aspect ratio of default box to accommodate with our dataset better. After that, a tracking and analysis of movement is adopted to judge the illegal vehicles in the region of interest (ROI). Experiments show that the system can achieve a 99% accuracy and real-time (25FPS) detection with strong robustness in complex environments.
Adaptive Measurement Network for CS Image Reconstruction
Sep 23, 2017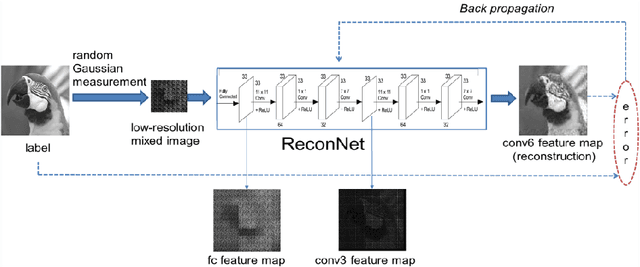
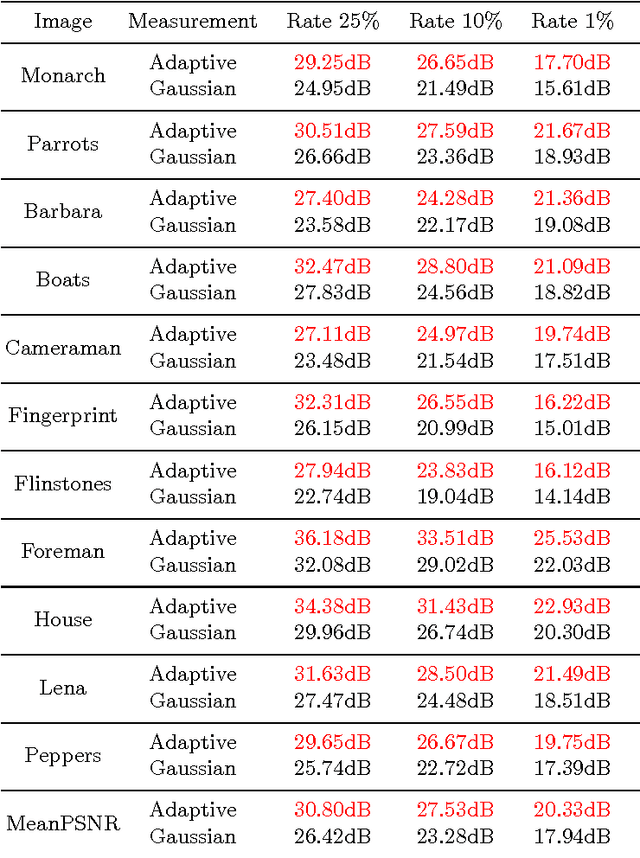

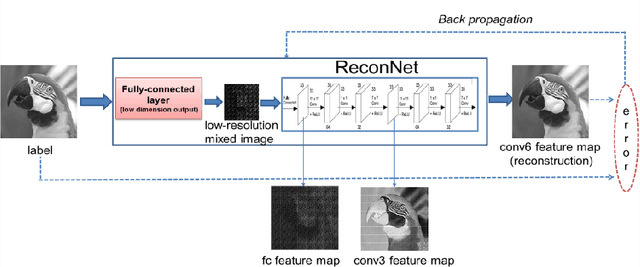
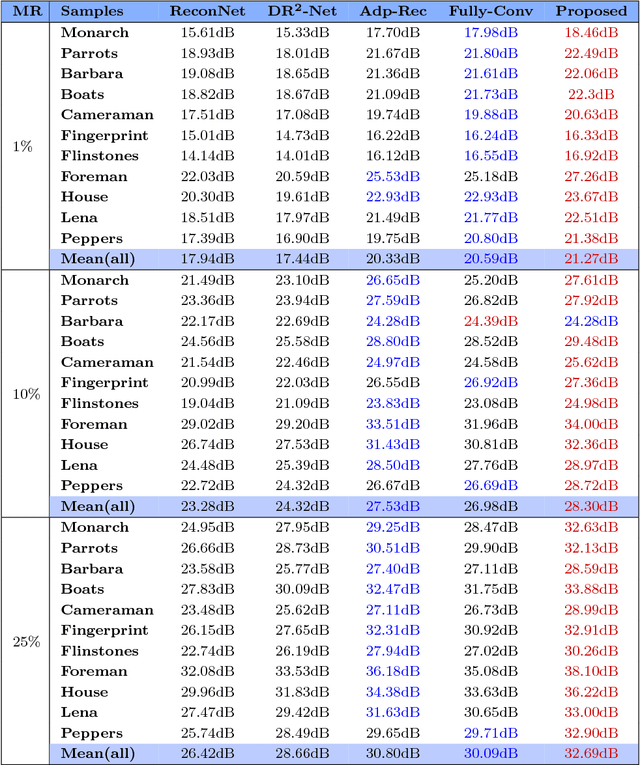
Conventional compressive sensing (CS) reconstruction is very slow for its characteristic of solving an optimization problem. Convolu- tional neural network can realize fast processing while achieving compa- rable results. While CS image recovery with high quality not only de- pends on good reconstruction algorithms, but also good measurements. In this paper, we propose an adaptive measurement network in which measurement is obtained by learning. The new network consists of a fully-connected layer and ReconNet. The fully-connected layer which has low-dimension output acts as measurement. We train the fully-connected layer and ReconNet simultaneously and obtain adaptive measurement. Because the adaptive measurement fits dataset better, in contrast with random Gaussian measurement matrix, under the same measuremen- t rate, it can extract the information of scene more efficiently and get better reconstruction results. Experiments show that the new network outperforms the original one.